
















Here's how to create descriptive table and column names that make DB2 for i easier for end users to navigate
Editor's note: This article is excerpted from chapter 4 of SQL for IBM i: A Database Modernization Guide, by Rafael Victoria-Pereira.
Chapter 3 led us on the first step toward a true database, but it kept most of the hallmarks that make a DB2/400 database very "user-unfriendly": the table and column names are short, in the typical and old-fashioned way of the AS/400. However, end users' demands in regard to data queries have evolved significantly in recent years. The users of our UMADB are particularly data-hungry and are overtaxing the university's IT staff labor resources. This added burden on the IT staff is something that often occurs when you "open up" the database to the end users. The problem is that the database is not always ready to be used by someone not used to short, cryptic names, and this ends up causing additional stress on the IT staff, because it requires additional time and effort to "explain the database" to users and help them navigate the nearly indecipherable table and column names.
The next step is fixing that, by providing longer names that users can relate to. As you probably guessed, this will require changes to the tables' definition. Just as was explained in the previous chapter, this operation can be performed with a DROP TABLE/CREATE TABLE combination.
Let's help the university's IT staff and enhance the Grades table, but first, make sure you duplicate the UMADB_CHP3 library to a new UMADB_CHP4 library. This way you can always "go back" and repeat any of the statements mentioned in this chapter. Back in Chapter 3, all tables were changed to include a primary key and some auditing information. After these changes, PFGRM looks like Table 1.
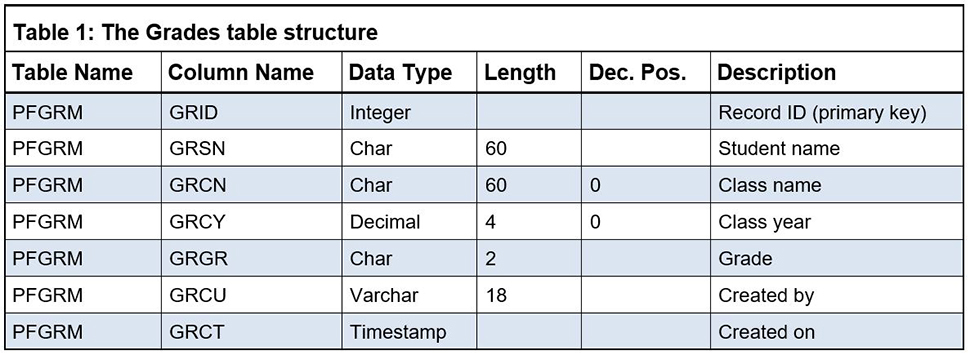
Now we're going to make it a bit more usable for non-IT people. Time for some hands-on reading! When you're ready, type the following statement:
DROP TABLE UMADB_CHP4.PFGRM;
And issue the new CREATE TABLE statement, with longer names for the table and its columns:
CREATE TABLE UMADB_CHP4.TBL_GRADES
(
GRADE_ID FOR COLUMN GRID INTEGER
PRIMARY KEY
GENERATED ALWAYS
AS IDENTITY(START WITH 1
INCREMENT BY 1)
, STUDENT_NAME FOR COLUMN GRSN CHAR(60) CCSID 37 NOT NULL DEFAULT ''
, CLASS_NAME FOR COLUMN GRCN CHAR(60) CCSID 37 NOT NULL DEFAULT ''
, CLASS_YEAR FOR COLUMN GRCY DECIMAL(4, 0) NOT NULL DEFAULT 0
, GRADE FOR COLUMN GRGR CHAR(2) CCSID 37 NOT NULL DEFAULT ''
, CREATED_BY FOR COLUMN GRCU VARCHAR(18) DEFAULT USER
, CREATED_ON FOR COLUMN GRCT TIMESTAMP DEFAULT CURRENT TIMESTAMP
)
RCDFMT PFGRMR
;
Now let's test it:
SELECT * FROM UMADB_CHP4.TBL_GRADES;
You should get no results, because we've just created the table, but the statement shouldn't end in error. Notice, however, that the column names have changed: you now see longer, human-readable column names instead of the cryptic four-letter acronyms. The "magic" is being provided by the FOR COLUMN instruction on each column specification. The syntax is quite simple: instead of simply specifying the column name, as we did before, we're now saying something like "this SQL column has a system name of yyy," where the yyy is the cryptic four-letter name, and the SQL column name is the longer version.
Let's review an example to make this clearer. Look at the student name line:
, STUDENT_NAME FOR COLUMN GRSN CHAR(60) CCSID 37 NOT NULL DEFAULT ''
Here you have the SQL name, STUDENT_NAME, followed by the FOR COLUMN instruction, which in turn is followed by what was already there on the table creation statement from Chapter 3: the "old" column name, GRSN, and the rest of the column definition.
As explained in the previous chapter, in the section that discussed creation of the view, it is possible to access the column using both the "old" and "new" names, which is great because programs can keep using the short names and people can now use the longer ones. Unfortunately, this doesn't apply (not yet, anyway) to the table name: the following statement will produce an error, complaining that the table doesn't exist:
SELECT * FROM UMADB_CHP4.PFGRM;
Why is that? Well, it's because we created an SQL table with the columns of PFGRM, but it has a different name. For all intents and purposes, PFGRM doesn't exist in UMADB_CHP4 - yet. In order to keep all the programs that use PFGRM working and recognizing TBL_GRADES as the PFGRM that they "know," we'll need to create an alias, like this:
CREATE ALIAS UMADB_CHP4.PFGRM FOR UMADB_CHP4.TBL_GRADES;
If the new table name was not a valid system name, this extra step wouldn't be necessary. In this particular case it is, because TBL_GRADES is 10 characters long and doesn't start with a "forbidden" character. After issuing this CREATE ALIAS statement, you should be able to run the SELECT statement using the "old" name of the grades table.
Let's repeat the process for PFSTM, the Students table, so that I can show you how to do the renaming, or more accurately, double naming, process in one step. The current Students table looks like Table 2.
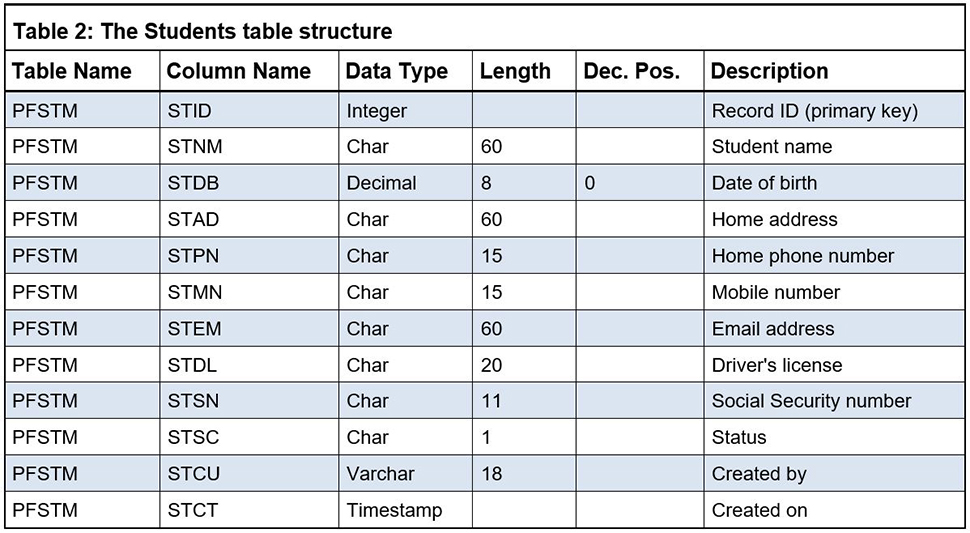
Again, we're going to use DROP TABLE to get rid of the existing PFSTM:
DROP TABLE UMADB_CHP4.PFSTM;
And then we'll issue a modified CREATE TABLE statement to create a table recognizable by its SQL and system names:
CREATE TABLE UMADB_CHP4.TBL_STUDENTS
FOR SYSTEM NAME PFSTM
(
STUDENT_ID FOR COLUMN STID INTEGER
PRIMARY KEY
GENERATED ALWAYS
AS IDENTITY(START WITH 1
INCREMENT BY 1)
, NAME FOR COLUMN STNM CHAR(60) CCSID 37 NOT NULL DEFAULT ''
, DATE_OF_BIRTH FOR COLUMN STDB DECIMAL(8, 0) NOT NULL DEFAULT 0
, HOME_ADDRESS FOR COLUMN STAD CHAR(60) CCSID 37 NOT NULL DEFAULT ''
, HOME_PHONE_NBR FOR COLUMN STPN CHAR(15) CCSID 37 NOT NULL DEFAULT ''
, MOBILE_NBR FOR COLUMN STMN CHAR(15) CCSID 37 NOT NULL DEFAULT ''
, EMAIL_ADDRESS FOR COLUMN STEM CHAR(60) CCSID 37 NOT NULL DEFAULT 'N/A'
, DRIVERS_LICENSE FOR COLUMN STDL CHAR(20) CCSID 37 NOT NULL DEFAULT 'N/A'
, SOCIAL_SEC_NBR FOR COLUMN STSN CHAR(11) CCSID 37 NOT NULL DEFAULT 'N/A'
, STUDENT_STATUS FOR COLUMN STSC CHAR(1) CCSID 37 NOT NULL DEFAULT '1'
, CREATED_BY FOR COLUMN STCU VARCHAR(18) DEFAULT USER
, CREATED_ON FOR COLUMN STCT TIMESTAMP DEFAULT CURRENT TIMESTAMP
)
RCDFMT PFSTMR
;
Here the long names are truly descriptive: SOCIAL_SEC_NBR is a bit abbreviated, but it's far more obvious than STSN. Note that I've added a FOR SYSTEM NAME PFSTM instruction (see the second line of the statement), which removes the need for a separate CREATE ALIAS statement. This is very practical, but not always possible: you can only do this if you use an SQL name that's not a valid system name, as I mentioned before.
This table is particularly interesting because it has some moderately long names that users might or might not want to use. I'm bringing this up to show you that you can refer to short and long names in the same statement; the database engine will figure out to which column you're referring to and show the appropriate data. Here's an example:
SELECT STUDENT_ID
, NAME
, STDB
, HOME_ADDRESS
, STPN
FROM UMADB_CHP4.TBL_STUDENTS
;
As you can see here, I'm using a mix of short and long names in this statement. This can be especially useful when the long names are too long or you're in a hurry to get things done. The RPG programs will still work as before, because they "see" the column system names, which are the same as the "old" DDS field names. You (and your end users) get the best of both worlds with this simple technique, but keep in mind that you need to back up the table's data before performing the DROP operation and restore it again (using an INSERT statement with a nested SELECT, for instance) once you've created the table with the appropriate table and column names.
 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online