









APIs are one of the most powerful tools provided by the IBM i; here is a practical example of using one.
In my previous article, I explained the basics of error reporting when calling APIs. This next installment brings those basics into focus with a real-world illustration that you can experiment with on your own and also use as a practical addition to your development environment.
Object Descriptions and User-Defined Attributes
We start this project by reviewing the concept of the object description. Remember that, in the IBM i operating system, everything is an object. Programs are objects. Files are objects. Commands, data areas, and job descriptions are all objects. And everything that is an object has a number of common attributes that, taken collectively, form the object description. The operating system provides a command to view those attributes, the humble DSPOBJD command. Figure 1 shows the output.
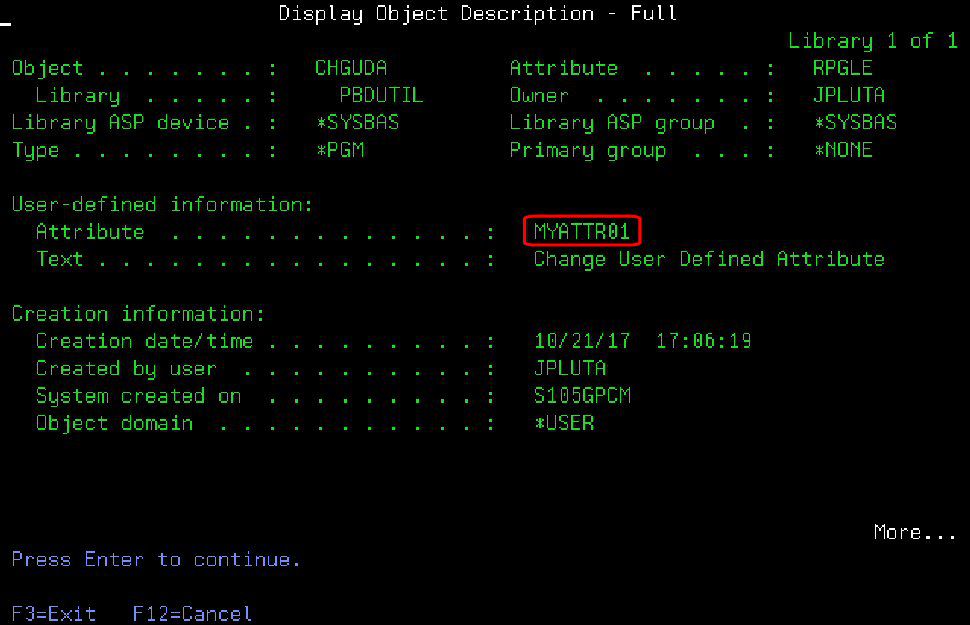
Figure 1: The DSPOBJD command shows basic information about an object.
DSPOBJD shows a lot of object information. The highlighted piece is the user-defined attribute, a 10-character field that is generally blank. This field can be used for anything you need, which can be very useful indeed when you're trying to manage a large system. You can put things like a PTF number in there, or a revision (although for revision I prefer to use a different object field, the eight-character object control level, or OCL). As of version 7.1, you can also use a new 16-character build identifier field.
Today, we're going to take a look at a program that can change the user-defined attribute. In so doing, we're going to review how the various API reporting options work in a real-world situation. If you'd like to use the PTF number or build number, this same program can be easily modified to update any of them.
The Program, CHGUDA
The program we're looking at is CHGUDA, which calls the API QLICOBJD. The complete definition of the API can be found on IBM's website here. The program is very simple, although I've made it a bit more complex than it needs to be in order to showcase the various error-handling techniques. You'll be able to select the error-handling mode via the first parameter. The program calls QLICOBJD, so let's take a look at the prototype for that program.
dcl-pr QLICOBJD extpgm;
oLib char(10);
iObjLib char(20) const;
iType char(10) const;
iData like(dsParm) const;
iErr char(1) options(*varsize);
end-pr;
dcl-s wLib char(10);
dcl-ds dsParm;
num int(10) inz(1);
key int(10) inz(9);
len int(10) inz(10);
data char(10);
end-ds;
The prototype is relatively simple. The only unusual piece is the first parameter, which is an output field. If you specify a special value for the library name (such as *LIBL), then this parameter will show you the library where the object was found. It's a nice feature. After that, the parameters are pretty straightforward. In the IBM i, objects are identified by two components: the qualified object name and the object type. As is usual in the IBM i APIs, the qualified object name (the iObjLib parameter) is a 20-character field in which the first 10 characters are the object name and the second 10 are the library. The object type is next. After that is the iData field, a variable-length record that is defined in the dsParm data structure. Finally, we have the error data structure.
An important point here is that both iData and iErr can have variable formats. Variable-length records like iData are very common in IBM i APIs. They typically start with a 4-byte integer that specifies the number of entries, followed by one or more variable-length entries. For this particular API, each record has a key number (identifying the field to update), a data length, and then the data itself. Those three values—key, len, and data—can be repeated as many times as necessary to update multiple fields.
If you require multiple entries in the variable-length record, you need a more sophisticated approach to defining the data than is shown in this program. We're going to go into that in much more detail in a subsequent article on retrieving journal entries. But since we're updating only one field here, we can simplify the process into the single data structure shown in dsParm. The value num is initialized to 1 because there is only one record. Then the three following values come from the API definition: key is initialized to 9, which specifies the user-defined attribute; len is initialized to 10 because the attribute can accept up to 10 characters; and the data field is an uninitialized 10-character field. The data field is the only uninitialized field because it will contain the value that the user wants to be stored in the user-defined attribute.
dcl-ds ApiThrow;
*n int(10) inz(0);
*n int(10) inz(0);
end-ds;
dcl-ds ApiIgnore qualified;
BytPrv int(10) inz(%size(ApiIgnore));
BytAvl int(10) inz(0);
end-ds;
dcl-ds ApiError qualified;
BytPrv int(10) inz(%size(ApiError));
BytAvl int(10) inz(0);
MsgID char(7);
reserved char(1);
MsgDta char(80);
end-ds;
This section of the program should be familiar if you read the previous article. I've created the three basic error-handling structures. ApiThrow is the most basic and is typically used only when an error is a fatal error. Errors cause a hard halt in the program, just like any other unhandled exception. ApiIgnore is also quite simple and is used when any errors are going to be ignored. You can check for an error; if one occurs, the BytAvl field will be set to a non-zero value. But that's the only information you get. If you need to condition your logic based on the specific error encountered, then you need to use the ApiError structure. Now let's see how this all fits together in the program.
dcl-pi *n;
iMode char(1);
iLib char(10);
iObj char(10);
iType char(10);
iAttr char(10);
end-pi;
dcl-s wLib char(10);
dcl-s wMsg char(50);
data = iAttr;
select;
when iMode = 'T';
QLICOBJD( wLib: iObj+iLib: iType: dsParm: ApiThrow);
when iMode = 'I';
QLICOBJD( wLib: iObj+iLib: iType: dsParm: ApiIgnore);
if ApiIgnore.BytAvl <> 0;
wMsg = %char(ApiIgnore.BytAvl) + ' bytes of error data.';
endif;
when iMode = 'E';
QLICOBJD( wLib: iObj+iLib: iType: dsParm: ApiError);
wMsg = ApiError.MsgID + ' ' + ApiError.MsgDta;
endsl;
if wMsg <> '';
dsply wMsg;
endif;
*inlr = *on;
return;
As you can see, the program is not complicated. The first portion is the procedure interface (if you're unfamiliar with the concept, the procedure interface in the main section of the program performs the same function as the *ENTRY PLIST in an older RPG program). This program has five parameters: the mode (which we'll cover in a moment), the library of the object, the object name, the object type, and finally the value we want placed in the user-defined attribute. You could call it from the command line like this:
CALL CHGUDA PARM(T MYLIB MYPGM *PGM MYATTR02)
After the procedure interface, a couple of work fields are defined. Then the work starts.
Remember that we noted that the data field in the dsParm structure was the only field not pre-initialized. That's because it was intended to send whatever value the user specified to the QLICOBJD API. The next line does just that. And then we begin a big select statement base on the mode. The idea here is that you can experiment with the API error-handling by changing the mode that you send to the program. If you specify T as the first parameter, then any errors cause a hard halt. The halt itself is not particularly informative (it just says that an error occurred calling QLICOBJD), but the joblog will tell you what actually happened.
CALL PGM(CHGUDA) PARM(T MYLIB MYPGM *PGM ATTR002)
Library MYLIB not found.
Function check. CPF9810 unmonitored by CHGUDA at statement 0000000052
instruction X'0000'.
The call to *LIBL/QLICOBJD ended in error (C G D F).
Mode I (selected by specifying I, for Ignore, for the first parameter) uses the ApiIgnore structure, which will ignore the error, but the program will display that an error occurred.
DSPLY 26 bytes of error data.
In this case, you would be checking for an error. For example, you might try to create a data area and assume that any error means it already exists. Then you try to change the data area and use the ApiThrow, so any errors cause a halt.
Finally, you can use mode E (for Error), which shows the error information. While this program simply displays the message ID and message data, you could actually retrieve the formatted message or write the information to disk to a log file for later retrieval. Here's what the result of that call looks like:
DSPLY CPF9810 MYLIB
You may notice that this is the same message ID we saw in the joblog using the T (Throw) mode.
So now that we've gone through all the possible error-handling cases, let's see what happens when we call the program with good parameters.
CALL PGM(CHGUDA) PARM(T PBDUTIL CHGUDA *PGM ATTR002)
No errors are thrown, so the program ran successfully. If I run the DSPOBJD command again, I see this as the user-defined data:
User-defined information:
Attribute . . . . . . . . . . . . . : ATTR002
Text . . . . . . . . . . . . . . . . : Change User Defined Attribute
And that's exactly the result we wanted. So to conclude, this article shows you how to call an API and use the various API error techniques to condition your code. We used the powerful variable-length record format, but we used a very simplified version of it. Next we're going to see how to build up complex parameters using a similar technique.
Have fun with your APIs!

Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including Developing Web 2.0 Applications with EGL for IBM i, E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at
MC Press books written by Joe Pluta available now on the MC Press Bookstore.
 |
Developing Web 2.0 Applications with EGL for IBM i Joe Pluta introduces you to EGL Rich UI and IBM’s Rational Developer for the IBM i platform. List Price $39.95 Now On Sale
|
|
 |
WDSC: Step by Step Discover incredibly powerful WDSC with this easy-to-understand yet thorough introduction. Now On Sale
|
|
 |
Eclipse: Step by Step Quickly get up to speed and productivity using Eclipse. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online