















Continue to explore the many ways to improve application queries to reduce the amount of work DB2 for i has to do to process them.
In the prior tips of this series (1, 2, and 3), there were some general SQL coding guidelines given to avoid giving DB2 for i unnecessary work while doing its job to complete a process or query. This tip continues with more advice from real-world coding encounters.
Use EXISTS Predicate When Appropriate
In the interest of having DB2 for i only do the minimal work required in order to complete a task, the EXISTS predicate is often beneficial.
For the first example, I often see the COUNT aggregate function used in this manner:
IF (
SELECT COUNT(*)
FROM SpecialCharges
WHERE SalesOrderId=@SalesOrderId)>;0 THEN
-- Special charge logic goes here
END IF;
Because the COUNT function is being used to determine if rows exist in the SpecialCharges table (the actual count of matching rows is not used), DB2 wastes time counting all of the rows. In reality, this code is only asking DB2 if any rows exist. The EXISTS predicate is a better coding choice because as soon as it finds a matching row in the search, it bails out and evaluates the predicate as true. It doesn’t have to waste time counting all of the matching rows:
IF EXISTS (
SELECT *
FROM SpecialCharges
WHERE SalesOrderId=@SalesOrderId) THEN
-- Special charge logic goes here
END IF;
Another example of where an EXISTS predicate can improve query performance is in certain JOIN queries that also implement a DISTINCT.
Say you want a list of all purchase order headers from your application that have one or more products on order for over 100 units (and no detail-level information is needed). For this type of work, I often encounter a query that looks like this:
SELECT DISTINCT po.*,SUBTOTAL+TAXAMT+FREIGHT AS PO_TOTAL
FROM PurchaseOrderHeader po
JOIN PurchaseOrderDetail pod ON pod.PurchaseOrderID=po.PurchaseOrderID
AND pod.OrderQty>100
Per the report requirements, a JOIN is done to the PurchaseOrderDetail table to find the products on order for over 100 units. Because a PO header can have multiple products with an order quantity over 100 (and the detail information is not required for the query), a purchase order header with multiple lines (with an order quantity >= 100) will appear multiple times in the result. The SELECT DISTINCT is then used to remove the duplicate rows from the result set.
The only problem with this query is that it may read more rows from PurchaseOrderDetail than needed. Further, because DISTINCT is specified, DB2 has to take the time to sort the entire set of rows so it can weed out the duplicates. DISTINCT is a potentially expensive memory and CPU operation when processing data with a large result set.
Both of these problems are resolved if an EXISTS predicate is used to test for the existence of a PurchaseOrderDetail line with a quantity >=100 units:
SELECT po.*,SUBTOTAL+TAXAMT+FREIGHT AS PO_TOTAL
FROM PurchaseOrderHeader po
WHERE EXISTS (
SELECT *
FROM PurchaseOrderDetail pod
WHERE pod.PurchaseOrderId=po.PurchaseOrderID
AND pod.OrderQty>100)
Figure 1 below shows the original query’s access plan using Visual Explain. The thing to note is the DISTINCT plan step:
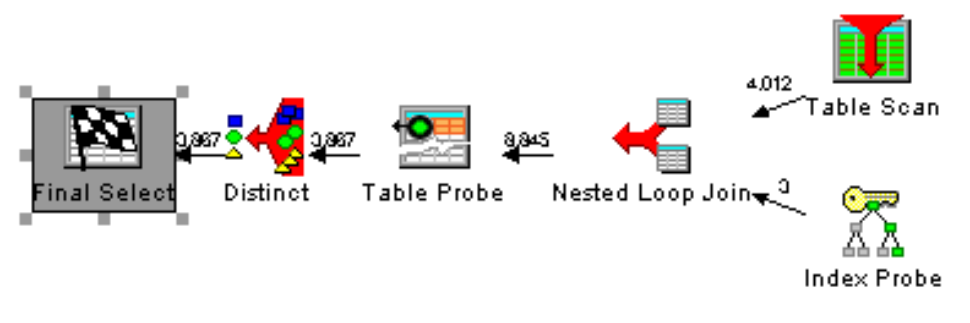
Figure 1: The original query has a DISTINCT plan step that can be removed by rewriting the query. The in/out row counts shown with this step are only estimates. In practice, the actual in/out row counts for this step vary considerably.
Figure 2 shown next shows Visual Explain’s representation of the improved query:
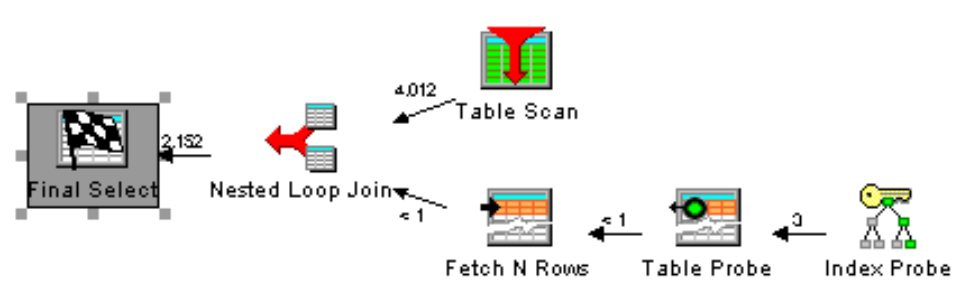
Figure 2: After rewriting the query, the DISTINCT step is gone.
As shown in the example, coding an EXISTS predicate is very similar to coding a JOIN. The benefit of EXISTS over a JOIN is that it doesn’t have to read all the rows that meet the correlation criteria; as soon as it finds a matching row, DB2 moves on to other work. In this case, the DISTINCT plan step can be eliminated from the access plan because the purchase order detail table isn’t involved in a JOIN; therefore, DB2 won’t include duplicate rows that need to be subsequently removed.
Remember the following when deciding whether to use EXISTS:
- EXISTS can be used to indicate a simple binary rows exist/do not exist condition, which may be quicker to process than a COUNT(*) aggregate.
- If you need to test for the existence of a row within a secondary table (with a 1-to-many relationship) and you don’t need to reference data from the table in the SELECT list or later joins, then EXISTS is probably the technique to use.
- The amount of benefit you get from using EXISTS vs. a JOIN has to do with the number of rows being searched and the available indexes (related to the correlation criteria). When run against a smaller result set, the DISTINCT example shown above may run faster.
Be Careful When Invoking Expensive Scalar User-Defined Functions
Scalar user-defined functions (UDFs) are great because they allow developers to reuse business logic. However, when executed thousands or millions of times, they can come with a performance tax. I’ll illustrate this point by describing a bolt-on payroll application I wrote many years ago. This app would dynamically calculate a worker’s hourly pay rate. For simplicity, consider the following time card detail table:
CREATE TABLE TimeCardDetail (
TransDate DATE NOT NULL,
Operation CHAR(10) NOT NULL,
StartTime TIMESTAMP NOT NULL,
EndTime TIMESTAMP,
SecondsWorked INT,
PayFormula VARCHAR(64),
PayRate DEC(19,4))
The hourly pay rate would depend on a variety of factors, including shift, operation, seniority, overtime, number of pieces completed, what was done on a prior day, etc. Each employee would log the operations they did throughout the day on their timecard and, behind the scenes, the database would assemble a string-based formula that would represent the calculation for their pay for that specific operation. A typical formula in column PayFormula would look something like this:
(&ShiftIncentive + &OperationRate) * &OvertimeFactor * &Seconds / 3600.0
At the end of each payroll week, a series of SQL REPLACE functions would substitute the variables in the formula, with actual values such that the formula might look something like this for a person who worked one hour (3600 seconds) on a particular operation:
(.1 + 12.50) * 1 * 3600 / 3600.0
Once the substitutions had been made, a user-defined function (UDF) was invoked to dynamically evaluate the pay formula (i.e., turn the string into a number) and update the PayRate column like this:
UPDATE TimeCardDetail
SET PayRate=EvaluateFormula(PayFormula)
WHERE TransDate BETWEEN @PayPeriodStart AND @PayPeriodEnd
The fact that the EvaluateFormula function could evaluate a simple math expression and return a number was very cool. However, it was also a relatively slow UDF and the evaluation of this function over tens of thousands of timecard detail entries for a given week made the process unbearably slow (30-40 minutes if memory serves). I set out to find a performance improvement.
As it turned out, once the formula variable substitutions were made with their numeric equivalents, I found that many of the formulas were duplicated. For a week, there may have been 70,000 time card detail entries, yet there were only, say, 350 unique formulas. This was because many employees earned the same wage and worked on the same operation for a fixed duration multiple times throughout the week.
Because it is a waste of resources to unnecessarily evaluate the exact same formula multiple times, I found that creating a temp table to hold the unique formulas and the corresponding pay rate evaluations was a good solution to the problem:
-- Create temporary table for holding unique formulas
DECLARE GLOBAL TEMPORARY TABLE FORMULA_EVAL
(
PayFormula VARCHAR(64) NOT NULL,
PayRate DEC(9,4) NOT NULL
);
CREATE UNIQUE INDEX UDX_FORMUAL_EVAL ON SESSION.FORMUAL_EVAL;
-- Find unique formulas and evaluate pay rate
-- ONLY once per formula
INSERT INTO SESSION.FORMULA_EVAL
SELECT PayFormula,EvaluateFormula(PayFormula) AS PayRate
FROM (
SELECT DISTINCT PayFormula
FROM TimeCardDetail
WHERE PayFormula IS NOT NULL
AND TransDate BETWEEN @PayPeriodStart AND @PayPeriodEnd
) Formulas
;
-- Update the time card entry with the evaluated pay rate
-- from the temp table
UPDATE TimeCardDetail
SET PayRate=(SELECT PayRate
FROM SESSION.FORMULA_EVAL f
WHERE f.PayFormula=TimeCardDetail.PayFormula)
WHERE TransDate BETWEEN @PayPeriodStart AND @PayPeriodEnd
It turns out the database server was able to complete this multiple-step process quicker than the single UPDATE statement shown above. Normally, it’s not a good practice to read the same data multiple times as shown above for the TimeCardDetail table. However, the cost of reading the data twice was quicker than evaluating the formula for every single detail entry.
So, in this case, the lesson is that it is important to understand the components of your query and know which components are the most expensive. For this scenario, the trade to minimize the number of UDF invocations in exchange for reading the TimeCardDetail rows twice was well worth the speed improvement. In the end, the time to process payroll was reduced to several minutes, which was acceptable.
Understanding that the math evaluator UDF was costly was only half of the solution. The other half of the solution was understanding the nature of the data. The realization that much of the formula data was duplicated allowed for a different coding approach to update the pay rate. So I’ll offer one more chestnut unrelated to some of the code techniques I’ve shown in this series: it’s important for database administrators and developers to understand the nature and distribution of their data as it often yields a clue for ways to modify code to improve performance.
Keep the Pedal to the Metal
This tip briefly considered two coding scenarios. When looking for a binary (yes/no) answer to the question “Are there corresponding rows in a subquery?”, then the EXISTS and NOT EXISTS predicates often perform better than their alternatives such as a COUNT aggregate or a JOIN.
Likewise, when using scalar UDFs over a large row set, carefully consider the cumulative time DB2 has to spend invoking the function. When a UDF is used as a column expression in a SELECT list, a query that returns 500K rows will have to invoke the UDF 500K times, which can add considerable time to the query. In a case such as this, it may be necessary to identify a way to reduce the query cost. One possible solution, as discussed in the above example, is to run the UDF only the minimal number of times necessary to calculate the required results for all rows.
References
DB2 for i Optimization Strategies, Part 1
DB2 for i Optimization Strategies, Part 2
DB2 for i Optimization Strategies, Part 3
 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online