









Last time, we talked about ice cream, but the story is not so sweet this time. Actually, these two SQL statements can make your stomach cramp.
Here are a few tips on how to use the UPDATE and DELETE statements properly.
Data Adjustments with UPDATE
“Data adjustments” is a nice euphemism for those times when you have to get your hands dirty changing data at a very low level. A lot of programmers I know use DFU exclusively for these tasks, but I prefer to use SQL. The UPDATE instruction allows multiple, finely targeted, and reproducible changes to a group of records, while DFU can act upon only one record at a time. This flexibility is often the reason some people don’t like to use UPDATE: If you aren’t careful, you might end up updating more than you wanted to (or the whole table) with one incorrect UPDATE statement. That’s why I always follow a methodology for my updates:
- Run a SELECT with the UPDATE record selection conditions in the WHERE clause.
- Double-check the SET clause either visually, if it’s a simple change, or on the SELECT column list of a SELECT statement.
- Run the UPDATE statement.
- Extra step: If there’s a risk of something going wrong with a large UPDATE, perform it under commitment control.
Let’s see this in action with an example from our sample database. In the previous TechTip, I inserted two new teachers into the Teachers table, Max Planck and Albert Einstein. However, the original data had a typo. The teacher rank was incorrect; the teacher rank of these two records currently reads “Profesor Emeritus” instead of “Professor Emeritus” (note the misspelling of “professor”). Oops. Let’s correct that mistake, following the steps mentioned before:
SELECT TENM
, TETR
FROM UMADB_CHP2.PFTEM
WHERE TENM in ('Plank, Max', 'Einstein, Albert')
;
In this case, the change is minimal, and a visual check suffices, so I’m ready to run the UPDATE:
UPDATE UMADB_CHP2.PFTEM
SET TETR = 'Professor Emeritus'
WHERE TENM in ('Plank, Max', 'Einstein, Albert')
;
You can also use UPDATE in slightly more complex scenarios, such as updating multiple columns at once or even using the current value of a column to calculate its new value. For instance, let’s say the university wants to cut the teachers’ salaries by 10 percent. With a single UPDATE statement, you can enforce this (probably unpopular) decision:
UPDATE UMADB_CHP2.PFTEM
SET TESA = TESA * 0.9
WHERE TESC = '1'
;
Note that, in this case, I’m only updating the active records (TESC = '1'). Always make sure that your updates target the right records!
As I said before, it’s possible to update multiple columns at once and even use the same column as the updater and the updated. For instance, you can update column A with the value of column B and, in the same statement, also update the value of column B with something else. You just need to carefully pick the order of the changes in the SET clause, as they’ll be executed by the order in which you write them. Here’s a generic example:
UPDATE TABLE_XX
SET COL_A = COL_B, COL_B = 0
WHERE COL_X = '123'
;
I’ll come back to the UPDATE instruction to share a few tricks later in the series. Now it’s time to discuss the last DML instruction of this recap: DELETE.
DELETE: A Blessing and a Curse
I’m one of those programmers who doesn’t like to (permanently) get rid of information. I’m not a hoarder; I just know that when someone asks me to delete something from a database, there’s a good chance that, at some point in the future, they’ll want that piece of data back. So I’m a big fan of soft delete: keeping the information exactly where it was but with a different status to indicate that it’s been “deleted” (or inactivated, if you will), thus indicating that it shouldn’t be used by the application. However, there are times when you really have to get rid of stuff. For those situations, I still prefer a controlled way of deleting information. All of this to tell you a bit more about the DELETE instruction.
I assume that you know the basic syntax of DELETE and that you’ve used it before to clear a table with the classic DELETE FROM <table_name>. However, I can’t stress enough that you should be extremely careful when you use DELETE. There is no undo. And if you forget the WHERE clause or make a mistake in it, you run the risk of clearing the entire table, just like a CLRPFM CL command would! That’s why I consider the DELETE both a blessing and a curse: It can save you a lot of time or cost you a lot of time, depending on how you use it. Just as with an UPDATE statement, I heartily recommend that you try a SELECT statement using the WHERE clause before you do a DELETE, just to make sure it works like you expect it to. In other words, the same methodology I mentioned before applies here:
- Run a SELECT with the DELETE record selection conditions in the WHERE clause.
- Double-check everything before actually running the DELETE statement.
- Run the DELETE statement (and pray you didn’t botch it because there’s no way back—except for restoring a backup, if you have one).
- Extra step: If there’s a risk of something going wrong with a large DELETE, perform it under commitment control.
Here’s an example of a controlled delete, which will also use all the other SQL instructions discussed in this recap. Let’s say I want to reuse the temporary Teacher table mentioned before, PFTEMP_TEM, for enrolling additional teachers, and one of them will also teach Advanced Quantum Mechanics and is from Germany, like Professor Max Planck. I could simply clear the table by using a CLRPFM CL command or a DELETE statement without a WHERE clause and then insert the new data. However, because there are no unique IDs in the table, I can reuse the good professor’s record and type a little less. In other words, I can update an existing record and save some time. So, here’s what I’m going to do:
1. Delete everything from the PFTEMP_TEM table except Professor Max Planck’s record:
DELETE
FROM UMADB_CHP2.PFTEMP_TEM
WHERE TENM <> 'Plank, Max'
;
2. Insert the new teachers’ records (I’ll just insert one, for brevity’s sake):
INSERT INTO UMADB_CHP2.PFTEMP_TEM
(TENM, TETR, TEDB, TEAD , TEPN, TEMN,
TEEM, TEDL, TESN, TEST, TESA)
VALUES(
'Feynman, Richard'
, 'Professor Emeritus'
, 19180511
, 'USA'
, 'N/A'
, 'N/A'
, 'N/A'
, 'N/A'
, 'N/A'
, 'Quantum Electrodynamics'
, 100000.0
)
;
3. Update Professor Max Planck’s record with the necessary changes:
UPDATE UMADB_CHP2.PFTEMP_TEM
SET TENM = 'Schrodinger, Erwin'
, TETR = 'Professor Emeritus'
, TEDB = 18870812
WHERE TENM = 'Plank, Max'
;
4. Finally, insert the new data into the Teachers table:
INSERT INTO UMADB_CHP2.PFTEM
SELECT TMP.*, '1'
FROM UMADB_CHP2.PFTEMP_TEM TMP
;
And that’s the end of this sub-series on DML recap! Here’s what we covered:
- I showed a few tricks you can use on WHERE clauses, like the BETWEEN and IN predicates. These can help clarify and simplify future maintenance of complex SQL instructions. I also mentioned how to use the NOT operator and provided a couple of examples in the same TechTip.
- I explained how you can join tables (in a two part article) and what the implications of those joins are in the output data. Particularly relevant to this topic is Figure 3 of the Part 2 article, which provides an overview of the join types.
- There are a few handy functions to perform the most basic data aggregation operations: COUNT, SUM, calculate the AVeraGe and find the MINimum and MAXimum values of a column (I’ve written the names of the functions in uppercase, for clarity).
- Some of these operations produce unexpected (let’s called them “over-precise”) results that don’t sit well with the end user, and there’s a nice function to change the data type of a piece of data into another type: the CAST function.
- It’s possible to use the aggregation functions with non-aggregated data, as long as you use the GROUP BY clause.
- There are two “flavors” of UPDATE as well as the “strawberry-flavored UPDATE” used to insert multiple records at once.
- Update multiple columns with one statement and even use a column to update another, while changing the first column’s contents on the same update.
- Safely use the UPDATE statement by using a simple methodology.
- Finally, apply that same methodology to the DELETE instruction and avoid wasting time cleaning up messes that could have been avoided.

Rafael Victória-Pereira has more than 20 years of IBM i experience as a programmer, analyst, and manager. Over that period, he has been an active voice in the IBM i community, encouraging and helping programmers transition to ILE and free-format RPG. Rafael has written more than 100 technical articles about topics ranging from interfaces (the topic for his first book, Flexible Input, Dazzling Output with IBM i) to modern RPG and SQL in his popular RPG Academy and SQL 101 series on mcpressonline.com and in his books Evolve Your RPG Coding and SQL for IBM i: A Database Modernization Guide. Rafael writes in an easy-to-read, practical style that is highly popular with his audience of IBM technology professionals.
Rafael is the Deputy IT Director - Infrastructures and Services at the Luis Simões Group in Portugal. His areas of expertise include programming in the IBM i native languages (RPG, CL, and DB2 SQL) and in "modern" programming languages, such as Java, C#, and Python, as well as project management and consultancy.
MC Press books written by Rafael Victória-Pereira available now on the MC Press Bookstore.
 |
Evolve Your RPG Coding: Move from OPM to ILE...and Beyond Transition to modern RPG programming with this step-by-step guide through ILE and free-format RPG, SQL, and modernization techniques. List Price $79.95 Now On Sale
|
|
 |
Flexible Input, Dazzling Output with IBM i Uncover easier, more flexible ways to get data into your system, plus some methods for exporting and presenting the vital business data it contains. Now On Sale
|
|
 |
SQL for IBM i: A Database Modernization Guide Learn how to use SQL’s capabilities to modernize and enhance your IBM i database. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn: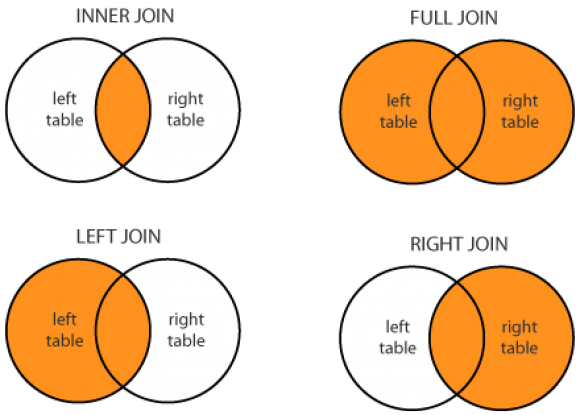{kind=link}
LATEST COMMENTS
MC Press Online