









Sometimes you need to store large pieces of repetitive data that have no natural key, and identities make that easy.
I recently needed to analyze ODBC access to company data. Several techniques exist to track this sort of activity. Perhaps the most thorough is to use exit points; Carol Woodbury wrote an excellent introductory article on the topic. However, for this purpose I considered exit points to be a little too intrusive; installing an exit point, while straightforward, still requires a bit of forethought. Instead, I thought I'd take advantage of a simpler concept: I spin through the active jobs to see which jobs are currently executing SQL statements and then log those statements.
Over a series of days, I put together a small utility that would do just that. In so doing, I was able to use several concepts, some of which you might find useful. First, I created my tables entirely in DDL and made use of the concept of identity columns. They're simple and powerful, but using them in RPG requires a little practice. I also combined RLA and SQL in the same program, a technique I find very convenient. Finally, I used an SQL cursor over a DB2 service, and more specifically a table function. This isn't something you run into a lot, but IBM seems to be doing more and more of the table functions, so it's probably a skill we all need to be comfortable with.
This article is the first of a brief series of articles that will walk you through the entire utility that I developed, line by line. I hope you enjoy it.
The Data Model
The business requirement was to provide forensic analysis of ODBC access from a series of homegrown applications running in thick clients on PCs and also from our BI packages. We needed to track not only the audit information (such as the user, job, and timestamp), but also the actual statement that was being run as well. The problem is that many large statements were being run over and over again, some of them hundreds of times a day. If I just dumped that raw data to a file, I'd end with gigabytes of data very quickly. Instead, I had to design a more-compact database solution. What I came up with was fairly simple:
- One file contains a list of unique SQL statements.
- A second file contains a list of jobs executing those statements.
It's a little more complex than that, but not much. I'll walk you through all the pieces. Let's start with the file that contains the SQL statements themselves. For this purpose, I created the file SQLSTM, and it has just two fields: a unique ID and the SQL statement. I did some initial analysis, and I found about 1000 unique statements in two months. Consequently, I set up the ID field to be a 5-digit decimal field, which should last over a hundred months. And I can easily bump that field up if suddenly we start getting a whole lot of new SQL statements. I also chose for expediency’s sake to limit the SQL statement length to 500 characters. We have quite a few that are longer than that, so I may want to rethink my position. Since there are only 1000 records so far, it wouldn't hurt to expand that length quite a bit. Your needs may vary, of course.
The second file has a little more to it; it's meant to hold all the information I need to analyze the actual ODBC access. To start, I had to identify the key fields I wanted to use for the analysis. In my case, the fields include the fully qualified job name, the current user ID, and the IP address. The job name is the name of the QZDASOINIT job that is servicing the ODBC request. Since that typically is running under a generic user profile and swapping profiles under the covers, I also needed the current user ID. Finally, I also want to know which device on the network is executing the request, so I need to include the IP address of the requestor. Together, these three provided me the key information I needed.
Next, I had to identify the data points we needed to track. I wanted some job information such as the total CPU and disk I/O being used by the server job, as well as the number of times the individual statements were being run. But I didn't want to just keep repeating the same data over and over, so I have a counter in the record and I do a standard tracking logic: chain with the key fields, and if a record is found, bump the counter; otherwise, write a new record. You probably realize that the job totals won't be normalized, since one server job will process many statements, but that's not a major point. I'm just including those numbers for an order-of-magnitude view. This helps me identify the servers that are most used, and then I can go back and do some more in-depth analysis.
Here's a graphic depiction of the data model showing the two files, one very simple and one a little (but not much) more complex.
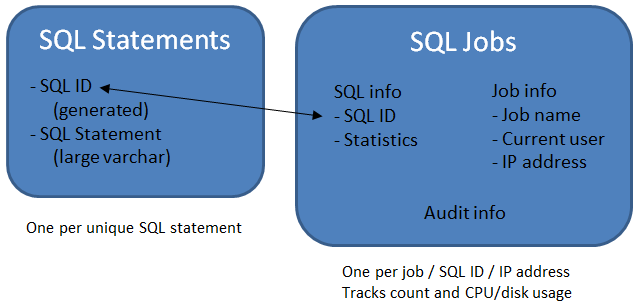
Figure 1: The entire data model consists of two files, one for the SQL statements and one to collect usage.
As explained, the first file stores the actual SQL statements. Whenever I encounter a new SQL statement, I add it to this file. The SQL ID field is the key to the file, and that ID is used in the second file, the SQL jobs file, to link back to the actual SQL. This second file records every time a job uses an SQL statement. I track that information by the fully qualified job (this would be the ODBC server job), the user profile the request is running under, and the IP address the request came from. Combine that with the SQL ID for the unique key. That leads to a lot of records (some quarter million of them at this point). Even at 500 characters, that would be 100MB of additional data.
And I'm finding that 500 characters is a little skimpy; about 15 percent of my SQL statements are longer than 500 characters, and the utility would probably benefit from a longer SQL statement capture size. Because I've decoupled the statement from the statistics, I can expand the statement size significantly with relatively little additional disk space required.
It looks like I designed a successful data model. The question is how to implement it. That's in the next article.

Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including Developing Web 2.0 Applications with EGL for IBM i, E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at
MC Press books written by Joe Pluta available now on the MC Press Bookstore.
 |
Developing Web 2.0 Applications with EGL for IBM i Joe Pluta introduces you to EGL Rich UI and IBM’s Rational Developer for the IBM i platform. List Price $39.95 Now On Sale
|
|
 |
WDSC: Step by Step Discover incredibly powerful WDSC with this easy-to-understand yet thorough introduction. Now On Sale
|
|
 |
Eclipse: Step by Step Quickly get up to speed and productivity using Eclipse. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online