









SQL is phenomenal at sorting, filtering, and summarizing similar data, but business data isn’t always that simple.
Today I’ll introduce you to one of the most helpful techniques I’ve learned recently. It’s not a new syntax (like the MERGE command I wrote about here); it’s just a new application of a couple of things that have been around for a long time. That being the case, I’m going to dive right into the details.
Correlating Similar Data from Multiple Sources
We’re all very familiar with how SQL allows us to analyze data from a file, filtering it and summarizing and so on. Many of us also use the JOIN facility to get data from multiple related files. But at least for me, SQL was never my tool of choice when trying to get similar data from different files. The only way to really do that is through the UNION clause, and even then it requires a bit of finesse when the files contain different business data.
Let me first talk about UNION for just a second. UNION is most easily understood when you’re getting multiple rows out of the same data source in different locations. For example, let’s say you have customer data in the same file but in different libraries (a library on the IBM i equates roughly to a schema in SQL). Maybe one library contains current data (DATALIB) and the other houses archived data (DATAARCH). To get all the customers that start with A from the files in both libraries, you do this:
SELECT * FROM DATALIB.CUSTMAST WHERE CMNAME LIKE 'A%'
UNION
SELECT * FROM DATAARCH.CUSTMAST WHERE CMNAME LIKE 'A%'
ORDER BY CMNAME
I think this particular statement is self-explanatory; it selects all of the records from DATALIB and combines them (via UNION) with all the records in DATAARCH. This makes the very large assumption that the two files are identical in layout and so we can do SELECT * in both. But what if the fields are different? In that case, the query might look something like this:
SELECT DISTINCT POITEM AS Item FROM PURORDS
UNION
SELECT DISTINCT MOITEM AS Item FROM MFGORDS
ORDER BY Item
In this case, we’re getting all the item numbers that are being purchased or manufactured by getting the values from both the PURORDS (purchase orders) and MFGORDS (manufacturing orders) files. The item number has the same characteristics in each file, but the field name is different. I got around that by renaming the field to Item in each SELECT statement. You don’t have to rename the fields when doing a simple query, but if you plan to do anything more complex, such as ordering or filtering by one of those fields or creating a results table, you’ll need to make your names consistent.
Getting Records in Sequence from Multiple Files
In the last line of the query, I ordered the data based on the selected field, which I could do only after renaming the fields consistently. This technique is critical to the task that we’re about to attempt. Let me set the table for what we’re trying to accomplish. One of the big tasks in any business is reconciliation of receipts and invoices on purchased materials. This often falls under the umbrella of “three-way match” because you are matching the purchase order, the receipts, and the invoice. In this specific task, we’re just going to reconcile the purchase receipts to the invoice. Here is the data model for this particular task.
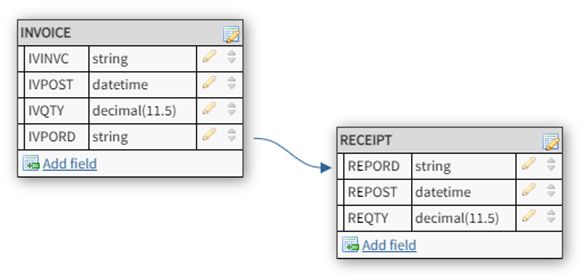
Figure 1: Here’s a simple data model for invoices and PO receipts.
This is a very simplified data model; it ignores basic things like item number, PO price, and so on. I just wanted to show the minimum data required to demonstrate the problem. In the course of normal operations, the business receives inventory to a PO and then gets an invoice from the supplier. They add one or more records to the RECEIPT file and then later add a record to the INVOICE file. To reconcile these, I add up the quantity of all the receipts and then compare that total to the invoiced quantity. And if we had a simple one-to-one where one invoice pays for one PO, I could use a simple JOIN with GROUP BY and I’d be done.
SELECT IVINVC, IVQTY, SUM(REQTY)
FROM INVOICE JOIN RECEIPT ON IVPORD = REPORD
GROUP BY IVINVC, IVQTY HAVING IVQTY <> SUM(REQTY)
However, business is rarely that simple. For this problem, the biggest complication is the concept of a blanket PO, where the PO is defined and then used over and over to make repetitive purchases. It can be anything from raw materials to office supplies, but the concept is the same: the same PO is used to order multiple shipments of goods. The data might look alike this:
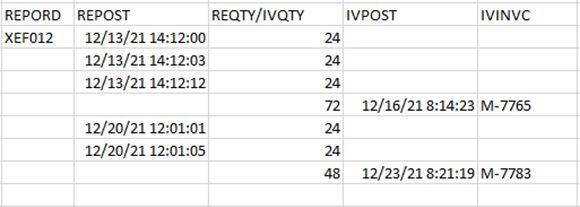
Figure 2: Order receipts and invoices by posted timestamp.
The PO is XEF012, and we show it being used to order goods delivered on the 13th and then again on the 20th. The invoices are entered a couple of days after the receipt. We can’t just use the GROUP BY because we have multiple shipments. Looking at the data, though, something pops out immediately: when ordered by the timestamps in the two different files, all of the receipts for an invoice are followed by the associated invoice. So if I read through both files by timestamp, accumulating the quantity for each receipt, and then compare that to the quantity of the invoice when I hit one, I’ll have my matching condition. But how do I do that? Well, it’s time for the UNION statement! This will get the records in order:
SELECT 'RE', REPORD AS PO, REPOST AS Posted, REQTY FROM RECEIPT
UNION
SELECT 'IV', IVPORD AS PO, IVPOST AS Posted, IVQTY FROM INVOICE
ORDER BY PO, Posted
Note that I had to rename the two fields that I use in the ORDER BY clause so that they are consistent. But the quantity fields don’t need to be renamed, and the type value at the beginning doesn’t have a name at all. Now this is about as far as I can easily go using SQL. I still have the issue of grouping when I have more than one invoice for a PO. There are ways to get around in SQL using partitions, but it requires some syntax that I don’t find particularly easy to write (or read!). Instead, I prefer to write an RPG program to process the records because my code looks pretty simple:
dcl-ds dsD1;
D1_TYPE char(2);
D1_PORD char(10);
D1_POST timestamp;
D1_QTY packed(11:5);
end-ds;
exec sql declare c1 cursor for
SELECT 'RE', REPORD AS PO, REPOST AS Posted, REQTY from RECEIPT
UNION
SELECT 'IV', IVPORD AS PO, IVPOST AS Posted, IVQTY from INVOICE
ORDER BY PO, Posted;
clear wTotal;
exec sql open c1;
exec sql fetch c1 into :dsD1;
dow SQLCOD = *zeros;
if D1_TYPE = 'RE';
wTotal += D1_QTY;
else;
if D1_QTY <> wTotal;
sendError();
endif;
clear wTotal;
endif;
exec sql fetch next from c1 into :dsD1;
enddo;
exec sql close c1;
If you’re not familiar with the embedded SQL syntax in /free RPG, I’ll give you the highlights. The first six lines declare a data structure that will receive the fields from the SQL query. These fields must match the type and order of the fields in the cursor, which follows immediately after. The cursor mirrors the earlier UNION. Next, I clear my accumulator, and then I start my loop. If this is a receipt, I just accumulate it. Otherwise, it’s an invoice. I compare its quantity to the accumulated receipts, and if they don’t match, I send an error. Then I clear the accumulator and continue. Rinse and repeat until no more records in the cursor.
Using Old and New Techniques
The reason I titled this article “Matching Records” is because, if you look at this with the eye of an old-school RPG programmer, you may notice that the technique I’m using is very similar to matching records. I combine the records from multiple files into a single sequence and then read through the records using different logic based on the file ID. In RPG, the program turned on an indicator to tell me which file I was reading. Here, I have to manage my own file indicator (the D1_TYPE field), but it serves the same purpose.
This mashup of multiple tools is why ILE RPG is so very powerful, and in the next article I’ll show you how we can use yet another technique to make this technique even more effective.

Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including Developing Web 2.0 Applications with EGL for IBM i, E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at
MC Press books written by Joe Pluta available now on the MC Press Bookstore.
 |
Developing Web 2.0 Applications with EGL for IBM i Joe Pluta introduces you to EGL Rich UI and IBM’s Rational Developer for the IBM i platform. List Price $39.95 Now On Sale
|
|
 |
WDSC: Step by Step Discover incredibly powerful WDSC with this easy-to-understand yet thorough introduction. Now On Sale
|
|
 |
Eclipse: Step by Step Quickly get up to speed and productivity using Eclipse. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online