








Bring me the frozen cell!" screeched the disheveled scientist. His assistant rambled over to the refrigeration unit and brought out a container with vaporous contents. The scientist opened the container, pulled out its contents, and placed them into a piece of elaborate machinery. He pushed some buttons and twisted a few knobs, and the machine hummed to life. Suddenly, a bright flash of light filled the room, and the scientist screamed, "At last, I have done it! I have achieved my dream!" And there, sitting on a table next to the machine, sat a perfect Elvis.
This may well be the analog world's definition of replication. In the digital world, however, replication is far less flamboyant. The type of replication I'm referring to is database replication, and it may be just the thing to aid you in your quest for the perfect information system.
Database replication is the term used to describe the automatic synchronization of database objects and data between separate database systems. For example, when a record is changed in a table (file), the change will automatically be made in a parallel database on another system. Similarly, additions and deletions of rows (records) will also be reflected in replicated databases.
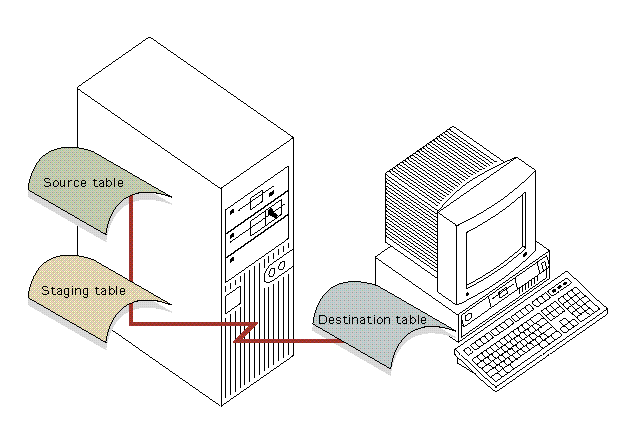
In most replication systems, there are three main elements. The first element is the table that is replicated. This table is referred to as the source table. The second element is a staging table; it holds the changes made to the source table that have not been applied to the third element, which is called the destination table. Destination tables are updated at specific intervals to reflect the data in the source tables. When data is replicated to the destination table, it is removed from the staging table. 1 illustrates the elements of a typical replication system.
In most replication systems, there are three main elements. The first element is the table that is replicated. This table is referred to as the source table. The second element is a staging table; it holds the changes made to the source table that have not been applied to the third element, which is called the destination table. Destination tables are updated at specific intervals to reflect the data in the source tables. When data is replicated to the destination table, it is removed from the staging table. Figure 1 illustrates the elements of a typical replication system.
With replication, it is possible to provide a backup database that can be used if the main database fails. For instance, in a client/server environment, if the computer where the main database resides (the server) suddenly crashes and the tables have been replicated, it would be relatively easy to switch the clients to the server with the replicated database and continue operations.
Another benefit of replication is that it can free your main transaction-processing system from the burden of long-running decision-support queries. If you have a sales database with 10 million records and the VP of sales uses a report writer to spot trends, it might make sense to lessen the performance impact on the main system by giving him a separate database on a different system. The separate database could reside on either the client or another server, depending upon the needs of the organization. With replication, changes to the main database are automatically applied to the other database, ensuring timely and accurate data.
One interesting feature of replication products is the ability to perform summary functions and apply selection criteria to information during replication. For example, you could set up a process that summarizes each new order added to the main system and places it into specific categories for analysis. This process would speed up those huge decision-support queries and reduce replication storage requirements, because the data could be summarized and stored incrementally instead of all at once. You could even set up a process to replicate only certain types of records, perhaps singling out orders for a particular product and replicating them to a client database for detailed analysis.
Another use for replication is to distribute data among multiple sites. To illustrate, suppose your company has a main corporate database and several regional offices. Data from corporate headquarters that applies to all offices, such as product specifications, could be automatically replicated to each regional office. The regional data from each satellite office, such as sales information, could be replicated the other direction to the main corporate headquarters. Then any changes made to orders at regional offices wouldn't get lost in the shuffle, ensuring that everyone is working from the same information and that headquarters has the most current information from each of the regional offices.
Replication products exist for most major database systems including DB2/400. IBM offers a replication product for DB2/400 that replicates relational data between and within the DB2 family of databases (DB2, DB2/2, DB2/6000, and DB2/400). However, numerous third parties have developed products that support replication between DB2 and other databases on non-DB2 systems. These products can bring data from heterogeneous systems into a repository that can be used as a single source for company data reporting. These products can translate data from a proprietary format to a format that's useful to today's data mining tools.
Of course, there are some costs associated with replication. One of the costs is system performance. Recording updates to database tables requires some system overhead. Changes to source replicated tables are written to a staging table. The staging table is periodically read, and the updates are applied to the destination replicated table. Naturally, staging tables and destination replicated tables consume DASD space. The process of applying the changes consumes system resources, and having copies of data in different locations requires increased management.
These costs vary with the level and timeliness of the replication you want to do. You can tune the replication process in several ways to get the cost-to-benefit ratio exactly where you want it. You can set parameters that determine how often the updates are applied, how often the staging files are cleaned up, and with which job priority and description the replication process runs. If you summarize the data as it is replicated, the DASD requirement for the replicated data may decrease. Also, the processing requirements for the decision-support queries will go down, but the processing requirements for each transaction will go up. There are many ways to tune the replication process so that it best serves your organization.
With DASD and processing power becoming cheaper and cheaper, and information availability requirements climbing higher and higher, it is likely we will see replication used more in the future. You may already be doing it at your organization now. If not, you may soon find that replication can help you achieve your IS goals. It is another useful weapon to add to your arsenal of knowledge.
Brian Singleton is an associate technical editor for Midrange Computing. He can be reached by E-mail at
An Introduction to Data Replication
Figure 1: Elements of a Typical Data Replication System

MC Press books written by Brian Singleton available now on the MC Press Bookstore.
 |
i5/OS and Microsoft Office Integration Handbook Harness the power of Microsoft Office while exploiting the iSeries database. List Price $79.95 Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online