









In the last article, rather than accessing the database directly using SQL statements, I wrote an RPG program, accessed via an SQL function, to retrieve customer data. This provides a layer of abstraction between the JSON application (which will eventually communicate with our users) and the database itself. In more technical terms, we separated the model from the view. However, we did that using the old, reliable transport mechanism of a data structure, which isn’t exactly common outside the IBM i world. Today we’ll investigate a modern alternative.
Quick Recap
In the previous version, the RPG program returned a data structure, which the calling Node.js program split apart and used to populate an object. This was meant to emulate how an SQL call returns each row as an object. We replaced the SQL statement with a call to our RPG program (via an SQL function), and then the Node.js application parsed that data based on the layout of the data structure in the RPG program. We ended up with a couple of programs tied to each other by hardcoded positions and lengths:
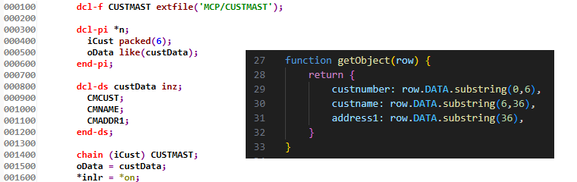
Figure 1: The data structure in the RPG code is split by positions in the Node.js application.
The primary benefit here is that the transaction size is very small, transmitting only the required application data, but it is a potential maintenance headache, especially as field sizes change. Given the much higher bandwidth available to modern applications, they tend to use a semi-structured approach. In the current landscape, the most popular format—especially for APIs—is JSON. SOAP/XML is still being used, but simple JSON is increasingly common.
Changing the Communication
Today we’re going to change our called RPG program. Rather than returning just a single fixed-format data structure containing the customer data, the program will respond in JSON, returning all the orders and lines. This is an interesting exercise, since many RPG programmers tend to think of data as being in records. Nice fixed-length records in keyed files, with one-to-one and one-to-many relationships to other files. Simple and straightforward. The primary architectural nuance in this paradigm is that when I want to get hierarchical data, particularly the one-to-many cases, I make multiple calls, getting one record of data at a time. For example, let’s say I have a CUSTMAST file, an ORDHDR file, and an ORDDTL file. ORDHDR actually has a logical by customer number, ORDHDR01. ORDDTL’s primary key is order number and line. In the simplest multi-platform communication, to get all the order information for a customer, I would start by retrieving the customer data. Next, I would make a request to retrieve the first order record for that customer. Then I’d get the first order line record for the order. I’d retrieve the next order line and repeat that as long as records exist. Then I’d repeat the whole operation for the next order, continuing until I had processed all the orders for that customer.

Figure 2: This is a simplified representation of the hierarchical data for a customer’s orders.
This works reasonably well, especially when the two tiers are on the same network. Latency can become an issue on more-distributed environments, particularly B2B and other types of external communications. In those cases, it’s much more common to see semi-structured hierarchical data, the sort of data best suited for XML or JSON. So let’s start by converting our original RPG program to return a JSON representation of our customer data rather than a simple fixed data structure. We want to return something like this:
{"CMCUST":777777,"CMNAME":"Lucky Gambling Supply","CMADDR1":"777 K St."}
While the programming changes fundamentally alter how the program works, they really aren’t that difficult.

Figure 3. This new version of GETDATA may seem a little busy at first, but it is extremely modifiable.
The business logic of this program is in the getCust procedure, lines 1100 to 2200. All it does is retrieve a customer record and create a standard JSON notation. Line 1700 creates the opening brace for the object, lines 1800 through 2000 add the selected fields, and line 2100 closes the object notation. You’ll probably notice that the first field added includes a third parameter with a value of *on; that controls whether this is the first field or not and indicates to buildElement whether or not to precede the new element with a comma. It may seem that I’ve added a lot of code in the utility procedures in lines 2400 to 4200. Theoretically this could all be done with a few lines of inline code or even a single slightly complex one, but there is a reason for breaking this up, which will become more apparent later. The changes on the Node.js side are even simpler. In fact, only one function changes, getObject:

Figure 4: The modified getObject function simply converts the JSON data from RPG into an object.
Now, rather than extracting data from a fixed data buffer, all this function does is convert the JSON data returned from the RPG program into a valid object. It’s critical that the buffer be formatted correctly, but JSON is a very straightforward and highly standardized format, which is part of the reason I wrote those utility procedures.
Anyway, with these changes in place, here’s our result:
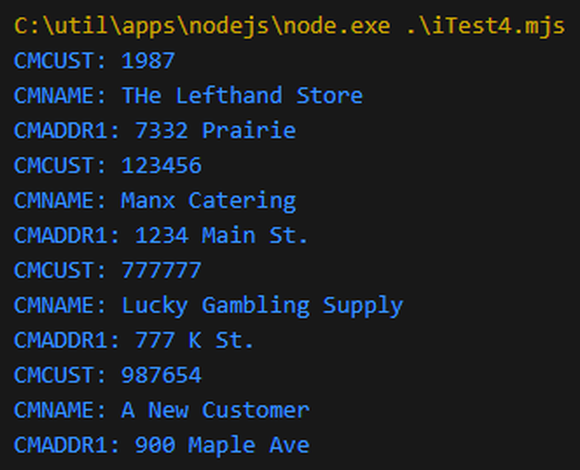
Figure 5: Each customer returns a formatted line, which is converted to an object and then redisplayed.
If you compare our results to those of the previous article, you might think that we actually went back a step, since what we’ve done is go back to using the field names as the element names. But if you look carefully at lines 1800 through 2000 in Figure 3, you can see that we arbitrarily used the field names and that we can really use whatever we want to label each of the elements. So now we’re going to make a bigger change. In our Node.js program, rather than break the data apart, we’re just going to dump the generated object. Here’s the changed code:

Figure 6: The showObject function now just dumps a human-readable dump of the object.

Figure 7: This is the result, with each customer on a single line.
I know, it looks like we’re continuing to regress. Now we’re just showing the data we sent via RPG! Actually, even though that’s what it looks like, the truth is a little more nuanced: we’re converting the JSON data we sent from RPG into a JavaScript object and then dumping the object to the console as JSON. The subtle difference is that if the JSON was wrong, we’d get an error and the program would fail.
Anyway, we have one more step.
Getting Hierarchical
The point to all of this is to be able to send hierarchical data between the tiers. And now that I’ve laid the groundwork, that is going to be very easy. Now, with very little additional code, I am going to send not two, but three levels of data all in a single call. Let’s see how that works. Here are the code changes for the RPG side:

Figure 8: These are the changes to add two more levels of data.
I added the files ORDHDR01 and ORDDTL. In the getCust procedure, I just added another element, although the contents of that element, rather than being just the contents of a field, are instead the results of a call to another procedure. That second procedure, getOrders, loops through the ORDHDR01 file for the specified customer. The trick here is that in addition to adding an object enclosed in braces (lines 3900 and 4200) for each order, I also have to enclose that entire array of orders in square brackets (lines 3300 and 4500). Nothing terribly difficult. This is where I could add any order header data I’d like, such as shipping details or contact information. But I’m keeping this simple and just showing the order number followed by the line detail, which I get by calling another function, getOrderDetails.
The getOrderDetails function is very similar to getOrders. Although it gets its data by looping through the ORDDTL file by order number, it still performs the basic functions of creating an array (with square brackets) and populating that array with objects enclosed in braces. This is the lowest level of the hierarchy, so the function just adds elements from the order line and doesn’t call any other data functions.
You can see that by creating the buildElement function and the quoted function, our business logic is straightforward. When I get time, I might try to create some other building blocks for the array and object definition that would allow the business logic to be even more succinct, but for now I think it works quite well.
Now that we’ve added these levels, what do we see?

Figure 9. This is the multi-level version of the customer order dump.
Most of these customer have no orders, so the first element is simply “orders”:[], which indicate an empty orders array. Customer 777777 does have an order, so its entry is quite long. I’ve broken it down in the code below, formatted a bit for readability.
{ "custNumber":777777,
"custName":"Lucky Gambling Supply",
"addressLine1":"777 K St.",
"orders":[
{ "order":"AO-948223",
"lines":[
{"line":1,"item":"CE333","ordered":15,"unitPrice":53.45},
{"line":2,"item":"P2350","ordered":7,"unitPrice":51.07}
]}]}
I’ll add a couple of additional points. First, I changed the element names to use actual terms in camel case rather than the field names. That’s both to be more standard in the JSON/REST API world and also to emphasize the decoupling of the data from the database. Yes, in this case the data closely mirrors the tables and columns in the relational data, but there is no reason that it has to be that way, and we can really design our communication layer to be whatever we need it to be. Second, the primary issue here is that right now the SQL function and the RPG program beneath it are capped at 500 characters. Obviously, that would be a problem in any but the most limited circumstances. In a real production environment, that data would be much larger, but how large and how to implement it practically is a discussion for another day.
This, though, is an incredibly important first step because now we have hierarchical data that, with very little effort, can populate beautiful and functional user interfaces. And that is our next chapter!

Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including Developing Web 2.0 Applications with EGL for IBM i, E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at
MC Press books written by Joe Pluta available now on the MC Press Bookstore.
 |
Developing Web 2.0 Applications with EGL for IBM i Joe Pluta introduces you to EGL Rich UI and IBM’s Rational Developer for the IBM i platform. List Price $39.95 Now On Sale
|
|
 |
WDSC: Step by Step Discover incredibly powerful WDSC with this easy-to-understand yet thorough introduction. Now On Sale
|
|
 |
Eclipse: Step by Step Quickly get up to speed and productivity using Eclipse. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online