








XML, however, has been an exception to the rule. The majority of the information that I have found--whether it be about Web services, an enhancement to XML Path, or the next version of SOAP--has provided little direction in terms of what role XML should play in an organization. Until I considered writing this article, I had only a rudimentary understanding of XML from an application we developed at the company I work for. A true high-level description of XML and all its associated technologies eluded me.
This series of articles is a result of adding XML "scholastic" knowledge to what I learned hands-on. Articles like these are not for everyone. If you are a programmer who is developing Web services applications, then you know more about XML than I do, and I wouldn't waste your time. If you are beginning to learn about XML, want to know where to use it, and need an understanding of the components of XML, then this is for you.
The first article will explain what XML is. It will walk you through an example XML document and start to define the components of XML. The second article will deal more with the application-to-application (A2A) possibilities that XML provides. And finally, the third article will bring together everything presented and do an entire system walkthrough so that you can see how it all fits together.
What the Hell Is XML?
XML is really many different things. First and foremost, it is a set of conventions that define how a document is structured or marked up. XML documents are plain text and can be read in a text editor. The document is made up of markups that surround information or data in a semi-structured way.
When I say "semi-structured," I mean that the informational structure is up to the author of the XML document, but how the markups are performed is very structured and rigid. Those of you who know a little HTML know that you can have a
(to designate a new paragraph) by itself without a closing tag. In XML, you must always have an opening tag (
) as well as a closing tag (
). If you want just a simple placeholder with no data between the tags, a simple would can be used.Now, in the above example, the
tag does not mean the same thing as it does in HTML. HTML is a presentation protocol that tells Web browsers what to display and how. XML is a presentation protocol too, but it's for data. It cares nothing about how the data will look; it is concerned simply with presenting the data and the relationships within the set of data. The
tag actually means whatever you want it to mean in XML.
To understand more about the presentation of data, it's important to look at why XML was created as a standard. The World Wide Web Consortium (W3C)--the organization responsible for ratifying standards such as HTML--wanted a standard that allowed open, extensible document exchange between any XML-compliant computing devices. Recognizing that the possible scenarios for data exchange could extend beyond their imagination, they decided to let the author of the XML document define the elements, or pieces of data.
If you look at a purchase order, for example, one company may represent freight on board as
If you look at an XML document, it's easy enough to understand. For instance, a row from a comma-delimited file may look like this: 8, 34, Red, 5, 13. Do you know what this may represent? Let's look at it in XML notation. Please note that "white space" or formatting has been inserted to make the XML file more readable. In reality, this XML code should be one continuous line of text.
While this is missing some key ingredients that would make it an actual ticket to a baseball game, it illustrates the point that XML is a means of describing data in a data transport environment. Each element of the ticket is clearly defined.
The first line indicates that this is an XML document, and it identifies the version of XML. This line is optional, but it is highly recommended. I suspect that this was introduced for environments in which there are no file extensions. In the Windows and Intel environments, an XML file would have a file extension of .xml. In the AS/400 or iSeries, there are no file extensions where this identifier line comes into play.
The line
The Gate, Section, Level, Row, and Seat elements are all child elements with the associated data. The
To illustrate different branches in an XML file, look at this XML file that represents two tickets that have adjacent seats:
In this example, you'll notice the addition of the SeatSelection node, which encompasses additional elements. SeatSelection allows multiple seat selections and numbers them sequentially through the attributes Number="1" and Number="2".
In both examples, the last line contains the tag . This tag designates the end of the XML file as the root node is closed out. Adding text or tags after the closing tag will result in an invalid XML document.
One way that you can view XML documents without any coding is to download the Microsoft Core XML Services 4.0. This free download enhances the XML functionality of your Windows operating system. Once you have done this, you can copy and paste the text of my examples into Notepad and save the file with an .xml extension. Once saved, just double-click the file, and Internet Explorer will open it and display a tree-like structure with nodes that can be expanded and collapsed. The following is an illustration of the second example in Internet Explorer.
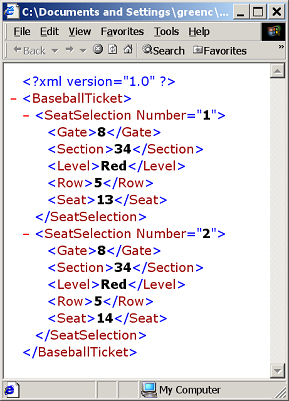
Notice that, at the left of each node (in this case, BaseballTicket and SeatSelection), there is a red minus sign (-). If you click on this, the node will collapse. Once collapsed, a plus sign (+) replaces the minus sign. Click on the plus sign to expand the node.
Subcomponents of an XML Document
Now that we have explored the various aspects of an XML document, we can start to look at the formal markups that can comprise an XML document. There are six markup categories: Elements, Entity References, Comments, Processing Instructions, Marked Sections, and Document Type Declarations.
Elements
Elements are the most common form of markup in an XML document, and I've already shown you several. As stated earlier, an element is comprised of a start tag, occasionally data, and an end tag. The start and end tags can be combined; if so, they would contain the "/>" attribute, which designates the end of the element even though there is no separate ending tag. Here's an example:
The markup Date="2002/09/28" is an attribute of the element.
Entity References
While sounding quite grandiose, an entity reference is very simplistic. It is the act of representing reserved characters in a coded notation. For example, < represents a less-than symbol (<). If you were hand-coding an XML document, you could use
Comments
When you use comments in an XML document, start them with . You can use comments anywhere in your XML document, and you can use any text within your comments except for the literal string --.
Processing Instructions
Processing Instructions (PI) refer to the text that is passed to the application reading the XML document. They have the form . The application looking for PI would reference the PI name, which is a PI target, and then read the data from the PI data section. The one place that I have seen this used is in defining a stylesheet for the XML. A stylesheet presents a view of the XML document, which I will review later in this article.
Marked Sections
Marked sections are also known as CDATA sections, as they are tagged in an XML document as . The section ends with ]]>, and any characters are allowed in this section except for ]]>. You could use this section for a unique calculation formula relating to the data in the XML document. The application reading the XML document would then use that formula once it has extracted the data from the XML document.
Document Type Declarations
Document Type Declarations (or DTD files) are heavily used. They allow you to define the validation that should be used on the XML document. If the XML document references the DTD, then the XML parser performs the validation for you. This saves you the hassle of coding validation routines. I'll talk more about these later.
What Would I Use XML For?
In the beginning stages of e-business, we saw companies selling to consumers in what is called business-to-consumer (B2C). In B2C, consumers browse through online stores and make purchases by providing their credit card information. My first online purchase was a golf shirt from the 1996 Summer Olympics in Atlanta. All told, it cost $80 Canadian after taxes, delivery, duty, and exchange rates!
Once the kinks were ironed out, businesses saw the value of communicating with their partners through the Internet. That spawned business-to-business (B2B), allowing companies to communicate with their supply chain or business customers through a Web interface. The major drawback was that it was a manual process. While the data was available in an MRP/ERP or accounting package, it still had to be manually entered into a Web page.
At this point, the Electronic Data Interchange (EDI) guys started laughing and saying, "We've been doing automated data exchange for years, so why switch?" The problem was that EDI was expensive, it used archaic 9600 bps modems, and only a small percentage of companies used it.
So the application-to-application (A2A) paradigm was formed, allowing applications in one company to talk to applications in another company without user intervention. And XML--with its ability to mark up data in Unicode text for delivery between applications--took center stage. This scares the EDI guys because XML is standards-based and requires no licenses. Also, XML has become very common; college students now graduate with a knowledge of XML, just as they graduated with HTML knowledge five years ago. Microsoft Excel and Access support XML, illustrating that it is a cost-effective solution for small companies.
But A2A is not strictly for companies communicating with each other. Let me tell you about my first experience with XML. We have 50 product testers on our manufacturing floor. They ensure that for every one million units we ship, fewer than 25 are duds. No two testers did the same test and no two testers logged the test results in the same format. Centralization was going to be a large project.
Our original concept was to have each tester connect to a Microsoft SQL Server and insert the results of each product test. This would occur approximately every 30 seconds and would contain the results of the 50 to 300 individual tests that comprise a complete product test.
Performing transactions like this every 30 seconds across 50 testers would be harmful to system performance. The process would require establishing a connection to the server, requesting authentication by the SQL server, submitting the query, awaiting a response from the server, and then tearing down the connection to the server.
Now look at how XML helped this application. Once a tester completes a product test, the tester creates an XML document containing the test results. Creation of a text document is very easy and is completed quickly by any computer. The tester then submits the XML document to a central Web server through a standard HTTP Post command. XML uses the Web as its main transport because of the Web's popularity. A company sending an XML document to another company submits it to the receiving company's Web site. A Web page is created that receives the XML document and processes it as required.
The server accepts this document and acknowledges receipt (notice, no authentication). The connection is closed, and the tester is free to perform the next test. As the next test is performed, the Web server parses through the XML document and then generates and runs the query. Because only one computer is performing the query, a database connection is opened only once, which lowers the overhead of each transaction.
In this scenario, processing time is about one-fifth the time it would be if the tester communicated directly with the SQL Server. This method also uses significantly less bandwidth, which is important because the testers are connected to the network wirelessly.
How Do I Read and Manipulate XML?
While the description of XML thus far may provide some interesting concepts, I would hate to have to get data out of an XML document using RPG or Cobol. The W3C saw this and developed the Document Object Model (DOM). This is a standard set of API calls that allow you to read, manipulate, and create XML documents.
The W3C standardized the DOM object's APIs. The intention was to have a standard set of APIs that you could basically cut and paste between languages. While this is true for the most part, languages have slightly different nuances in how they call APIs, which minimizes code portability.
The APIs (or methods, for OO enthusiasts) provided by DOM are quite extensive. As the requirements and uses of XML extend, new versions of the DOM standard will be released, and software houses will play catch-up in matching the standard with their implementation. If you are a programmer, the best place to go for DOM methods and uses is the W3C Web site.
Microsoft currently provides free XML Core Services (MSXML) 4.0. MSXML is Microsoft's own implementation of the DOM and other XML utilities that are accessible through Visual Basic, Visual Basic Scripting, and any language or application that can access an ActiveX object.
Many other companies also market XML packages that provide the DOM object as well as an alternative to DOM, which is Simple API for XML (SAX). SAX started as an alternative to DOM that was outside of the realm of the W3C and strictly for Java. Since then, it has evolved so that it is supported by many different platforms. And while it may have been simple in the beginning, the jury is still out on whether its simplicity remains. I've spoken with a few developers who feel that DOM is easier to use than SAX, but that is a matter of preference.
The main difference between DOM and SAX is that DOM reads an entire XML document into memory and then builds a tree structure based upon the XML. SAX reads the XML document, and, as it comes across new markups, it throws events to the application using the SAX objects. If the XML file contains a large number of nodes, using DOM may be slower than using SAX, as DOM first reads the entire document in. Before deciding which standard to use, consider the size of the XML documents to be received and the standard your programmers feel more comfortable with.
XML Validation
One of the scariest absolutes about XML documents is that they can be created outside of your control. When you receive them, how do you know they are valid and how can you avoid large amounts of validation coding?
Document Type Definition (DTD) is a component of XML that lets us define how the data in our XML documents are related. It also allows us to dictate how strict to be with the relationships. The DTD can be defined within the XML document, but it's more commonly found in a separate file with the XML file referencing it. If you are setting up an XML exchange with your customers in which they send you purchase orders via XML, the DTD would be stored on your Web server. When your customers create an XML file, they reference that DTD through a Universal Resource Identifier (URI).
When your customers post an XML document to a Web page you designate, the parser that receives the XML reads through it to ensure that it conforms to the DTD. If it does not, it is rejected and you can handle the error as needed. Sending an email or responding with your own XML are common scenarios. The beauty of this is that this functionality is all part of XML. Aside from the DTD file, you write zero lines of code.
The following is a sample DTD relating to the second baseball ticket example.
The first line indicates that the root node is BaseballTicket and that the child node is SeatSelection. The "+" indicates that there must be at least one SeatSelection child node.
The second line indicates that the SeatSelection node consists of Gate, Section, Level, Row, and Seat elements. There's no "+" markup, so these elements must occur once and in this specific order. Other markups include a question mark (?), which indicates that an element must occur once or not at all, and an asterisk (*), which indicates that the content can occur once, many times, or not at all.
The next lines end in (#PCDATA)>, which allow us to stipulate that these elements contain data rather than other elements or entity references. You can visualize that this represents the final branch in a series of branches on a tree.
Typically, you will have the DTD on your Web site. In the XML code, a line such as would be required so that external entities could reference the DTD and validate the XML before they send it to you. By doing this, the XML is validated before you receive it, minimizing the volume of invalid XMLs.
XML Transformation
A simple way of transforming an XML document is to use the Extensible Stylesheet Language (XSL). Similar to Cascading Style Sheets (CSS) in the Web world, XSL takes information from XML and displays it in an HTML or text format. The benefit to using XSL is that you do not have to master the DOM or SAX APIs, you do not need a compiler, and the file is a simple text file.
Two other technologies assist in the transformation. XML Path assists in locating data within an XML document--the path to the data. XML Transformations transforms the XML data into another form. XSL then takes the transformed data and formats it for the end medium (Web, text, etc). All three technologies are commonly referred to as XSL.
The point to remember is that XSL transforms the XML into a new document. It does not validate, execute business logic, or manipulate the original XML document. It simply provides an alternative view of the XML file.
When you double-click on an XML document and Internet Explorer opens up, you are looking at XSL. Internet Explorer comes with a default stylesheet that is used if no stylesheet is specified. If this default XSL were not in place, Internet Explorer would display what looks like one line of text, which is the text of the XML document.
Aside from providing a more aesthetic view of your XML documents, XSL can be used to create any form of text document. For example, if your server receives XML documents at a frequent interval and standard database updates take too long, you could use XSL to create a comma-delimited file that performs a bulk import into a database, which would take less time. Or you could use XSL to create an SQL Query statement that imports the data from the XML into your database.
Until Next Time
In this article, I went through what XML is, where to use it, how to validate it, and how to transform it. This is really just the start. In the next article, I'll start to look at the XML technologies supporting company-to-company or application-to-application communications.
If you would like more information on topics raised here or other XML technologies, I would recommend the following Web sites.
- World Wide Web Consortium (W3C) XML Architecture Domain
- O'Reilly XML.com
- The XML Industry Portal
- Developer News from the XML Community
Chris Green is a Senior Network Support Specialist located in Toronto, Ontario, Canada. He has seven years experience focusing on the iSeries 400 and networking technologies. Utilizing this experience, he has authored over 30 articles and several white papers and has co-authored an IBM Redbook entitled Securing Your AS/400 From Harm on the Internet. For questions or comments, you can email him at
 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online