








One thing that makes SQL such a powerful language is the ability to do statistical analysis and create a summary in a single SQL statement. This can be achieved through the use of aggregate or columnar functions, which allow you to create total- or subtotal-level summaries. Subtotal-level groupings are defined using the GROUP BY clause.
In this TechTip, we'll examine each of the columnar functions supported by DB2 UDB for the iSeries. The table below contains a list of these functions and a brief description of their use.
| SQL Columnar Functions | |
| Function | Description |
| SUM | This function returns the total of the supplied field values within the defined data set. |
| AVG | This function returns an average of the field or value on the supplied parameter over the defined data set. |
| COUNT | This function determines the number of rows within the defined data set. |
| COUNT_BIG | This function also returns the number of rows within the defined data set, but it supports more digits than the standard integer value returned by the COUNT function. |
| MAX | This function returns the maximum value for the field supplied on its parameter within the defined data set. |
| MIN | This function is the opposite of the MAX function. It returns the minimum value within the defined data set. |
| STDDEV_POP, STDEV | These functions return the standard deviation (or the square root of the variance) of the supplied field value within the defined data set. |
| VAR_POP, VARIANCE, VAR | These functions return the variance calculated on the supplied field value within the defined data set. |
The key to using these functions is the GROUP BY clause, which allows you to define the level at which data is to be summarized, based on the fields within your database. It's possible to use columnar functions without a GROUP BY clause, but the results will be a summary of all of the records in the defined data set.
Below is a basic SELECT statement using the GROUP BY clause.
FROM MYDB/SALESHIST
GROUP BY ITEMNO
In this example, a total is returned containing a summary of the fields SLSDLR and SLSQTY for each change in the value of the field ITEMNO. If we remove the GROUP BY clause from this statement, the resulting data will be a summary of the fields SLSDLR and SLSQTY for the entire data set.
The following example uses the SUM() columnar function to create a total of the data in the specified column. This function accepts the field name to be summarized but can also accept calculations, as shown below:
FROM MYDB/ORDERS
WHERE ORDER_NO = 12345
In this example, the field UNIT_PRICE is multiplied by QTY_SOLD for each record read. The value of each of these calculations is summarized over the data set. Note that this data set will include only records in which the value of the field ORDER_NO is equal to 12345. As a result, the summary generated will be only for records matching that condition. The DISTINCT modifier can be added to the function expression to omit duplicate values when summarizing the data.
Similar to the SUM function, the AVG function accepts either a single field or an expression resulting in a numeric value. The resulting data represents an average of the values across the data set. This function also accepts the DISTINCT modifier, which will omit duplicate values within the defined data set. The example below illustrates the use of the AVG function:
FROM MYDB/PAYROLL
GROUP BY EMPNO
This example returns two different average values. The first example returns an average of the value across the entire data set, while the second calculates the average based on distinct values only. This means that if you have a table with payroll information where an employee's pay rate was $9.75 an hour for five weeks, $10.25 an hour for four weeks, and $12.50 an hour for three weeks, the value returned by the first example will be 10.604167, while the second example returns a value of 10.8333.
The COUNT() SQL function returns a value that indicates the number of rows in the defined data set. The value returned by this function is supplied in a large-integer format with a length of no more than 15 digits. The function's single parameter defines the type of count to be given. Below are examples of the three types of values that can be provided to the COUNT function:
FROM MYDB/CUSTOMERS
The first example returns a count of the total number of rows in the defined data set. The second example supplies the field NAME as the function's parameter. This indicates that all rows in which the defined field is not null should be counted. The third example returns a count of the number of distinct values in the field ZIPCODE. In this example, if your table contains 40 total records, of which three have a null value for the NAME field and contain any of the zip codes 18222, 32707, 32771, and 90220, the statement above will return the values 40, 37, and 4, respectively.
The COUNT_BIG function also returns a count of records in the defined record set, but the results supplied by this function can be larger than those supported by the COUNT function. The COUNT_BIG function returns a value with a precision of 31 and 0 decimals.
The MAX and MIN functions retrieve the highest or lowest values respectively within a specified data set. Each of these functions accepts numeric and non-numeric values. The example below illustrates the use of these functions.
FROM MYDB/ORDHEADER
The result set generated by this statement will be the highest and lowest values, respectively, for the field ORDVAL from the table ORDHEADER. These functions allow a user to perform statistical analysis by determining the range of values in a specified field. When used with date fields, these values can also be used to determine a first and/or most recent transaction date for a given customer, as shown here:
FROM MYDB/TRANHIST
WHERE CUSTNO = 12345
The functions VAR and STDDEV are used for statistical analysis. A variance is calculated by taking the mean of the square root of the difference between the mean value in a series of numbers and each number itself. Figure 1 shows the formula for calculating a variance on the numbers 1, 4, and 13.
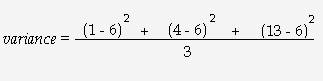
Figure 1: This simple illustration shows the formula to calculate a variance. (Click image to enlarge.)
In this example, the average value in our series is 6. The difference between each of these values and 6 is calculated, giving us -5, -2, and 7, respectively. These values are then squared, which results in 25, 4, and 49, respectively. The sum of these values (78) is then averaged, which gives us a variance of 26. The standard deviation is simply the square root of the variance. Using the example above, the standard deviation would be 5.09902. Generally, these two functions are used to give an idea of the range of values that exist within a data set. The different versions of the functions (VAR_POP, VARIANCE, and STDDEV_POP) are included for maximum compatibility with other SQL implementations.
HAVING Fun Yet?
A discussion of columnar functions would not be complete without mentioning the HAVING clause. This SQL clause allows us to add conditioning to our statement at the total level. While the WHERE clause tests conditions at the detail level, the HAVING clause tests conditions at the summary level. The statement below is an example of using the HAVING clause:
FROM MYDB/ORDDETAIL
WHERE LINEVAL<>0
GROUP BY ACCOUNT
HAVING COUNT(*) > 1
This statement would be used to identify orders with more than one detail line. The WHERE condition LINEVAL<>0 is evaluated for each record read from the data set. The HAVING condition COUNT(*) > 1 is evaluated after the summary data is generated to filter records out of the result set.
No More Analysis Paralysis
SQL aggregate functions give you the ability to analyze volumes of data in ways you may have never imagined. For more information on SQL functions, check out SQL Built-In Functions and Stored Procedures from MC Press.
Mike Faust is an application programmer for Fidelity Integrated Financial Solutions in Maitland, Florida. Mike is also the author of the books The iSeries and AS/400 Programmer's Guide to Cool Things and Active Server Pages Primer and SQL Built-in Functions and Stored Procedures. You can contact Mike at

Mike Faust is a senior consultant/analyst for Retail Technologies Corporation in Orlando, Florida. Mike is also the author of the books Active Server Pages Primer, The iSeries and AS/400 Programmer's Guide to Cool Things, JavaScript for the Business Developer, and SQL Built-in Functions and Stored Procedures. You can contact Mike at
MC Press books written by Mike Faust available now on the MC Press Bookstore.
 |
Active Server Pages Primer Learn how to make the most of ASP while creating a fully functional ASP "shopping cart" application. List Price $79.00 Now On Sale
|
|
 |
JavaScript for the Business Developer Learn how JavaScript can help you create dynamic business applications with Web browser interfaces. Now On Sale
|
|
 |
SQL Built-in Functions and Stored Procedures Unleash the full power of SQL with these highly useful tools. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online