








Structured Query Language (SQL) is a cross-platform industry standard. You can use it to manipulate data and databases on an AS/400 or just about any other system. On the AS/400, you can use SQL through tools such as SQL/400 and Query Management. You can also use SQL to manipulate AS/400 data in a client/server environment with facilities such as ODBC or Remote SQL APIs.
Among SQL's many capabilities is its ability to retrieve records from a relational database-most commonly through a simple SQL SELECT statement. However, there is a more advanced form of SELECT statement known as an SQL subquery (also called an inner query or a nested query). An SQL subquery is a SELECT statement embedded in the WHERE or HAVING clause of another SQL query. It can contain any SQL clauses except for ORDER BY and UNION [ALL]. Subqueries are powerful ways to select just the information you need.
You should learn to use SQL subqueries because some tasks can't be done with a single SQL statement unless you use a subquery. Also, some queries are easier to understand if done with a subquery.
In the paragraphs that follow, I'm going to show you some of the things that you can do with subqueries. I hope you'll see how helpful subqueries can be.
I tested all of the examples with SQL/400, and I tested most with a microcomputer SQL system also. The SQL code shown works with most versions of SQL, including any you might use through microcomputer-based client/server tools and database management systems that run on other computer platforms.
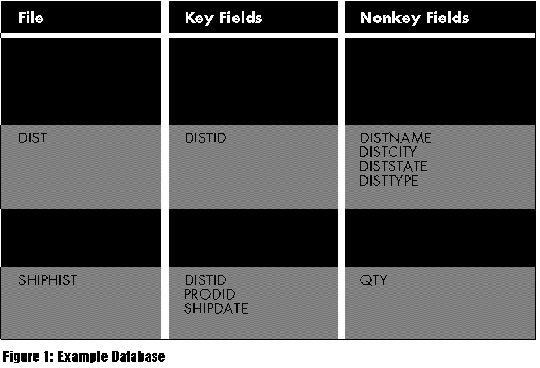
I'll pretend that you work for a company that manufactures goods and sells them through distributors. 1 shows the example database you'll be using. Files PROD and DIST are the product and distributor master files. DISTPROD has a record for each product that a distributor is authorized to sell. SHIPHIST (shipment history) contains a record for each date that the company shipped an item to a distributor.
I'll pretend that you work for a company that manufactures goods and sells them through distributors. Figure 1 shows the example database you'll be using. Files PROD and DIST are the product and distributor master files. DISTPROD has a record for each product that a distributor is authorized to sell. SHIPHIST (shipment history) contains a record for each date that the company shipped an item to a distributor.
I'll start by looking at subqueries that find one value needed by another query.
Suppose the CFO asks you which products cost the most to manufacture. There may only be one product with the highest cost, or there may be many with that same cost. You could answer him with this query:
select * from prod order by cost desc
This query would list everything in the product master file, sorted in descending order by cost. The CFO would have to scan the report until he found products with a cost lower than the cost of the first product listed, and then discard the rest of the report. He only wants to see the item or items with the highest cost, and he knows that a computer wizard like you can limit his report to just what he wants.
You might try this. First, find the highest cost in the product master.
select max(cost) from prod
Let's pretend the query finds $12.45. Then, execute a second query to find all the products that cost $12.45.
select * from prod where cost = 12.45
You used two SQL statements. You need to have SQL plug the cost it finds in the first query directly into the second SQL statement. You do that with a subquery.
select * from prod where cost = (select max(cost) from prod)
The subquery is the select statement inside parentheses. The SQL engine executes the subquery first to find the highest cost in the file. Then it plugs the value it finds into the outer query and returns a list of all the products with that cost.
You can use other record selection criteria in addition to the subquery. Suppose the CFO decides he only wants to see the type D products with the highest cost. Let's modify the previous query to include only type D products.
select * from prod where prodtype = 'D' and cost = (select max(cost) from prod)
The query still looks for the products that cost the most, regardless of type, but only selects the ones that also have a type code of D. Notice that this is not the same as finding the most expensive of the type D products, which would be this:
select * from prod where prodtype = 'D' and cost = (select max(cost) from prod where prodtype = 'D')
This subquery finds the greatest cost of the type D products, which may not be the greatest cost in the products file. The outer query looks for the type D products that have that cost, ignoring products of other types that cost the same.
Here's an example with a subquery in the HAVING clause. You would use it to find the distributors who are authorized to sell all of your products.
select distid from distprod group by distid having count(*) = (select count(*) from prod)
The subquery returns the number of records in the product master file. The outer query is a summary query that counts the number of products each distributor sells and selects distributors who sell exactly that many products. This assumes that there are no invalid products in the DISTPROD file.
The preceding examples used the equal sign to look for exact matches, but all of the relational operators are valid when comparing to a subquery that returns only one value. For example, what products cost more than the average cost of type B products?
select * from prod where cost > (select avg(cost) from prod where prodtype = 'B')
The system determines the average cost of type B products, and then finds all products that cost more.
Sometimes a query needs to compare against a list of values. Subqueries can handle those situations as well. Suppose you want to find the distributors who sell type A products. First, you need to find out which products are type A products.
select * from prod where prodtype = 'A'
Let's pretend that the query finds four products-1110, 1114, 4209, and 8020. Next, key in the following query to find the distributors who sell those products.
select distinct distid from distprod where prodid in ('1110','1114','4209','8020')
This query does the job. Of course, it's a bother to have to write down and key the four product ID codes returned by the first query. You have to be very careful not to miskey one of them. And you were lucky that there were only four products. Suppose there had been 400! It would be nice to feed the results of the first query to the second one. You can if you use a subquery.
select distinct distid from distprod where prodid in (select prodid from prod where prodtype = 'A')
The subquery selects all the type A products, whether there are none, one, or a thousand. The outer query looks for DISTPROD records with those product ID numbers. The DISTINCT keyword makes the output cleaner by eliminating duplicate distributor ID numbers.
You may need more information about the distributors than their ID numbers. No problem!
select * from dist where distid in (select distid from distprod where prodid in (select prodid from prod where prodtype = 'A'))
This SQL statement contains a subquery within a subquery. The subqueries are processed from the inside out. The system finds a list of type A products first, then finds a list of distributor IDs, and finally selects records from the distributor master file.
By the way, I didn't include the DISTINCT keyword in the subquery that selected distributors, but I could have. Whether you use DISTINCT or not matters in outer queries, but not in subqueries.
The subquery can be a summary query. The subquery in this example retrieves the description, ID, and profit (defined as wholesale price minus cost) of all products sold by at least one but no more than ten distributors, in order from least to most profitable.
select prodname, prodid, whslprice - cost profit from prod where prodid in (select prodid from distprod group by prodid having count(*) <= 10) order by profit
The subquery uses the GROUP BY and HAVING clauses to select the products sold by no more than ten distributors. The outer query retrieves the product name, ID number, and profit of the products selected by the subquery.
Subqueries also provide a good way to find data exceptions, such as which records in the DISTPROD file have product IDs that are not in the product master file.
select * from distprod where prodid not in (select prodid from prod)
The subquery returns the product IDs of all the products in the product master file. The outer query finds records in the DISTPROD file that have other product ID numbers.
The outer queries in the preceding examples were SELECT statements, but you can use subqueries in the other data manipulation commands as well. Here's a subquery that deletes the records of distributors who have not bought anything within the last two years.
delete from dist where distid not in (select distid from shiphist group by distid having max(shipdate) > current date - 2 years)
The subquery finds the latest shipment date for each distributor and chooses the distributors whose latest ship date was within the past two years, dating back from the current date. The outer query deletes the records of any distributors that the subquery did not select. This example points out another strength of SQL: The date calculations for the date data types are fully supported.
In the queries shown so far, the subquery was executed only once-before execution of the outer query. The subquery was executed first and ran to completion before the outer query began to run. In correlated subqueries, the inner query is executed once for each record returned by the outer query, and it can use data from the outer query. The outer query begins execution first. The subquery does not wait for the outer query to finish before beginning to run. It begins to run each time the outer query retrieves another record and runs to completion before the outer query retrieves the next record.
Any file from the outer query that the subquery references must be given a correlation name. The correlation name follows the actual file name and is separated by white space (at least one blank).
select * from prod p where ...
In this example, p is the correlation name for the file named PROD.
Let's see a correlated subquery in action. This one finds the product type, name, ID, cost, and wholesale price of the most costly items of each type.
select prodtype, prodname, prodid, cost, whslprice from prod p1 where cost = (select max(cost) from prod p2 where p1.prodtype = p2.prodtype) order by prodtype
Each time the outer query retrieves a record, the subquery finds the maximum cost of all the records of the same type. If the cost of the record retrieved by the outer query matches the cost found by the subquery, the record is selected.
Notice that a correlated subquery doesn't make sense by itself because it refers to the correlation name of a file in the outer query. This is unlike the subqueries shown earlier, which could have run apart from the outer query.
The EXISTS operator is used to test whether or not the subquery returns any records. If the subquery returns at least one record, the condition proves true. EXISTS is most often used in correlated subqueries.
This operator comes in handy when you want to use an IN operator on two search fields. Here's an example: Your company authorizes distributors to sell products, but that doesn't mean they'll necessarily sell them. Let's find instances in which a distributor is authorized to sell a product, but the company has never shipped that product to him.
You might try this:
select * from distprod where distid, prodid not in (select distid, prodid from shiphist)
That code won't work. The IN operator will only compare a single field against a list of single values.
You can do the query by using EXISTS.
select * from distprod dp where not exists (select * from shiphist sh where dp.prodid = sh.prodid and dp.distid = sh.distid)
The system reads each record of the DISTPROD file. For each record, it searches SHIPHIST for a record that has the same distributor ID and product ID. If it does not find at least one match, the outer query returns a record from the DISTPROD file.
The correlation name SH for the SHIPHIST file isn't necessary, but it makes the query easier to read.
Queries with embedded subqueries can almost always be replaced with queries that join files. This is an example of an embedded subquery.
select * from distprod where prodid in (select prodid from prod where prodtype = 'A')
This is a query that joins files.
select dp.* from distprod dp, prod p where dp.prodid = p.prodid and prodtype = 'A'
Both queries get the same results. So which is better? Neither. The first version has the advantage that it is easier for some people (including me) to read and understand. The second, however, gives access to all the fields in the products file. A professional should know and understand both methods, know when to use each one, and be able to convert one to the other as the need arises.
You don't have to choose one method or the other. You can mix and match them. Suppose you want to know more about the distributors than the previous query told you-such as their names and the states in which they're located.
select a.*, distname, diststate from distprod a, dist b where a.distid = b.distid and prodid in (select prodid from products where prodtype = 'A')
This query joins the DISTPROD and DIST files, yet uses a subquery to select the type A products. You could also have joined all three files and eliminated the subquery. You could not have eliminated the join and used subqueries only, since the end result requires information from more than one file.
Other times, joining will not be an option, and you'll have to resort to a subquery. For example, you can't update through a join, but you can update through a subquery. Here's how you might raise the wholesale price by 2 percent for all products sold by distributor 106.
update prod set whslprice = whslprice * 1.02 where prodid in (select prodid from distprod where distid='106')
The subquery finds all the products that distributor 106 is authorized to sell. The outer query increases the wholesale price of each of those products by multiplying it by 1.02.
I Love SQL
I'm an SQL addict. I can't work without it. SQL is by far the greatest productivity aid I've ever used.
SQL grows in importance every year, so it's to your benefit to hone your skill in using it. Don't be content with simple SQL queries. Distinguish yourself by mastering subqueries as well.
REFERENCES
DB2/400 SQL Programming V3R1 (SC41-3611, CD-ROM QBKAQ800).
DB2/400 SQL Reference V3R1 (SC41-3612, CD-ROM QBKAQ900).
An Introduction to SQL Subqueries
Figure 1: Example Database

Ted Holt is IT manager of Manufacturing Systems Development for Day-Brite Capri Omega, a manufacturer of lighting fixtures in Tupelo, Mississippi. He has worked in the information processing industry since 1981 and is the author or co-author of seven books.
MC Press books written by Ted Holt available now on the MC Press Bookstore.
 |
Complete CL: Fifth Edition Become a CL guru and fully leverage the abilities of your system. List Price $79.95 Now On Sale
|
|
 |
Complete CL: Sixth Edition Now fully updated! Get the master guide to Control Language programming. Now On Sale
|
|
 |
IBM i5/iSeries Primer Check out the ultimate resource and “must-have” guide for every professional working with the i5/iSeries. List Price $99.95 Now On Sale
|
|
 |
Qshell for iSeries Check out this Unix-style shell and utilities command interface for OS/400. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online