








Virtualization and Internet Protocol version 6 (IPv6) are both hot topics, and not only for IBM; it seems that everyone is trying to understand how to leverage these technologies. Here is a real-world example of how you can use them together to provide value for your business.
Virtualization by definition means to logically separate from the physical, and in computing terms this generally is done to simplify technology to make it more versatile. The two virtualization technologies I will be describing are virtual SCSI (vSCSI), which allows us to share storage between logical partitions, and virtual Ethernet, which allows TCP/IP communication between logical partitions. The IBM POWER Hypervisor is the underlying technology that makes this virtualization possible.
The goal is to use vSCSI to mirror storage across logical partitions to create a highly available IPv6 router.
This means that you will have a logical partition that will run on virtualized DASD and will not be dependent on any single logical partition. In fact, if mirroring is configured with hot spares, you could lose your primary, secondary, or tertiary vSCSI host without causing an outage for your Linux logical partition. This becomes important when you run infrastructure services, such as an IPv6 router, on this logical partition.
Figure 1 shows a conceptual graphic of the vSCSI configuration:
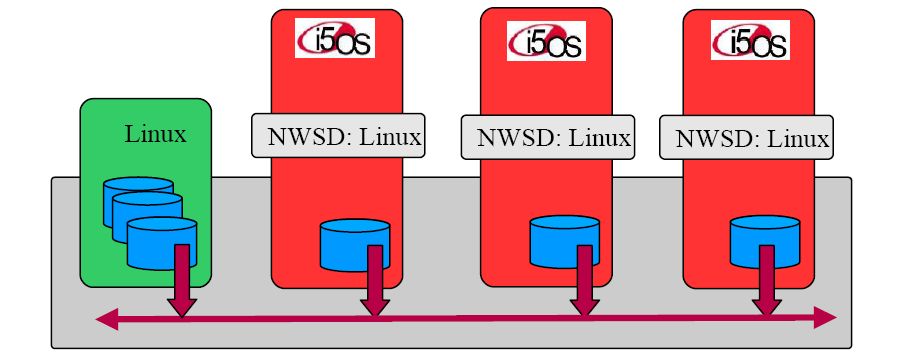
*Note: Only two disks may be part of a mirror configuration; additional disks may be created as hot spares.
Figure 1: A vSCSI configuration looks like this. (Click images to enlarge.)
Here is the process to follow to configure this solution:
- Identify at minimum two i5/OS logical partitions that you wish to host the vSCSI disks. Choose wisely as to minimize any possibility that all vSCSI host partitions will have simultaneous outages (outside of a system IPL).
- On each i5/OS vSCSI host, create an identically sized vSCSI disk and properly configure that to link to a NWSD.
- Install Linux onto this logical partition using all of the vSCSI disks in a mirror configuration.
Using the raid configuration tool available for Linux, you can easily automate the process of synchronizing the mirror. For this solution, you'd use the mdadm command.
With the logical partition running and isolated from single or double fault due to a hosting partition availability, you are now ready to consider using this partition for an IPV6 router.
This is just an example as this solution could easily be used to perform many network infrastructure services, such as file/print sharing with Samba, firewall capability, etc.
To move onto the application portion, IPv6 supports stateless auto configuration, which is similar in nature to DHCP but is far more capable. i5/OS supports stateless auto configuration on the client side, so it makes sense to configure this service on the Linux partition. This will enable you to turn on an IP interface on i5/OS by choosing stateless auto configuration and become completely configured to operate in your IPv6 network without manual client configuration.
By running an IPv6 router in a Linux partition on your iSeries (or System i, whichever model you have), you enable all of your i5/OS partitions to participate in an IPv6 network with no additional DASD, and the only physical Ethernet IOA required on the whole system is the one attached to the Linux partition. In this example, IPv4 has been separated from IPv6, but they could both be running on the same adapter. You will use virtual Ethernet between the Linux partition and all of the other logical partitions on the system, and vSCSI to share storage from the identified i5/OS partitions to the Linux partition
Figure 2 shows an example IPv6 startup network configuration:
|
Figure 2: Here's a sample IPv6 startup network configuration.
The Linux IPv6 router advertisement daemon (radvd) is used for stateless auto configuration. If you're running an RPM-based Linux distribution, such as Red Hat or Novell SuSE, make sure you have the radvd RPM installed.
Figure 3 shows an example of the radvd.conf configuration file:
|
Figure 3: This is an example of the radvd.conf configuration file.
Many of these are default settings; your specific settings are the interface and the prefix.
The prefix section in comparing to IPv4 is like telling the client what portion of the address is the network. This example advertises the prefix to clients as a fec0:301:0:1234:: network with a 64-bit mask (also written as fec0:301:0:1234::/64). The double colons (::) indicate that the remaining bits are zeros.
Your interface and prefix will vary depending on your environment; however, the configuration is quite simple as shown here. With this service running on an interface that can communicate with the virtual Ethernet on your i5/OS partitions, you now have stateless auto configuration enabled for your System i.
This solution has many possibilities and could be used for many other services. Running Linux on your POWER5 system opens the doors to many possibilities and IBM virtualization technology makes it possible.
(Author's Note: Please see the appendix below for a technical explanation of the recovery steps and links to reference materials.)
Daniel DeGroff is a member of the High Availability Center of Competency (HACoC) in Systems and Technology Group. He can be reached by email at
Appendix
Technical Explanation of Recovery Steps
If an i5/OS partition that is being used for vSCSI disk in this solution IPLs or is down for any reason, it will cause the mirror to fail. When this happens, you are running exposed, and the mirror will display the failed partition by running mdstat. To recover that disk partition when the target i5/OS partition becomes available again, you need to perform a few manual steps that can be easily automated with the examples given below. From a high level, you need to do the following:
- Mark any disk partitions that belong to the vSCSI host as failed.
- Remove all failed partitions from the mirror(s).
- Remove the vSCSI controller belonging to the vSCSI disk.
- Once the vSCSI host is available, rescan vSCSI host bus.
- Add disk partitions back into mirror(s).
If you don't remove all failed partitions in the mirror(s) before rescanning for the disks on that bus, a disk previously known as sdb may show up as sdc. To make sure you get the same numbering every time, you need to remove all failed partitions in the mirror. Then, to get disks configured dynamically to come back online, you need to remove the failed vSCSI controller and rescan the bus.
If /dev/sdb3, for example, was part of the mirror for the root fs (/) and the hosting vSCSI went down, /dev/sdb3 would show failed in mdstat (/proc/mdstat). However, if you used /dev/sdb2 from that same disk in a swap mirror and you aren't touching swap space, that partition may not show as failed. To make sure you maintain disk order, you have to then manually mark that partition as failed.
The example commands below describe how to perform these steps. With a little bit of logic, these steps could be easily automated in a shell script.
Example recovery steps for mirror:
- Mark partitions failed—Mark /dev/sda3 failed on raid /dev/md0
#> mdadm /dev/md0 -f /dev/sda3 - Remove partitions from raid set—Remove /dev/sda3 from raid /dev/md0
#> mdadm /dev/md0 -r /dev/sda3 - Remove vSCSI host controller from configuration—Remove host controller 0
#> echo “scsi remove-single-device 0 0 0 0” > /proc/scsi/scsi - Scan SCSI bus on host controller for disks—Scan host controller 0
#> echo “- - -” > “/sys/class/scsi_host/host0/scan” - Add partition back into mirror—Add /dev/sda3 into /dev/md0
#> mdadm /dev/md0 -a /dev/sda3 - Monitor mirror status
#> cat /proc/mdstat
or
#> watch 'cat /proc/mdstat'
Other Technical Notes
In theory, you could also use vSCSI on a Linux partition to perform software RAID5, for example. However, assuming you are already following the recommended practice on your i5/OS partition and running some level of protection on your ASP (e.g., mirroring or parity), it would be somewhat redundant to do the same on your Linux partition.
The Linux installation should allow for mirroring of swap and other partitions. POWER Linux requires a PREP partition to boot the kernel. This partition may not be mirrored; in this solution, the PREP partition was created on both sides of the mirror with both set to bootable. To replicate the two identical PREP partitions the dd command can be utilized as follows:
#> dd if=/dev/sda1 of=/dev/sdb1
Note: This examples assumes /dev/sda1 has been populated with the boot kernel during installation and that /dev/sdb1 also exists as a PREP partition on /dev/sdb and is of similar size.
Since the boot kernel should not change unless upgraded, performing this step once should be adequate. A rescue kernel may be needed in order to change the boot partition.
Graphic of System Configuration
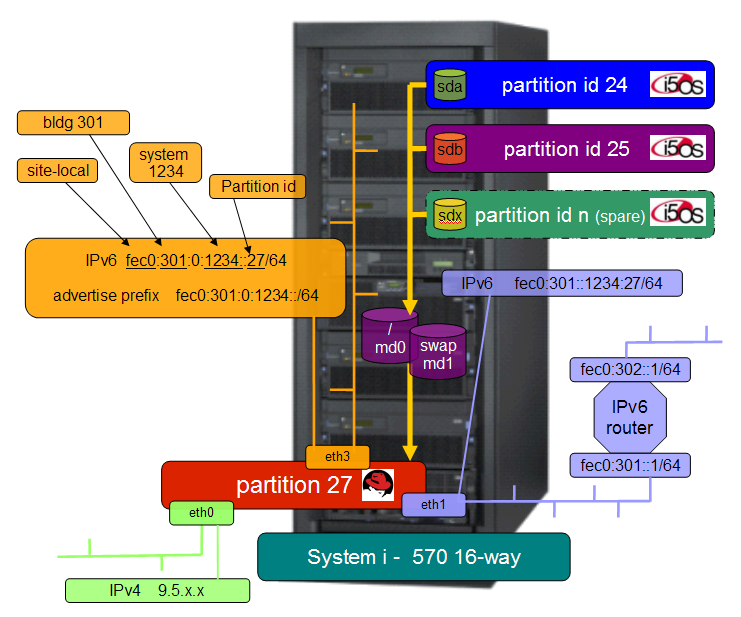
Reference Information
IPv6
Linux IPv6
Linux IPv6 HOWTO
Router Advertisement Daemon (radvd)
Linux IPv6 Router Advertisement Daemon (radvd)
RADVD Introduction
i5/OS
Configure IPv6 stateless address autoconfiguration
Networking TCP/IP Setup
Software Mirroring on Linux
RAID
The Software-RAID HOWTO
mdadm
mdadm
mdadm

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online