








Last month, this column featured the first of a two-part article describing the use of readily available open-source tools to create a network-attached storage (NAS) device. This month, we'll look at the mechanics involved and the supporting projects that make it possible.
The Phone Booth
At the conclusion of last month's article, we were discussing Dr. Who's phone booth and the fact that the interior was larger than the exterior's dimensions would allow. Actually, we were discussing the difference between symbolic links and hard links, the latter being the Linux equivalent of the Dr. Who phone booth, allowing what appears to be multiple and complete backups to physically use much less space than they really should.
Remember, a symbolic link is a directory entry that points to another directory entry which, in turn, points to the actual file. On the other hand, a hard link is simply a directory entry that points to the same file as another directory entry. The result is that the file's contents remain until all references are deleted. Let's look at an example, starting with a directory containing a single file:
-rw-rw-r-- 1 klinebl klinebl 27 Jul 21 20:37 original.txt
The output of the ls command is in the following columnar format:
Notice the "1" in link count? That means that only one hard link (made when I created the file) points to the file.
Now, let's create both a symbolic link to the file and then a hard link:
[klinebl@laptop2 demo]$ ln original.txt hardlinked
Verifying the results of our work, we can easily see the existence of the symbolic link, but the only clue that "hardlinked" and "original.txt" are pointing to the same data is that their sizes and modification times are identical:
-rw-rw-r-- 2 klinebl klinebl 27 Jul 21 20:37 hardlinked
-rw-rw-r-- 2 klinebl klinebl 27 Jul 21 20:37 original.txt
lrwxrwxrwx 1 klinebl klinebl 12 Jul 21 20:38 symlinked -> original.txt
The "1" in the first column of "symlinked" indicates that the entry is a symbolic link, and by looking at the end of that line, we can tell to which hard link it points. To really see that "hardlinked" and "original.txt" point to the same data blocks, we need to tell ls to print the "inodes" (file serial and index number) instead of the permissions.
1048594 -rw-rw-r-- 2 klinebl klinebl 27 Jul 21 20:37 hardlinked
1048594 -rw-rw-r-- 2 klinebl klinebl 27 Jul 21 20:37 original.txt
1048593 lrwxrwxrwx 1 klinebl klinebl 12 Jul 21 20:38 symlinked -> original.txt
Do you notice that their inodes (in column 1) were identical? Both link counts have been incremented as well; this tells you that there are two hard links pointing to the same data.
Now that you understand how this works, let's look at a simple set of commands that, if run daily, will produce copies of how a directory looked today, yesterday, two days ago, and three days ago. The script (as shown below) does not include the line numbers, which were added for clarity.
2) mv backup.2 backup.3
3) mv backup.1 backup.2
4) cp -al backup.0 backup.1
5) rsync -a --delete source_directory/ backup.0/
Line one removes (deletes) the backup.3 directory; the r and f switches make it recursive (thus deleting every subdirectory appearing below it) and do it without asking for verification.
Lines two and three simply rename the backup.2 directory to backup.3 and backup.1 to backup.2.
Line four makes a copy of the directory backup.0 to backup.1, but instead of actually copying data, the l switch directs cp to make hard links instead. The a (archive) switch tells the cp command to preserve permissions, to make the copy recursively, and to preserve any directory links within the copied directory.
Finally, line five uses the rsync command to synchronize between the source_directory directory and the backup.0 directory. I discussed the rsync utility in an earlier article, but, in a nutshell, it is a utility for efficiently synchronizing data between two directories, be they on the same or different machines. For dragging data across a network, you'd be hard-pressed to find a sweeter solution.
Once you work through this, you'll realize that the total space used to store your data is equivalent to the size of the original directory plus the size of the daily changes. Slick! A complete discussion of this technique is available on the Web, and I highly recommend that you read it before deploying your own NAS server.
Already Done for You
Of course, once you decide to do this, you'll have to write the scripts to actually go out and backup your servers. Or will you? The beauty of open source is that invariably someone has already done what you want to do. A quick Google search will usually yield what you need or something that you can customize. In this case, the heavy lifting for "rsyncing" has been done by Nathan Rosenquist in his project: rsnapshot. Rosenquist has provided the scripts you'll need to generate backups for a single host or a whole host of them (pun intended). You can point your browser to his project for the full details, but let me give you his executive summary: "rsnapshot is a filesystem snapshot utility. It can take incremental snapshots of local and remote filesystems for any number of machines." That includes both Windows and Linux machines, since an rsync daemon is available for Windows.
The entire RPM package I downloaded was a mere 60K in size, and it included the configuration file (rsnapshot.conf), the PERL script (rsnapshot), the man(ual) pages, and other documentation. The installation and configuration are truly simple. Once the software is installed (I used the rpm utility; you can also get the software as a tar file), you need only to edit the configuration file before you can generate your first snapshot. The configuration file itself is simple, well-documented, and preconfigured with sensible defaults for an hourly and daily snapshot. To save space, I won't reproduce a complete file here. If you go to the rsnapshot Web site, you can see for yourself. A subset of the configuration, which shows the more interesting directives, appears below:
snapshot_root /snapshots/
# keep 5 hourly, 7 daily, 4 weekly and 3 monthly snapshots.
interval hourly 5
interval daily 7
interval weekly 4
interval monthly 3
# save the local /home directory into /snapshots/.../localhost/home
backup /home/ localhost/home/
# run a script to backup mysql databases into /snapshots/.../databases
backup_script /usr/local/bin/backup-mysql.sh localhost/databases/
# save the /home directory on othersystem to
# /snapshots/.../othersystem/home
backup root@othersystem:/home/ othersystem/home/
The comments above each directive are self-explanatory. However, there is one aspect of rsnapshot that warrants a brief mention. Besides saving files, I typically back up my MySQL and PostgreSQL databases to a snapshot on a regular basis. To accomplish this, I use the mysqldump and pg_dump commands respectively during my backup scripts. Provisions for doing so with rsnapshot are conveniently provided, as shown above. You simply add a backup_script directive to the configuration file, and it will be executed. The documentation indicates that you should write the output into the current directory, like so:
Then, rsnapshot takes care of the rest. The gotcha is that these scripts are run locally. There is no provision to execute remote scripts directly from rsnapshot. You can, however, do so in the script called from rsnapshot. To run a similar script on a remote server and satisfy rsnapshot's requirements, simply use the ssh utility. The command within your script then becomes this:
The output of the dump will be delivered to stdout locally, where you can redirect it (>) to a local file.
One other thing about backing up remote systems: To make it a hands-off operation, you'll need to either set up ssh to use public key authentication (useful for scripts and file copying) or set up an rsync server (useful for file copying only). For Windows, an rsync server will be a necessity.
The documentation for both utilities will assist you with these tasks.
Serving the Backups
Once you have your backup server configured and operating, you'll want to make those backups available to your users, which is easy to do with Samba. In Figure 1, we can see the result of running rsnapshot configured to maintain two hourly snapshots with one daily having been run.
|-- daily.0
| `-- localhost
| `-- home
| |-- curly
| | `-- A.txt
| |-- larry
| `-- moe
|-- hourly.0
| `-- localhost
| `-- home
| |-- curly
| | |-- A.txt
| | |-- B.txt
| | `-- C.txt
| |-- larry
| `-- moe
`-- hourly.1
`-- localhost
`-- home
|-- curly
| |-- A.txt
| `-- B.txt
|-- larry
`-- moe
Figure 1: The snapshot root directory (snapshots) contains all of the subdirectories created by rsnapshot. This is the directory you'll want to make available via Samba.
The view from a Windows machine is shown in Figure 2.
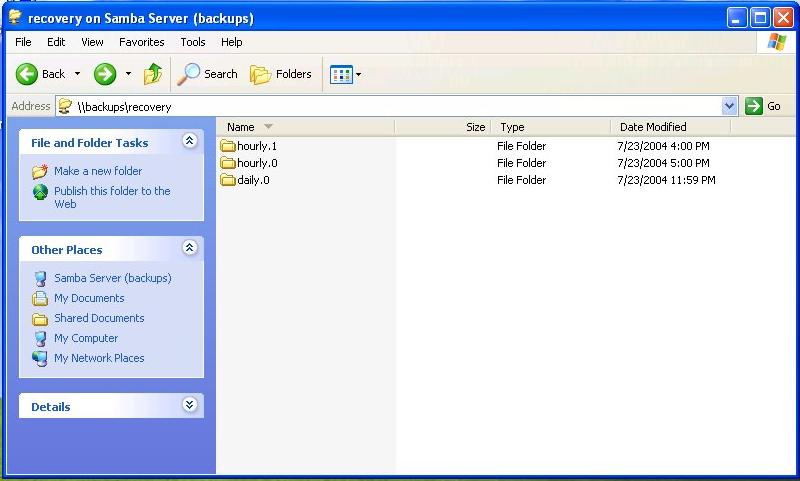
Figure 2: This is how the snapshot root directory looks from Windows. (Click images to enlarge.)
These are the relevant parts of the Samba configuration for this share:
[recovery]
comment = Backup Files
browseable = yesterday
writeable = no
path = /snapshots
As you can see, there's nothing difficult about this. Now, if the user clicks down a few directories, he'll arrive in the home directory, as shown in Figure 3. This system has only three users: curly, moe, and larry. I'm sure yours would have more!
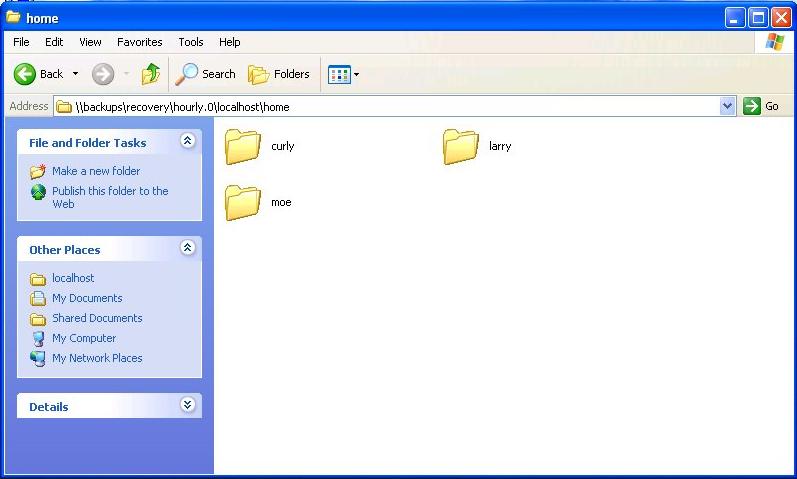
Figure 3: A few clicks and curly has reached the directory containing all of the user home directories.
But What About Security?
Ahhh, security. Now there's the rub. You certainly do not want users browsing others' files like curly tried to do in Figure 4. As you can see, his request was denied.

Figure 4: Samba enforces security and disallows curly's foray into moe's files.
Samba is verify flexible in its handling of security matters, but this can be the most confusing aspect to a project such as this. The reason? Because you are dealing with not only the Windows security model but also the UNIX model. Samba respects any UNIX permissions set on directories, and it will attempt any access as the user ID who is making the request from Windows. Thus, you need to ensure that the resources you want to use within the Linux file system are accessible by the end user. Once you have verified that, you can turn your attention to the Samba configuration. This is when things can become more challenging. There simply isn't enough space in this article to describe all of the possibilities available to you, so I'll just touch on a few highlights.
To be sure, the easiest scenario is when you host your snapshot server on the same machine as your file server. That makes user authentication and resource access straightforward. You literally have a working Samba configuration in fewer than a dozen lines when done this way. But that's satisfactory only for smaller installations. Larger enterprises will have more work to do.
The holy grail of security is single sign-on, and if you plan on using the single host mentioned in the last paragraph, the problems you will run into when synchronizing users and passwords between your backup NAS and your other machines may make the prospect of restoring user data yourself more desirable. Fear not: Samba can form trust relationships with other Samba servers, as well as authenticate against Windows PDC and Kerberos servers. So the task is a lot less onerous than it could be. The trick when configuring Samba is to ensure either that the user ids (UID) and group ids (GID) are the same between machines or that you provide Samba the appropriate mapping between the Windows user names and local UNIX users. All of this (and more) is explained in exquisite detail in the Samba documentation. While you're there, note the printed documentation referred to at that link. It is available for sale in finer bookstores everywhere and helps to support the project.
A Little Elbow Grease
I hope you'll take advantage of these open-source tools and consider building a snapshot server or two. To summarize, you'll need to install and configure the following software to pull it off:
- Linux or one of the BSDs on a machine with sufficient disk capacity for the data you wish to store. This may be the Samba server on which you're hosting your file server.
- A Perl interpreter (for rsnapshot). Most distributions already include this.
- The openssh and openssh-clients packages (or equivalent) for the ssh utility. Since ssh has all but supplanted Telnet and many of the "r" utilities (used for initiating remote services), it too is probably installed on your Linux machine.
- The rsync utility and, if pulling data from a Windows machine, cwRsync.
- The rsnapshot script to save yourself the need to write custom scripts.
- Samba so that the users can retrieve their own backed-up data. Once again, most distributions include Samba.
Even if you don't want to tackle the Samba aspect (allowing users to restore things for themselves), you still can put together a snapshot backup NAS device that will allow you to restore things yourself more easily. The cost is minimal, and the rewards can be great. Best of all, you'll be the miracle worker the next time a user comes to your office door with panic on his face!
Barry L. Kline is a consultant and has been developing software on various DEC and IBM midrange platforms for over 21 years. Barry discovered Linux back in the days when it was necessary to download diskette images and source code from the Internet. Since then, he has installed Linux on hundreds of machines, where it functions as servers and workstations in iSeries and Windows networks. He also co-authored the book Understanding Linux Web Hosting with Don Denoncourt. Barry can be reached at

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online