








The first part of this article series showed how DSPOBJD can easily provide statistics to manage a general recompilation project. But it only touched the surface of all the things you get with the DSPxxx commands.
Let's start with a review of the information we gathered in Part I by just using DSPOBJD.
Objects by Type and Year
This data is concerned with counting objects by type and by year of source update (for those that have a source, of course).
If we had used ODCCEN plus ODCDAT (i.e., the object creation date) instead of ODSRCC plus ODSRCD, we'd have gotten a report on recompilation instead of a report on source update.
with stat as (SELECT ODOBTP "Type" , odobat "Attribut", trim(char( ODSRCC+ 19)) concat substr(ODSRCD , 1 , 2) "Year" FROM jpltools.objs where odsrcc <> '') select "Year" ,"Type" , "Attribut", count(*) Number from stat group by "Type" , "Attribut", "Year" order by "Year","Type" , "Attribut"
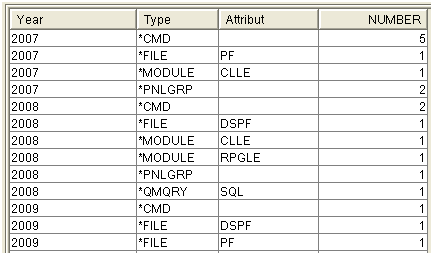
Figure 1: Here's the list of objects by type and year.
The code below counts programs (in fact, programs and modules, to also take care of ILE objects) by compiler. Note that objects without source are eliminated by the WHERE clause.
SELECT odobat "Attribut" , count(*) Number FROM jpltools.objs where odsrcc <> '' and ODOBTP in('*PGM', '*MODULE') group by odobat order by odobat
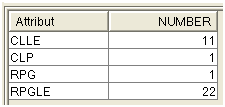
Figure 2: The programs are counted by compiler type.
There are two OPM programs in the libraries analyzed: one CLP and one RPG. But this analysis doesn't show whether the ILE programs use the ILE default activation group or a specific activation group. This information is provided by DSPPGM, which does not offer an output file. In the third part of this series, we will use the program description APIs for this information.
Sources in Library
The following SQL will reveal the number of instances of source code per library.
select count(*) number, ODSRCL srclib FROM jpltools.objs group by ODSRCL
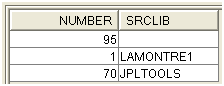
Figure 3: JPLTOOLS has 70 source files.
Old applications may have had their libraries of code renamed many times and can show traces of these old libraries' names, so this list can be overwhelming. There are often names of libraries that no longer exist. This does not mean that the source code is lost, but it would be wise to check that the available source code has the same date indicated in the object.
Sources (aka File Members) per File
The following code will show you the number of instances of source code per file. Note that the objects without source are eliminated by the WHERE clause.
select count(*) number, ODSRCF srcpf FROM jpltools.objs where ODSRCF <> '' group by ODSRCF order by number desc
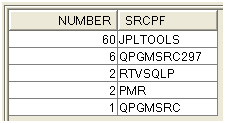
Figure 4: Here's the number of instances of source code per file.
Much less often than in the list per library, this list can show source file names that have disappeared ... or should have disappeared.
Objects by Version
In a complex environment, it is common to have multiple machines with different version levels. This analysis ensures that the application can be used on a machine that is not yet at the latest version level.
SELECT count(*)number , ODcpvr i5os FROM jpltools.objs where odobtp in ('*PGM','*SRVPGM') group by odcpvr order by i5os
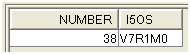
Figure 5: Objects are shown by version.
Here, the objects are all compiled for V7.1. Installation on a machine running an older version will require a recompilation. Sometimes, problems can appear if one or more programs use specific features of V7.1.
Note: In the case of JPLTOOLS, the question does not arise since I offer only the source code. And the JPLTOOLS code is backward-compatible until V5.4.
Objects by Owner
Is management of the owners being done correctly? DSPOBJD gives no information on adoption of rights. We will use the program description APIs for this information.
SELECT count(*)number , ODobow owner FROM jpltools.objs group by odobow
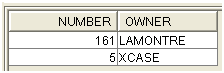
Figure 6: Objects are shown by owner.
Ha! I have to make corrections.
All the above information was obtained only by using the result of DSPOBJD. Now we will extend our investigations to other commands. We'll use SQL to mix the results provided.
Check the Date of the Source Code
The target of this analysis is to check that the source has not changed since last compilation.
Obviously, this runs only for programs built with a module of same name. By doing this, I'll artificially create a link between the source member and the program. In fact, when context is more complex than a source producing a module producing a program, I will need a true link between these three elements. APIs provide this information . I will return to that point later.
How do I do it? Run a DSPFD MBRLIST and join!
DSPFD FILE(JPLTOOLS/*ALL) TYPE(*MBRLIST) OUTPUT(*OUTFILE) FILEATR(*PF)
OUTFILE(JPLTOOLS/MBRLIST)
OK, but this list contains members of all files: PF-DTA and PF-SRC.
To keep only the membership list of source files, retrieve the attributes of all files:
DSPFD FILE(JPLTOOLS/*ALL) TYPE(*ATR) OUTPUT(*OUTFILE) FILEATR(*PF)
OUTFILE(JPLTOOLS/FD_ATR)
Then, isolate the source filenames:
SELECT PHFILE FROM JPLTOOLS.FD_ATR WHERE PHDTAT='S'
Keep only the members of the source files:
DELETE FROM JPLTOOLS.MBRLIST WHERE MLFILE NOT IN (SELECT PHFILE FROM JPLTOOLS.FD_ATR WHERE PHDTAT='S')
Reminder: DSPOBJD gives us the exact date of the source code when compiling the module. DSPFD MBRLIST gives us the exact date of last modification of the source code.
The next step is to simplify reading of DSPFD-MBRLIST. For the modification date of the source code, use this code:
SELECT MLNAME, case when MLCHGc = '' then ' ' else trim(char( MLCHGC+ 19)) concat MLCHGD concat '-' concat MLCHGt end Upddate,MLMTXT FROM jpltools.mbrlist WHERE MLCHGc <> ''

Figure 7: Simplify the reading of DSPFD-MBRLIST. (Click images to enlarge.)
Now, simplify the reading of DSPOBJD. For the date of compilation of source code, use this code:
SELECT ODOBNM, ODSRCM , case when odsrcc = '' then ' ' else trim(char( ODSRCC+ 19)) concat ODSRCD concat '-' concat odsrct end cpldate , ODOBTX FROM jpltools.objs WHERE odsrcm <> '' and odsrcc <> ''

Figure 8: Simplify the reading of DSPOBJD.
The join of the two previous results (with SQL CTE, common table expression) gives the list of programs without source (based on an SQL exception join):
with cpl as ( SELECT ODOBNM, ODSRCM , case when odsrcc = '' then
' ' else trim(char( ODSRCC+ 19)) concat ODSRCD concat '-' concat
odsrct end cpldate , ODOBTX FROM jpltools.objs WHERE odsrcm <> ''
and odsrcc <> '' ), upd as ( SELECT MLNAME, case when MLCHGc = ''
then ' ' else trim(char( MLCHGC+ 19)) concat MLCHGD concat '-'
concat MLCHGt end Upddate,MLMTXT FROM jpltools.mbrlist WHERE MLCHGc
<> '' ) select ODOBNM, ODSRCM , cpldate, odobtx from cpl exception
join upd on odsrcm = mlname

Figure 9: Here's the list of programs without source.
Now find the list of source that are not used by a compiler to build an object—for example, code description of a service program, code of an SQL procedure, or copies of code:
with cpl as ( SELECT ODOBNM, ODSRCM , case when odsrcc = '' then
' ' else trim(char( ODSRCC+ 19)) concat ODSRCD concat '-' concat
odsrct end cpldate , ODOBTX FROM jpltools.objs WHERE odsrcm <> ''
and odsrcc <> '' ), upd as ( SELECT MLNAME, case when MLCHGc = ''
then ' ' else trim(char( MLCHGC+ 19)) concat MLCHGD concat '-'
concat MLCHGt end Upddate,MLMTXT FROM jpltools.mbrlist WHERE MLCHGc
<> '' ) select upd.* from upd exception join cpl on odsrcm = mlname
![]()
Figure 10: Here's a list of sources without objects.
Now you'll want the list of sources modified but not recompiled:
with cpl as (
SELECT ODOBNM, ODSRCM , case when odsrcc = '' then ' ' else trim(char( ODSRCC+ 19)) concat ODSRCD concat '-' concat odsrct end cpldate , ODOBTX FROM jpltools.objs WHERE odsrcm <> '' and odsrcc <> ''
), upd as (
SELECT MLNAME, case when MLCHGc = '' then ' ' else trim(char( MLCHGC+ 19)) concat MLCHGD concat '-' concat MLCHGt end Upddate,MLMTXT FROM jpltools.mbrlist WHERE MLCHGc <> ''
) select ODOBNM "Object", ODSRCM "Src Mbr",
cpldate concat case when upddate = cpldate then '' else ' was updated ' concat upddate end "Compiled_date"
, case when mlmtxt = odobtx then ' ' concat odobtx else '>> ' concat odobtx concat ' changed to ' concat mlmtxt end "Text"
from cpl join upd on odsrcm = mlname and (cpldate <> upddate
or odobtx <> mlmtxt)

Figure 11: These are the sources modified but not recompiled.
I changed my machine; we see the traces dated 2010-11-12-20:41:42.
Remember that these analyses are based on the fact that program and source code members have the same name. It is common, but not 100 percent accurate.
Program Cross-Reference
I'm gaining momentum, and after getting so much information from two system commands, other questions have quickly come to mind:
How can we tell if a program or file is no longer used? Explore DSPPGMREF. Obviously, we cannot answer this question if the program name is determined dynamically in the application.
Here's a more difficult question: A program that should not be used remains called in some programs (last-used date is recent, days-used count continues to grow…). How can we get an impact analysis of deleting this program? The answer is again provided by SQL—specifically by the recursive SQL on the DSPPGMREF outfile.
In the same way and by writing the recursion in the opposite direction, I have obtained for a given program a list of all programs and files it uses. SQL recursion has been available since V5R4.
This is the DSPPGMREF, simple version:
DSPPGMREF PGM(JPLTOOLS/*ALL) OUTPUT(*OUTFILE) OBJTYPE(*ALL)
OUTFILE(JPLTOOLS/PGMREF)
Why a "simple version"? Because there's a complex version. Indeed, DSPPGMREF allows you to find cross-references—not only PGM, but also SQLPKG, SRVPGM, MODULE, and QRYDFN. Yes, but with several minor problems.
First problem: The structure of the DSPPGMREF outfile does not give the type of the object scanned. This information is actually provided by the column WHSPKG:
WHSPKG Type
P *PGM
S *SQLPKG
V *SRVPGM
M *MODULE
Q *QRYDFN
This forces us to, at least, require that the transformation be able to make joins with the DSPOBJD file:
alter table jpltools.pgmref add column whptyp char (10 ) not null with default ;
update jpltools.pgmref set whptyp = case
when whspkg ='P' then '*PGM'
when whspkg ='S' then '*SQLPKG'
when whspkg ='V' then '*SRVPGM'
when whspkg ='M' then '*MODULE'
when whspkg ='Q' then '*QRYDFN' end
Second problem: Variable names are exposed (dynamically called programs). We may want to ignore them. And the modules overlap program references, so they are not useful.
Third problem: DSPPGMREF provided a list of all formats, especially for DSPF. My analysis of cross-references does not descend to the file format level; this information is then simply useless duplicates.
Fourth problem: Depending on whether the target application uses the library list or the qualified objects, joins will, or will not, integrate the objects library.
Fifth problem: WHLNAM and WHFNAM columns for the library and the referenced object are 11 characters instead of 10, causing some errors in the joins on WHLIB and WHPNAM
Embedding SQL transformation (needed to correct these problems) in the recursive SQL would make the SQL statement not understandable. There are two methods to deal with this problem: Either build a view on jpltools/pgmref, or do an insert into another table. I chose the insert.
Which brings us to this SQL to repackage the PGMREF file:
drop table jpltools.root ;
create table jpltools.root as (
select distinct –- solve duplicates on file name
whlib caller_lib
, whpnam caller
, cast (case
when whspkg ='P' then '*PGM'
when whspkg ='S' then '*SQLPKG'
when whspkg ='V' then '*SRVPGM'
when whspkg ='M' then '*MODULE'
when whspkg ='Q' then '*QRYDFN' end as char(10)) as caller_type
, cast(whlnam as char(10)) called_lib -- resize correctly called
, cast(whfnam as char(10)) called
, whotyp called_type
, cast( '' as char(30) ) caller_key
, cast( '' as char(30) ) called_key
from jpltools.pgmref
where whspkg <> 'M'
) with data including column defaults
;
update jpltools.root set
caller_key = --caller_lib concat -– don't use object lib in join
caller concat caller_type
,called_key = --called_lib concat
called concat called_type
;
The Caller_key and Called_key columns are used to simplify the writing of recursive joins.
It is likely that you already have a scheduled batch job that runs DSPPGMREF. I suggest that you either compile the three samples of SQL above by using CRTQMQRY and then add these three with a repackaging STRQMQRY in the same batch, or copy the three samples of SQL above in a source member and then add one repackaging RUNSQLSTM in the same batch.
Cascading Caller to Called
This recursive SQL takes as root all the lines of repackaged DSPPGMREF (ROOT file). The Title_Caller column is used to keep track of the path and also to detect loops in the recursive calls. The Title_Called column is used to power the previous one. Level column can master the infernal loops and the too-deep analysis.
with cascade (caller, title_caller, called, title_called
, level, called_key) as (
select caller,
cast(trim(caller_lib) concat '/' concat trim(caller)
as varchar(1000) ) title_caller
, called
, cast(trim(called_lib) concat '/' concat trim(called)
as varchar(21) ) title_called
, 1 level
, called_key
from jpltools.root
/* here choose the caller to analyze */
-- where caller='MYPGM'
union all
select
cascade.caller
, cascade.title_caller concat ' > '
concat cascade.title_called
, child.called
, cast(trim(child.called_lib) concat '/'
concat trim(child.called)
as varchar(21) ) title_called
, level + 1
, child.called_key
from cascade, jpltools.root child
where cascade.called_key = child.caller_key
/* here is a loop stopper */
and cascade.title_called not like '% ' concat trim(child.called) concat ' %'
/* here is another loop stopper */
and cascade.level <= 20
/* here choose the called to follow */
--
) select cascade.* from cascade order by title_caller
;
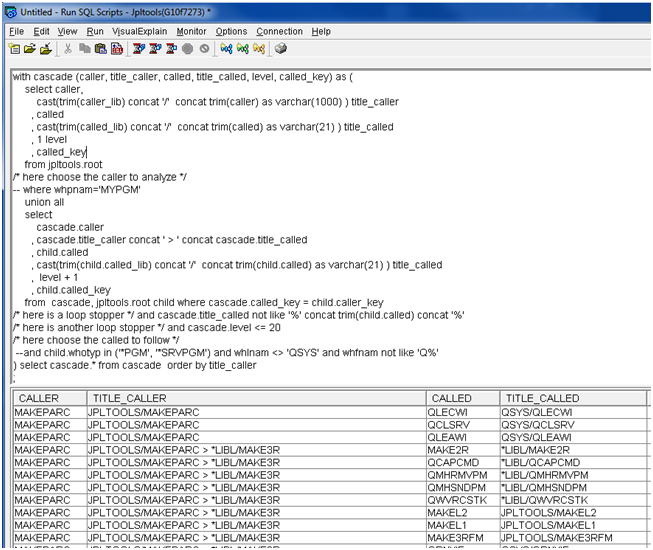
Figure 12: Cascade caller to called.
Now, the same recursion, but the other way. This analysis allows you to, for example, search to find whether a file or program is still present that should have disappeared, understand the impact of a change, or prepare a test plan.
with cascade (caller, title_caller, called, title_called
, level, caller_key) as (
select caller,
cast(trim(caller_lib) concat '/' concat trim(caller) as varchar(21) ) title_caller
, called
, cast(trim(called_lib) concat '/' concat trim(called) as varchar(1000) ) title_called
, 1 level
, caller_key
from jpltools.root
/* here choose the caller to analyze */
-- where whpnam='MYPGM'
union all
select
child.caller
, cast(trim(child.caller_lib) concat '/' concat trim(child.caller) as varchar(21) ) title_caller
, cascade.called
, cascade.title_called concat ' < ' concat cascade.title_called
, level + 1
, child.caller_key
from cascade, jpltools.root child where cascade.caller_key = child.called_key
/* here is a loop stopper */ and cascade.title_called not like '%' concat trim(child.caller) concat '%'
/* here is another loop stopper */ and cascade.level <= 20
/* here choose the called to follow */
) select title_called, called, caller, level from cascade order by title_called
;
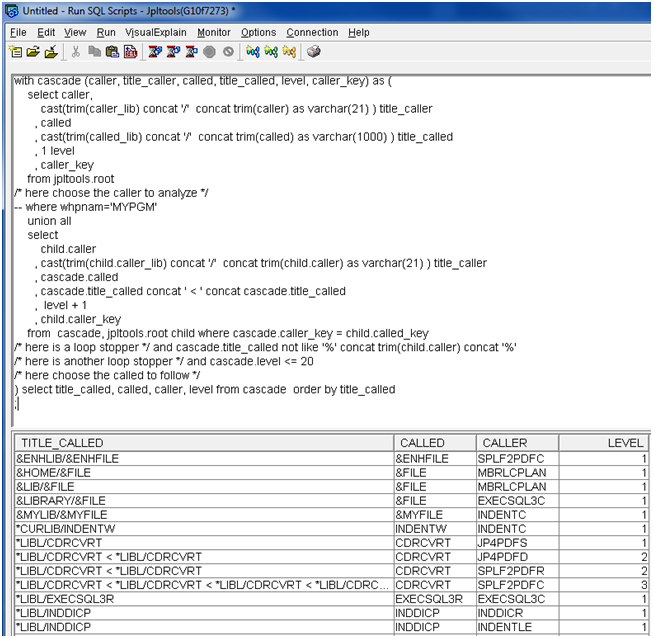
Figure 13: Cascade called to caller.
This SQL statement, which is already complex, suffers from two defects: The lines are not displayed in a particularly consistent order, and the presentation is not very friendly.
Here is the version I used to prepare the analysis to Excel:
with cascade(called, called_type, called_title
,caller, caller_type, caller_title
, level, called_key, caller_key) as (
select
called
, called_type
, called
, called
, called_type
, cast(called as varchar(1000))
, 0
, called_key
, called_key
from jpltools.root
union all
select
cascade.called
, cascade.called_type
, cascade.called_title concat ' < ' concat cascade.caller_title
, child.caller
, child.caller_type
, trim(child.caller) as title_caller
, level + 1
, cascade.called_key
, child.caller_key
from cascade join jpltools.root child on
cascade.caller_key = child.called_key
where
/* here is the loop stopper on recursive call */
cascade.called_title not like
'% ' concat trim(child.caller) concat ' %'
/* here is the loop stopper on too deep analysis */
and cascade.level <= 20
/* here choose the caller type to follow */
--
) --select * from cascade order by called_title;
, ordered as (
select distinct
cascade.called_title concat ' < '
concat cascade.caller_title order_by
, cascade.*
from cascade
) -- select * from ordered order by order_by;
select
case when level = 0 then called_type else '' end "Called Type"
, case when level = 0 then called else '' end "Called"
, level "Level"
, case when level > 0 then caller_type else '' end as "Type"
, case when level > 0 then OBJS.ODOBAT else '' end as "Attribute"
, case when level > 0 then
SUBSTR('. . . . . . . . . . . . . . . . . . . . ',1,ordered.LEVEL*2)
CONCAT ordered.CALLER else '' end AS "Caller"
,Objs.Odobtx "Description"
from ordered
left join jpltools.objs objs on caller = odobnm and odobtp=caller_type
order by order_by
The advantage of iNavSql (iSeries Navigator SQL Editor) is that it offers an easy way to modify and/or adapt queries.
Unfortunately, we can so quickly adapt an SQL statement that often we forget to back it up. The backup is not automatic. And iNavSql stores the previous executions in the message window. This window is not very visible and is erased each time you close iNavSql.
Excel, in contrast, with its minuscule editing window, really does not facilitate the editing of the SQL…if you can retrieve it! It is here:
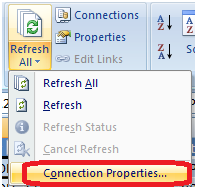
Figure 14: Retrieve SQL connections used into Excel.
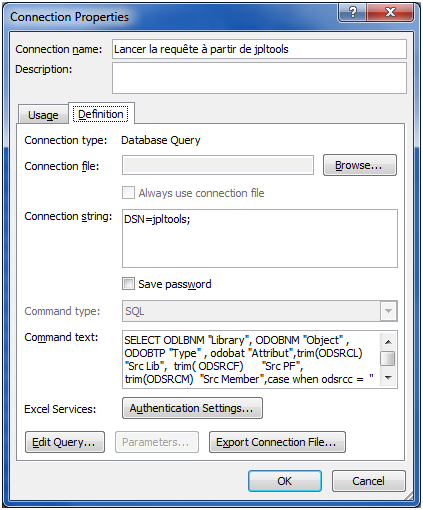
Figure 15: Retrieve SQL statements used into Excel.
Be sure not to confuse the properties of the connection with the properties of the import.
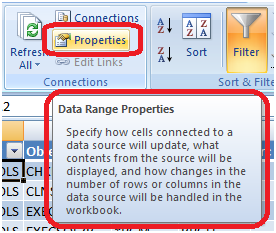
Figure 16: Retrieve the properties of the import process.
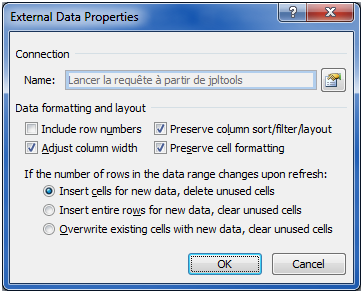
Figure 17: Update the properties of the import process.
These maintenance difficulties are one reason that iNavSql is dedicated to the development of SQL and Excel for use in production.
There's nothing complicated about this next part: When the SQL is developed, each result is in a different tab. After opening the Excel sheet, click here for updated information:
Figure 18: Refresh SQL data into the Excel spreadsheet.
Note that MS QUERY doesn't really try to understand the SQL to execute. That makes it not very tolerant to syntax error. When building the connection, follow this dialogue:
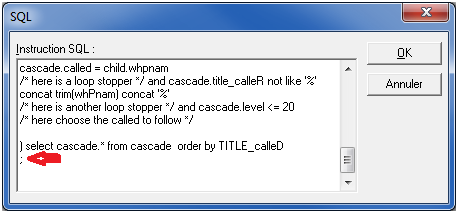
Figure 19: Here's an example of syntax error.
Note the syntax error: The final semicolon (;) is not supported.
The classic error message shown in Figure 20 is followed by the explanation in Figure 21.
Figure 20: Yes, continue!
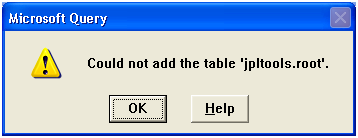
Figure 21: Excel shows the syntax error.
These constraints should encourage you to prepare your application analysis in batch at night and leave the bare minimum SQL in Excel.
But the night batch, with an output file, brings a new constraint: The recursive SQL is a powerful tool based on the common table expression (CTE). But the use of CTE is prohibited in a CREATE AS (SELECT clause) or in an INSERT INTO (SELECT clause). That forbids us from using most tools capable of executing SQL statements here because we want an output file. The only native tools capable of providing output to a file without going through the SQL clauses CREATE AS or INSERT INTO are STRSQL in interactive and STRQMQRY in batch mode.
For example, let's consider the SQL Called to Caller. The QMQRY for the caller list and the called list is available in my toolbox at http://jplamontre.free.fr/jpltools.htm#Index. Follow "The savf with all the sources." Compile with CRTQMQRY:
CRTQMQRY QMQRY(JPLTOOLS/ANZAPCALED) SRCFILE(JPLTOOLS/JPLTOOLS)
Then run it:
STRQMQRY QMQRY(JPLTOOLS/ANZAPCALED) OUTPUT(*OUTFILE) OUTFILE(JPLTOOLS/CALLEDPGM) NAMING(*SQL)
Then, in Excel, just do this:
Select * from jpltools.calledpgm

Figure 22: The simplified SQL goes into Excel.
Presentation is improved. The line order is correct, the called object appears only when changed, and the caller is indented depending on level of deepness.
Note: To be able to use QMQRY with *SQL naming, I had to explicitly qualify the name of the *FILE object. It works. I have found the parameter RDB(*NONE) to specify "use the local database" but nothing to specify "use the current schema."
You now have a complete overview of the opportunities available to you, ranging from the need for response time, which encourages us to prepare the analysis by night, and the need for flexibility, which encourages us to do analysis at the last minute. In our case, knowing that DSPPGMREF is much more efficient when analyzing a library rather than one program at a time, analysis is needed by night.
You have seen how—from system commands DSPOBJD, DSPPGMREF, and DSPFD—it is possible to draw an accurate picture of an application.
In these two articles of this series, you also noticed that some information that could have been provided by DSPPGM remains missing because DSPPGM does not offer OUTPUT (*FILE). In the third article, you will find a program, based on several APIs, that can fill the gap.

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online