








You may be wondering, "Why an article on high availability on an iSeries?" Perhaps, like many of us, you have been running your server for a long time and have never experienced a failure. In fact, you can visit the Legends of iSeries Web page for some amazing iSeries reliability stories. However, server reliability is only one piece of the high availability puzzle. Sure, the iSeries has a 99.94% uptime rating, which equals only 5.2 hours of downtime per year, but true high availability is considered to be "four nines" availability, or 99.99% uptime, which equates to 53 minutes of outage per year. Moving from four to five nines drops the outage time to five minutes per year. Of course, the ideal is continuous availability, or 100% uptime. But the closer one gets to continuous availability, the higher the cost.
According to a 1998 Gartner Group study, the iSeries had the highest uptime rating of any single system, and it remains steadfast in delivering reliable uptime. Only the Tandem (a system designed with built-in hardware redundancy) and IBM Sysplex (a network of multiple zSeries machines) received a higher rating in the study.
Recognizing Downtime, Planned and Unplanned
Studies reveal that most downtime is due to planned outages, such as backups, server hardware upgrades, software/OS upgrades, data warehouse extractions, building and utility maintenance (power, AC), and nightly batch runs that require a dedicated system. For the iSeries, planned downtime accounts for about 90% of all outages. Unplanned downtime (such as power outages, human error, and hardware failure) accounts for only 9%, while disasters (site-wide problems, terrorist attacks, weather, and blackouts) account for less than 1%. See Figure 1.
The goal is to put solutions in place to reduce planned downtime, and as a bonus, you'll be protected against unplanned downtime as well.
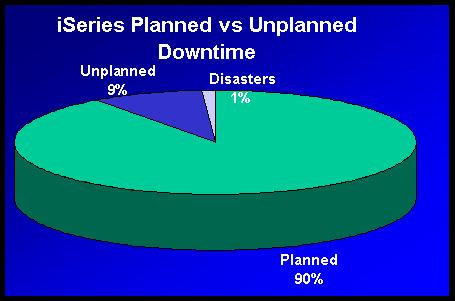
Figure 1: These are the types of downtime your system may experience. (Click images to enlarge.)
Defining Systems and Solutions
Let's look at some of the terminology that is used to discuss high availability. The list below, which came from IBM's HA Web site, goes from the lowest level of protection to the highest.
- Base availability systems are ready for immediate use but will experience both planned and unplanned outages.
- High availability systems include technologies that sharply reduce the number and duration of unplanned outages. Planned outages still occur, but the servers include facilities that reduce their impact.
- Continuous operations environments ensure that there are no planned outages for upgrades, backups, or other maintenance activities. Frequently, companies use high availability servers to reduce unplanned outages.
- Continuous availability environments go a step further to ensure that there are no planned or unplanned outages. To achieve this level of availability, companies must use dual servers or clusters of redundant servers in which one server automatically takes over if another server goes down.
- Disaster tolerance environments require remote systems to take over in the event of a site outage. The distance between systems is very important to insure that no single catastrophic event affects both sites. However, the price for distance is loss of performance due to the latency time for the signal to travel the distance.
Let's further define those terms from an iSeries perspective.
- Base availability systems--for example, an iSeries shipped without disk in RAID sets or disk mirroring
- High availability systems--an iSeries with disk in RAID sets or disk mirroring
- Continuous operations environment--perhaps a Logical Partition (LPAR) box using a high availability solution to mirror to a second LPAR on the same box or using IASP (switched disks)
- Continuous availability environments--usually a two-server environment using either IASP (switched disks) or a High Availability Business Partner (HABP) solution in the same computer room or same building
- Disaster tolerance environments--typically a two-server environment using either SAN replication or an HABP solution with the distance between sites great enough that an event (e.g., power outage, weather, or terrorism) would not affect both sites.
IBM defines a disaster tolerance solution as a combination of redundant iSeries hardware and software consisting of data replication or a clustering solution provided by the IBM HABPs. An HABP solution uses OS/400 journaling, as well as OS/400 save/restore operations. It should include replication automation and management.
HABP solutions fall into two categories: High Availability/Continuous Operations (products that provide the highest availability possible for the iSeries) and Data Recovery/Replication (products that replicate data to a second iSeries server for the purposes of high availability and disaster recovery). For more information on approved HABP solutions, see IBM's HA Web site.
Evaluating Cost and Need
Before you can consider what type of a solution you need, you should look at the costs of downtime for your company, the recovery point objective (RPO), and the recovery time objective (RTO), as shown in Figure 2.
RPO relates to how much data you can afford to lose in an outage. Most shops do a weekly complete save and a nightly backup that may consist of saved changed objects. Additionally, you may be using "save while active" to reduce your save windows. This means that if you had to reload your system, you could only recover to the point of the last backup. So if you perform your backup at 10:00 p.m. every night and you have a failure at 4:00 p.m., your company would have to recreate the data from the point of the save at 10:00 p.m. to the point that your system is available again.
Looking at Figure 2, we see that a tape backup and restore could result in your company being without a computer for 12 to 24 hours or longer. Also, once the computer is back, does your company have a way of recreating/re-entering the data, and what will it cost to accomplish this? Does your company have service level agreements (SLAs) with your customers? If so, is there a penalty? If your system is down, can you meet these SLAs?
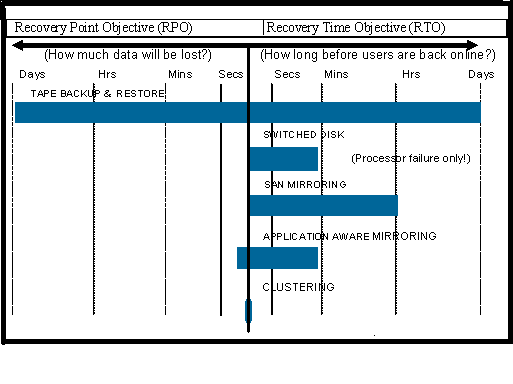
Figure 2: The first step in choosing a solution is to determine your RPO and RTO.
To estimate the costs of downtime, you can use one of the many Downtime Calculators available from the HABP home pages.
Once you calculate the cost of downtime for your business, you should compare it to the cost of implementing a high availability solution. It will be an easy decision to move ahead if the cost of downtime is greater that the cost of deploying the solution. You may need to analyze several years of data to realize an ROI, and you will probably need to consult your financial people to work out the details.
Let's examine the different high availability solutions--from single-server to multi-server solutions.
Single-Server Solutions
The breadth of single-server availability options on the market allow a single iSeries to be as robust as possible. The first four items shown in Figure 4 are hardware solutions. Journaling, on the other hand, is a software solution that includes System Managed Access Path Protection (SMAPP). In fact, even if you implement a multi-server solution, you should also implement the single-server items discussed below.
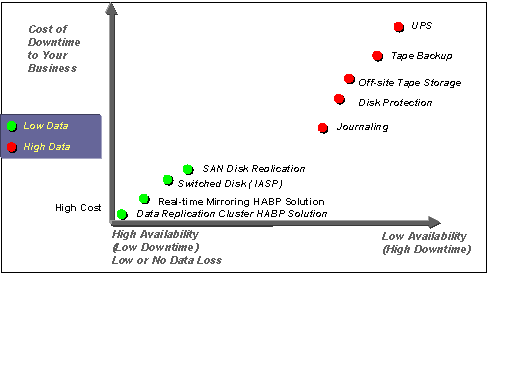
Figure 4: HA solutions are shown in red for single servers and in green for multi-servers.
UPS for Your iSeries
If you do not already have one, consider getting a UPS for your iSeries. You should also investigate sourcing your power to the computer room from different power grids if possible. And don't overlook getting a standby power generator for your UPS. If you go this route, see if your UPS/power generator can power all of your company's critical functions. For example, if you take phone orders; you should ensure that your phone switch is covered by the UPS/power generator.
Also, what about air conditioning, lighting, water, etc.? Will your operators work with only the glow of a green-screen? In one of the shops where I used to work, we did a generator test and found that there was no emergency lighting in the computer room, a situation that was quickly rectified. We discovered this when we scheduled a test involving switching off the public utility power and walking around the building to see which areas had power and which did not.
Author's Note: While I was writing this article, the northeastern United States and parts of Canada experienced the "Blackout of 2003." I was typing on my computer when the power went out and my UPS kicked in. I decided to power down my server. Fortunately, I had no data loss. Overall, we did without power for 20 hours. If you have a success or failure story about the Blackout of 2003, please share it by emailing me at
Backups--Weekly and Daily
The growing requirement for businesses to be up and running 24x7 means that maintenance windows for completing backups and other scheduled tasks are rapidly shrinking. I run across many shops where I am told that there is no time for backups. One side benefit of a replication environment from one of the HABPs is the capability to perform backups of your replicated libraries and IFS objects from the target system either in a true dual-system environment or a secondary LPAR on the same machine.
If you want to maximize the save environment on your existing system, you should investigate the latest tape and IOP technologies. Remember, system memory, IOP, and tape device type can affect save performance. If your tape device is one of the latest, consider increasing backup performance with multiple tape drives, using either concurrent saves or parallel saves. The Concurrent Saves feature, enhanced in V4R1, allows multiple saves against the same library. Beginning in V4R4, parallel saves allow backups to be split across multiple tape drives. Beginning in V5R1, parallel support was enhanced to support special values (*ALLPROD, *ALLTEST, *ALLUSR, *IBM, *ASPxx).
Save While Active (SWA) was also enhanced in V5R1 to achieve faster checkpoints. It does not require any additional hardware or software. SWA provides point-in-time backup and requires that activity against the objects being saved be stopped until a checkpoint is reached.
Now that you have an enhanced understanding of your backup and recovery options, review your backup strategy to see how it can be improved. See the iSeries Backup and Recovery Guide (SC41-5304-06) to fully understand the options presented. Whatever backup strategy you adopt, make sure that you test the restore process, and test often. I once began a disaster recovery test and suddenly found out that the night shift operator was doing a save system and immediately after would initialize the same tape for a save *NONSYS. It was a rather big surprise to find out during the disaster recovery test that there was no save system tape.
Off-Site Tape Storage
If you are making tape backups, ensure that they are moved off-site as soon as possible. If you lose your computer room/building and the tape backups are there, what will you use to restore your system?
Even if you do store your tape backups remotely, review your procedures and determine how quickly and easily these tapes can be retrieved from the backup site in the event of a failure. Many New York City firms learned this lesson the hard way during the attacks of 9/11, discovering that their tape backups were not easily accessible.
After September 11, a hospital located near the World Trade Center learned the value of disaster avoidance the hard way. The hospital's data center was shut down. Computers were destroyed, so data such as lab results had to be entered into charts manually. The hospital didn't have working backups for its communication and air conditioning systems, and its tape backups were not easily accessible. In the weeks following 9/11, the IT staff had to rebuild patient critical care systems, ensure that staff continued to be paid, recover data, install hundreds of new desktop computers, locate and install software, and get ancillary systems and interfaces functioning. And they had to do that while dealing with the crisis of 9/11 itself.
Disk Protection--RAID or Mirroring
Single-level storage is one of the iSeries' greatest features--unless you have a disk failure without disk protection. If you value your data, you should have disk protection, either RAID 5 or disk mirroring. This will allow your iSeries to continue running with a single disk failure in a RAID set or mirrored pair. If two disks fail in the same RAID set or mirrored pair, brew lots of coffee because you're going to have a long recovery.
OS/400 Journaling and SMAPP
Journaling (see Figure 5) provides many benefits and not just for availability. Journaling is the basis for data replication solutions from the HABPs. Improvements over the last few releases include IFS files, the introduction of data areas and data queues at V5R1, and at V5R2, the addition of a purchasable option 42 of OS/400, which provides standby journaling mode and journal caching (formerly the batch journal cache PRPQ). Since journal contents cannot be changed after the fact, journaling also provides a great tool for auditing. Journals can be used for application recovery and debugging as well. If you have never turned on journaling, you should consider using it, especially if you are at V5R1 and above.
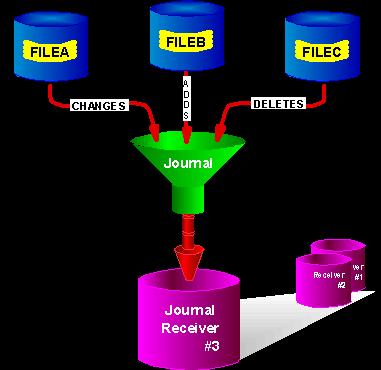
Figure 5: Journaling is a terrific availability tool, but it provides other benefits as well.
SMAPP is on by default. This journaling feature journals access paths so that recovery time after a system failure is greatly reduced. It is an automatic function that determines which access paths to protect without any user intervention. It can be controlled with the EDTRCYAP command and viewed with the DSPRCYAP command.
Journaling Myths
Here are a few journaling myths exposed. They're from the IBM Redbook Striving for Optimal Journal Performance on DB2 Universal Database for iSeries (SG24-6286).
Myth: Journaling consumes up to 25% of CPU.
Truth: CPU overhead is only 2 to 3%.
Myth: Journals are difficult to manage.
Truth: Use system-managed journal receivers for ease of use.
Myth: Journals must reside in a user ASP.
Truth: User ASPs are recommended but not required.
Myth: Batch runs will double.
Truth: In many instances, the batch runs did not double in time, and for those with bad run times, the Journal Cache feature nearly eliminated the penalty.
iSeries Multi-Server Solutions
Multi-server solutions are the basis of continuous availability and disaster tolerance environments. Let's examine the different solutions. One solution is replication, usually from an HABP and two or more servers.
- Storage area network (SAN) solutions provide a simple disaster recovery solution. A second SAN device can receive disk I/O changes, but the second SAN disk copy and iSeries are unavailable for other uses. SANs do not address outages for software or hardware upgrades. They should not be considered a high availability solution because recovery from an unplanned outage can take hours.
- Switched disks (IASPs), new in V5, address unplanned outages but not disaster recovery because the High Speed Link (HSL) cable-length limits restrict the second server to the same site. It will not address save window reductions because only one iSeries can be attached to the disk at a time.
- Continuous data replication solutions require journaling and provide real-time data and object replication to a second system (which can be an LPAR partition). If the servers are located at two different sites, a true disaster recovery solution can be achieved that will address both planned and unplanned outages. The save window can be eliminated by backing up data from the target iSeries. Workload balancing is possible by moving read-only work to the target machine. Many target boxes are used for data warehousing solutions, read-only reports, and/or queries.
Real-World Examples and Best Practices
Let's take a look at how some companies have chosen to implement different levels of availability.
Regional Dairy
A regional dairy in Massachusetts calculated its cost of downtime at $41,666 per hour or a million dollars per day. Their RPO was to lose minimal data, perhaps only the last entered transaction. Their RTO was to be up and running in less than an hour. Additionally, they required the target system to do development work. With these costs and objectives, management approved a high availability mirroring solution. This required a second iSeries server, a hosting location, and an HABP high availability product.
They purchased a second iSeries box to use as the target for replication and as a development system. They made sure the two sites were on different power grids and in different locations. At the end of the project, the IT director said, "We feel protected." They continue to test the switching capability on a regular basis.
Web-Based Sales
This company sells over the Internet to clients around the world. They needed to have continuous operations to keep their Web site up 24x7. It became increasing difficult to do regular backups. They chose to upgrade their system to an LPAR box and bought an HABP solution. They began replication from one LPAR to a second LPAR on the same machine and began doing backups off the target LPAR. This allowed them to achieve continuous operations but not disaster recovery. They plan to eventually buy a second iSeries machine and host it off-site. Once they convert to a multi-server solution, they will have a disaster recovery solution. This example shows how a company can phase in a disaster recovery solution over time.
By the way, during the Blackout of 2003, their UPS kicked in, and they brought all their servers down with out any data loss.
Pharmaceutical Firm
This firm ran an ERP application that was distributed across four iSeries servers. They decided to consolidate the four standalone servers into a single 840 server with four LPARs. Once they had all their eggs in one basket (iSeries server), they bought a second iSeries 840 with LPARs to act as a disaster recovery machine. Using HABP software, they now replicate the production iSeries LPARs to the target iSeries LPARs. They also back up from the target LPARs on the disaster recovery machine. This company accomplished disaster recovery and continuous operations as well as server consolidation in one project.
They also have a UPS and generator, but they discovered during the Blackout of 2003 that they were using more fuel for the generator than expected. When fuel began to run low, they decided to power down their servers
Manufacturing Firm
This company's nightly backups were causing the third-shift manufacturing staff to lose approximately 20 hours weekly. By using HABP software on a single LPAR machine, they accomplished continuous operations. They began replicating from LPAR to LPAR and moved their backups to the target replication environment. This solution gave over 1,000 hours per year back to third-shift manufacturing.
International Bank in NYC
This bank had many NT, UNIX, and iSeries servers. They were interested in a SAN solution to consolidate the disk of the many servers. They also wanted a disaster recovery solution for the entire computer room. They chose to purchase two SANs and locate one off-site. Their RTO required them to be able to switch to their disaster recovery iSeries quickly. Their solution was to purchase an HABP software solution in addition to the SAN. This allowed all the benefits of a SAN along with the benefits of HABP real-time replication.
IBM High Availability Offerings
In September 2003, IBM announced two new iSeries offerings, the iSeries for Capacity Backup and the iSeries for High Availability. IBM wants to provide customers with options to make sure their iSeries boxes are highly available. Both offerings require a net new footprint; therefore, no upgrades are allowed. The Capacity Backup or High Availability server must be equal to or smaller than the production server. But these two offers differ from one another considerably.
The iSeries for Capacity Backup is essentially a hot spare solution intended for companies that require an off-site disaster recovery machine at an affordable price. This offering has a minimum number of active processors. The remaining processors can only be activated in a disaster. IBM has some stringent rules as to what constitutes a disaster. If you meet the requirements, you can turn on additional processors. Three models are included:
- 825 1/6-way, 1250 to 6600 CPW
- 870 2/16-way, 3200 to11500 CPW
- 890 4/32-way, 5600 to 37400 CPW
The startup processors can be used for any workload, including HABP software, or for tape restores. During a qualifying disaster (up to 90 calendar days), the standby processors are deployed with On/Off Capacity on Demand at no additional charge. Included are a fixed number of processor days for testing. The biggest drawback is the unavailability of a permanent activation code for the standby processors.
The iSeries for High Availability offering is meant to support mission-critical, 24x7 5250 OLTP transaction environments. It is an iSeries with full 5250 capability for high availability solutions. There are five models:
- i825 3/6-way
- i870 5/8- and 8/16-way
- i890 16/24- and 24/32-way
Their purpose is to reduce planned downtime with role swapping and/or distributed workloads. In order to qualify to purchase these servers, IBM requires specific high availability software from qualified HABP vendors.
Green Streak for High Availability Offering
Between October 14 and December 31, IBM gave a rebate of up to $40,000, depending on the model 810 purchased as a new IBM eServer iSeries Edition server to be used as a High Availability (HA) redundant target system.
Summing Up
The best level of protection is to have a true disaster tolerance environment. But this solution is expensive and requires two iSeries servers in geographically dispersed locations, with real-time HABP replication software. While this may be too expensive for many shops, it is the best fit when your company has a very low tolerance for server outages. When designing this type of solution, be sure that each server includes the single-server solutions from Figure 4.
The good news is that there are many different levels of HA solutions. Almost no two companies will approach and achieve their high availability solutions the same way.
Do a cost analysis and see how much your company is willing to invest in a solution. Anything is better than nothing, and the more you improve your company's level of uptime, the better your chances of surviving a disaster.
Russ Popeil works for DataMirror, an IBM Business Partner specializing in High Availability software, and has over 20 years experience on the IBM midrange platform. He is immediate past president of the Long Island Systems Users Group and is a frequent speaker at COMMON and other local user groups. He is the author of the book RPG Error Handling Technique: Bulletproofing Your Applications and has also written many articles. He is an IBM Certified Solutions Expert, IBM Certified Systems Expert - iSeries LPAR, and an IBM Certified RPG IV Developer.
 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online