








IBM i TR5 is now available. Learn about the exciting new database enhancements that were delivered in this technology update.
In 2012, IBM i Technology Refresh 5 (TR5) was made generally available. If you're not familiar with the IBM i Technology Refresh approach, think of it as a way for IBM to deliver significant enhancements in between the regular operating system version/release/modification cycles. What originally started as the ability to support new hardware without requiring a new modification level quickly developed into supporting
enhancements in numerous areas. These enhancements to areas such as DB2, systems management, cloud support, Java, and WebSphere are delivered via a packaged set of PTFs. This means you don't have to wait until the next release to get something you may have been waiting for! My kids like to celebrate their "half-birthdays" six months before/after their actual birthday date (well, I should say that they try to anyway). So think of TRs as a half-birthday—one where you get presents!
In all, there are over 25 DB2-related enhancements delivered in TR5. Space limits me from providing you with information on each one of them; as such, I'll focus on the more significant ones in the areas of application functionality and performance.
Application Functionality Enhancements
Several functional enhancements were added to DB2 for i. Both Database Administrators (DBAs) and application developers can benefit from the following functional TR5 enhancements:
- Stored Procedure Support for Named Arguments and Defaults for Parameters
- CREATE TABLE with Remote SUBSELECT
- OmniFind Support for Searching Multi-Member Source Files
- Column-Heading Support for CPYTOIMPF and CPYFRMIMPF
- Support for Both Slash and Dot as Object Qualifiers
- Java Stored Procedures and Functions—System Naming Option
- New QAQQINI Option—SQL_GVAR_BUILD_RULE
- JTOpen Lite and JTLite—Enabling Mobile Devices That Use Java
-
Performance Improvements in SQE
Stored Procedure Support for Named Arguments and Defaults for Parameters
In the past, parameter passing when calling stored procedures could be considered a bit rigid. Any application or interface that called a stored procedure had to specify all of the defined procedure parameters and they had to be in the correct order. This often resulted in the rejection of any enhancement requests that demanded a change in the procedure interface. How so? Well, in many cases you may not know about all of the applications that may be calling a procedure that you maintain. Any proposed procedure enhancements that require the addition of new parameters are immediately met with objection and horror: who knows how many applications you might break if such an expansion were allowed! How can you possibly communicate the necessary changes if you don't know about each and every application or interface that calls your procedure? So those requests were summarily rejected. More-accommodating developers might have attempted some other, more-complex way of getting that information into the stored procedure. However, this often added unnecessary complexity and other potential points of failure. In the end, neither situation was ideal.
So wouldn't it be nice if there were some way to add new parameters without the fear of breaking any existing applications that call the procedure? That's exactly the idea behind named arguments and default values for parameters.
Default values mean that parameters can be added without requiring any modifications to existing applications that call them. If DB2 detects any omitted parameters, it simply uses the defined default value. The following example shows you how to set up default values for parameters:
CREATE PROCEDURE Add_New_Order(
Cust_Name CHAR(40),
Order_Qty INT,
Item_Name CHAR(50),
Order_Number INT DEFAULT (SELECT NEXT VALUE FROM OrderNumbers),
Order_Date DEFAULT CURRENT DATE)
Named arguments mean that parameters can be specified in any order; simply specify the "name" of the parameter you want to pass along with the value. It also allows you to skip parameters and pass values only for specific ones. If you think about it, this is very similar to how CL commands work: you only have to specify values for required parameters that have no default value!
The following example shows you how you can call the stored procedure created above and pass values only for the parameters without default values:
CALL Add_New_Order(
'Fred W. Smith',
88,
'Purple Doorknobs')
This example demonstrates how to call the same procedure and use named arguments to override the default values and mix up the order:
CALL Add_New_Order(
Item_Name=>'Left-handed Crescent Wrench',
Order_Date=> DATE('09/22/2012'),
Ord_Qty=>6,
Cust_Name=>'Edward E. Moore’)
These two enhancements work hand in hand to simplify things. Consider if you have a stored procedure that has 20 parameters. You want to call this procedure from your application, but you really only need to pass values for the first, third, and 20th parameter. The rest can use the configured default values. With defaults and named parameters, now you don't need to pass values for the other 17 parameters! Pretty neat stuff!
Lots of good information on these particular enhancements can be found in Kent Milligan's recent TechTip.
CREATE TABLE with Remote SUBSELECT
Another enhancement that can greatly simplify things for application developers and DBAs is the remote subselect feature for both the CREATE TABLE and GLOBAL TEMPORARY TABLE statements. This feature allows these statements to be based upon a table on a remote database. The table is created on the local system, but its format is based upon tables on a different system or partition. The WITH DATA clause can be included to bring the data over and add those rows to the local database. It's an extremely useful way to move data from one database to another.
This new feature utilizes the three-part naming capability that was added in V7R1 to identify the remote database, schema (library), and table name. A simple example is provided below.
CREATE TABLE MYLIB.ORDERS AS
(SELECT ORDERNUMBER, ORDERDATE, STORECODE, PRODUCTNUMBER
FROM LP12UT21.QWQCENT.ORDERS)
WITH DATA
Before the remote subselect capability, if you wanted to move data across a system or partition, you had to create a savefile, save the table to the savefile, use FTP to transfer the save file over to the target system, and finally restore the save file. Now all of this can be accomplished with a single SQL statement!
You can almost think of this as a "poor man's" ETL (Extract, Transform, and Load) process. You could further enhance the subselect portion of the SQL statement to perform specific aggregation and filtering, join multiple tables together, and even pivot the data. One SQL statement may be all you need to pull the data over, "massage" it, and get it in the correct format in the target database!
Incidentally, INSERT with subselect was actually available in TR4. This same ability on CREATE TABLE effectively completes this solution.
OmniFind Support for Searching Multi-Member Source Files
One of the hidden gems on the IBM i is the OmniFind Text Search Server. First made available in V6R1, this powerful searching technology provides a way to perform advanced linguistic (think "Google-like") text searching within your database columns, binary data stored in either database LOB columns or the IFS, and even spooled files.
For example, with OmniFind you can find all occurrences of the phrase "I should have turned left at Albuquerque" (including a variety of linguistic variations) in all of these types of data sources. Missing, however, was one rather prominent IBM i data source: source physical file members. But you guessed it: with TR5 you can now use OmniFind to perform advanced linguistic searching over your application source code!
If you'd like to learn more about OmniFind, here are two useful links:
- OmniFind, Part I: Add Sizzle to Your SQL with OmniFind Text Search Server for DB2 for i
- Exploring the IBM OmniFind Text Search Server
Column-Heading Support for CPYTOIMPF and CPYFRMIMPF
Two very useful commands on the IBM i are CPYTOIMPF and CPYFRMIMPF. DBA and developers use these commands as an efficient way to safely move data from a file on the IFS (such as a spreadsheet) to a DB2 table (and vice versa). One complaint has always been the lack of column-heading support. Why can't CPYTOIMPF access the table's column names and bring them over to the spreadsheet to use as the headings for each column? This great idea from our customers was implemented in TR5. A new optional parameter has been added to the CPYTOIMPF command to indicate whether the column names should be included as the first row in the target import file. Here are the possible values for the new ADDCOLNAM parameter:
- *NONE—No column names are used. This is the default value.
- *SQL—The SQL names of the columns will be used to populate the first row.
- *SYS—The system names of the columns will be used to populate the first row.
Similarly, the CPYFRMIMPF command was enhanced and now includes a parameter to indicate whether the first row should be skipped when copying data from the import file to the target DB2 table. If the import file has column headings, you usually do not want to bring this information over as a row in the target table. Consequently, you want to instruct the command to skip this first row, and now you can with the new RMVCOLNAM parameter! The possible values for RMVCOLNAM are as follows:
- *NO—Do not skip the first row. This is the default value.
- *YES—Skip the first row of data. This will prevent the columns' headings from being imported into the target table.
Support for Both Slash and Dot as Object Qualifiers
When making explicit database object references, you have two naming options:
- System naming—A slash (/) is used to separate the schema (library) and the object.
- SQL naming—A period, or dot, (.) is used to separate the schema (library) and the object.
The one used is typically a matter of preference and usually based upon the person's background. Those of us with more experience on the IBM i likely are going to prefer the slash as it's consistent with the object qualification scheme used in CL commands. If you came from an SQL background, the dot is probably your object separation symbol of choice.
In either case, having two naming schemes may have caused headaches in the past. If you were porting new SQL code into your application and SQL naming was used in that code, you had to change all the dots to slashes to make it work in a system naming environment.
In TR5, the system-naming convention has been expanded to allow both slashes and dots. This change makes it much easier to continue using system naming convention; any imported SQL text does not need to be updated! In fact, you can even mix and match the two conventions in the same statement. For example, the following statement would be accepted:
SELECT B.COUNTRY, A.LINETOTAL
FROM QWQCENT/ORDERS A
INNER JOIN QWQCENT.STORES B ON A.STORECODE = B.STORECODE
This enhancement also solves a bugger of a problem that many have encountered in the past: the inability to explicitly qualify a User-Defined Function (UDF) using the slash in system-naming mode. Since this was not supported, you were forced to use SQL naming to reference a function in a specific library. Simply changing it to SQL naming may have been problematic if the application had system-naming dependencies. The DB2 Web Query product is a good example this. It uses system naming for various reasons, but there was a need to reference a function in a specific library; this enhancement solved that problem as we are now able to use a dot to explicitly reference the needed function and remain in system-naming mode.
One important thing to keep in mind: This enhancement does not mean that system naming now behaves in the same manner as SQL naming. System naming still uses the library list when searching for unqualified object references, whereas SQL uses the path or the current schema.
Java Stored Procedures and Functions—System Naming Option
Another useful system-naming improvement in TR5 is the ability to specify the system-naming convention in the native JDBC driver. A new method named setUseSystemNaming(true/false) can be used to turn system naming on or off in Java stored procedures and functions. For those of you who have been frustrated in the past when trying to implement library list behavior in your Java code, this enhancement may result in a boisterous shout of "Woohoo!"
New QAQQINI Option—SQL_GVAR_BUILD_RULE
Global variable support was a feature added in V7R1 that provided a simple way of sharing values across all of the various SQL statements and SQL objects (such as views, triggers, and stored procedures) within a job or database connection. If you have ever used global variables within an application, you may have deployed the application to production only to have it fail during execution with an SQL0312 error (Variable not defined or not usable). After a considerable amount of time spent debugging, you discover that a global variable that was being referenced within the application did not exist at runtime (perhaps it was created dynamically in some other process in your application). Argh! Wouldn't have been nice to detect that error earlier, before it reached your customer (more specifically during your build process)? A new QAQQINI option named SQL_GVAR_BUILD_RULE gives you this capability. This new rule is used to enforce whether or not global variables must exist during the build of SQL routines or execution of SQL precompiles. Valid values for this option are as follows:
- *DEFAULT—The default value is set to *DEFER.
- *DEFER—Global variables do not need to exist when an SQL routine is created or the SQL precompiler is run.
- *EXIST—Global variables referenced by SQL must exist when the SQL routine is created or the SQL precompiler is run. Failure of this condition will result in generation of error SQL0206 during creation time.
Note: This option has no effect on dynamic SQL statements.
JTOpen Lite and JTLite—Enabling Mobile Devices That Use Java
The ability to build and deploy applications that run on mobile devices and access objects on an IBM i server is likely of interest to many companies. One of the requirements of mobile computing is a relatively small resource footprint without sacrificing application performance. Both the JT400 and JTOpen Java toolkits can be used for this type of application development; however, their resource requirements were often prohibitive.
New in TR5 are JTOpen Lite and JTLite, lightweight Java classes optimized for usage on mobile devices. The objective of these classes is to provide Java application access to native IBM i and IFS objects (using interfaces such as DDM, JDBC, and program calls) without requiring an excessive amount of resources. In fact, only approximately 420K of storage is required on the mobile device.
While these new classes are a great fit for mobile devices, they can be used anywhere a lighter footprint is desired. For example, ISVs can use them to keep their running application size on the IBM i smaller.
The JTOpen Lite/JTLite project can be accessed here.
Performance Enhancements
TR5 included multiple improvements in the area of database performance and analysis. Some of the more useful ones include the following:
- SQE Enhancement for Encoded Vector Indexes Defined with INCLUDE
- Improved Show Statements Filtering
- Index Advisor Show Statements—Improved Query Identification
SQE Enhancement for Encoded Vector Indexes Defined with INCLUDE
Index-Only Access is a very powerful feature that has been in the SQL Query Engine (SQE) from the beginning. It simply means that if all the columns (referenced in a query request) are in the index itself, the DB2 optimizer does not have to access the underlying table to retrieve that data. By eliminating the table access step, significant query performance improvements can be achieved.
TR5 expands this capability to Encoded Vector Index (EVI) technology by providing Index-Only Access for queries that use grouping set constructs such as CUBE, ROLLUP, and GROUPING SETS. This is accomplished by utilizing the EVI INCLUDE, a feature first made available in V7R1 that allows you to specify aggregated measure columns in the EVI definition and have those values stored in the EVI's symbol table. These aggregates are maintained immediately and automatically, a significant benefit over other techniques such as an aggregate Materialized Query Table (MQT). Now, in TR5, whenever a query that contains one of the SQL Grouping Set constructs is executed, the optimizer can extract that information directly from the EVI symbol table. The result is EVI Index-Only Access for these more-complex types of queries—real-time information and faster performance!
Here's an example of creating an EVI with the INCLUDE:
CREATE ENCODED VECTOR INDEX QWQCENT.ORD_EVI01 ON QWQCENT.ORDERS
(YEAR(Orderdate) ASC,
QUARTER(orderdate) ASC,
MONTH(orderdate) ASC)
INCLUDE (SUM(QUANTITY) , SUM(linetotal), COUNT(*) );
The following SQL statement includes a GROUPING SETS function and requests aggregate information for the QUANTITY and LINETOTAL columns.
SELECT YEAR(orderdate) as year, QUARTER(orderdate) as quarter,
MONTH(orderdate) as month, SUM(QUANTITY) AS TOTQUANTITY, SUM(linetotal) as TOTREVENUE
FROM qwqcent.orders
GROUP BY GROUPING SETS ((YEAR(orderdate), QUARTER(orderdate),
MONTH(orderdate)), (YEAR(orderdate),QUARTER(orderdate)),
(YEAR(orderdate)), ( ));
To verify EVI Index-Only Access, this query was executed and a Visual Explain session was captured to graphically display the access plan. This is shown in Figure 1.
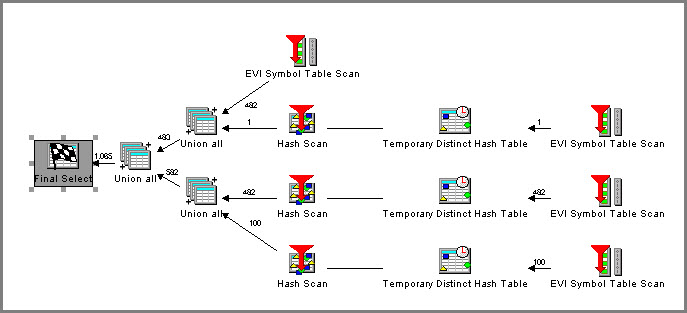
Figure 1: Visual Explain verifies EVI IOA.
Notice in the above access plan that no reference to the underlying table (QWQCENT.ORDERS) was made. No table probes or tables scans were required; all of the information needed to satisfy this complex query was extracted from the EVI Symbol Table. EVI Index-Only Access has occurred!
Improved Show Statements Filtering
Several improvements were added to the database's graphical interface: IBM i Navigator. One of my favorites was a feature that improves the ability to find information about specific SQL statements that were executed on the system. If you have ever used the Show Statements option to view statements in an SQL Performance Monitor, the SQL Plan Cache, or an SQL Plan Cache snapshot, you are likely familiar with the filtering capability in the Statement dialog window. It allows you to find specific statements based on filters such as the object or schema referenced, minimum runtime execution, and the user who ran that request. In all, there are more than 10 filtering options. If you specified multiple filtering options and no results were returned, you might have come away perplexed as you were certain at least one of those filters would have yielded a match. What happened? Well, the filtering logic in the past always ANDed together all of the options. This meant that all the filters had to be satisfied, not just one. TR5 has addressed this common frustration by adding a capability to specify OR logic to the specified filters. Now only one condition need be satisfied to display the matching statements. An example of this new option is shown in Figure 2.
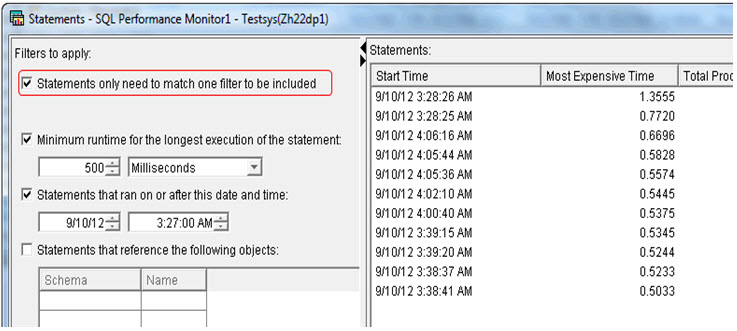
Figure 2: New OR logic can be applied to filters.
Index Advisor Show Statements—Improved Query Identification
Another powerful analysis tool in IBM i Navigator is the Index Advisor. It displays information gathered by the DB2 for i optimizer during its query plan optimization process. During this process, the optimizer determines whether the query plan would benefit if an index were built over a specific table and column(s). If so, the optimizer issues an "Index Advisory" and stores this information in a system table where it can be displayed using the Index Advisor interface. From there, an analyst could display the statement(s) in the SQL plan cache that generated that specific selected advisory—or could it? One of limitations of this interface in the past was its lack of precision: it retrieved and displayed any statement in the plan cache that referenced the selected table and had an index advisory issued against it. This meant you were presented with statements that were not necessarily based on the specified advisory entry that was selected.
Analysts that have TR5 installed will notice a significant improvement in this area. The Show Statements retrieval process is much more surgical, showing only statements that exactly match the selected advisory entry. The new matching criteria used includes the keys advised, leading order independent keys, NLSS table, NLSS schema, index type, partition name, and page size.
This and Much More!
As mentioned previously, only a subset of the TR5 enhancements is covered in this article. More information on Technology Refresh updates can be found on the IBM developerWorks Web site. For TR5-specific information, follow the links for Group 15 and 16 enhancements and Group 18 enhancements.
All of these new features and you don't even have to install a new release! So how to you get all of the goodies? Well, first you must be at V7R1 of the IBM i operating system. Then download and apply the database group PTF SF99701 Level 19. What are you waiting for?

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online