








Discover the advantages offered by full-text search capabilities in modern applications.
In modern IT infrastructures, data stored in DB2 for i is often accessed and interpreted using web interfaces. In order to be successful, these interfaces need to be simple to use and still deliver exceptional value. For some applications, a necessary step in making this a reality is searching and ordering unstructured text data that is stored in a database column, using user-provided search terms. This article presents a sample human resources web service that needs text search capabilities and explains how to implement text searches using embedded SQL within an RPG procedure.
Full text search using DB2 for i requires that OmniFind Text Search Server for DB2 for i (5733-OMF) be installed. Although the OmniFind product is provided at no additional charge, it's not shipped as part of the base operating system and must be ordered separately (product 5733-OMF). OmniFind Text Search Server for DB2 for i is available starting with DB2 for i 6.1. Additionally, the capabilities of the product have been significantly enhanced in the V1R2 release available for DB2 for i 7.1.
Figure 1 illustrates an example SQL schema; a human resource department might use this schema to recruit prospective new employees. For simplicity, this model assumes that each applicant has a name and resume, and applies for exactly one position in the company. The resume column in the applicant table is a BLOB column that contains the applicants' resumes; the resumes are stored as unstructured text, using common formats such as Microsoft Word, PDF, OpenOffice, Rich Text Format (RTF), etc. The position table contains the title, department, and a unique job code for each position.

Figure 1: This is the RESUME_APP schema for a human resources application.
Using this model, it's straightforward to write an SQL query that returns all of the applicants that have applied for a specific position in the company. Listing 1 shows an SQL query that that could be utilized within a web service. The query returns applicants that have applied for a specific job (using the job's code). The result set contains columns for the applicant's name and a URL that might be used by the user of the service to retrieve the applicant's resume. This example assumes that the web service to retrieve the resume document already exists and that the URL for the service has the form http://www.example.com/applicant_resume/applicant_id where applicant_id is the applicant_id column's value from the applicant table.
SELECT
applicant.name AS "Applicant Name",
'http://www.example.com/applicant_resume/' ||
CAST(applicant.applicant_id AS VARCHAR(10)) AS "Resume URL"
FROM resume_app.applicant applicant
INNER JOIN
resume_app.position job USING (position_id)
WHERE
job.job_code = 'JB001'
ORDER BY applicant.name ASC;
Listing 1: The SQL query returns applicants for job 'JB001'.
Figure 2 shows a sample set of results for the query in Listing 1. It's easy to see that this SQL query is not going to provide results that will satisfy a user of the service. The query returns such a large number of applicants that it would be impossible to review all of the resumes. In addition, the alphabetical ordering of the results is not helpful in determining the best candidates for the position.
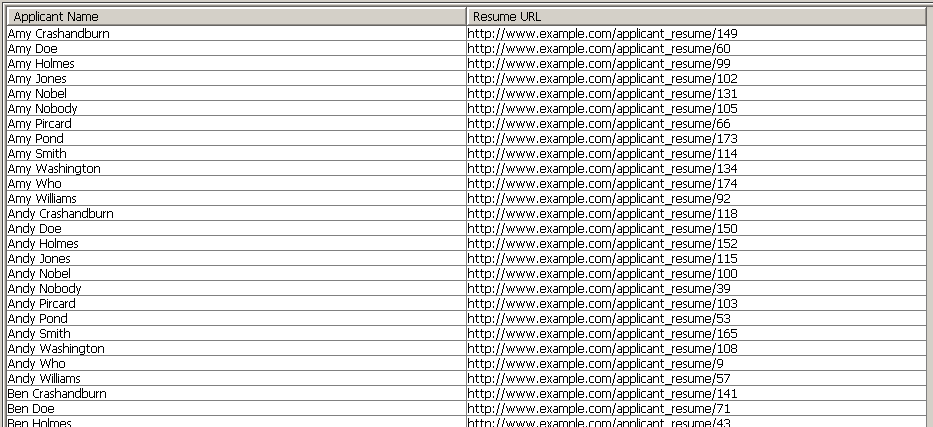
Figure 2: The results from SQL query in Listing 1 are not specific enough to be helpful.
The query would be much more usable if it included the capability to return only the rows with resumes that matched some keywords that are supplied by the user of the service. A query that ordered the resulting rows by relevance to the keywords would be even more powerful.
Searching the unstructured text contained within the resume documents and ordering the results requires some advanced capabilities. To understand why, consider a search for variations of the phrase "Agile Methodology." A typical user would expect both of the documents shown in Figure 3 to match this search. Matching these documents is non-trivial; the resume on the left (for an applicant named Frances Allen) is a PDF and contains only a variation on the word Methodology (Methodologies). The document on the right (for an applicant named Edgar Codd) is a Microsoft Word document and uses a very different document layout for similar information.
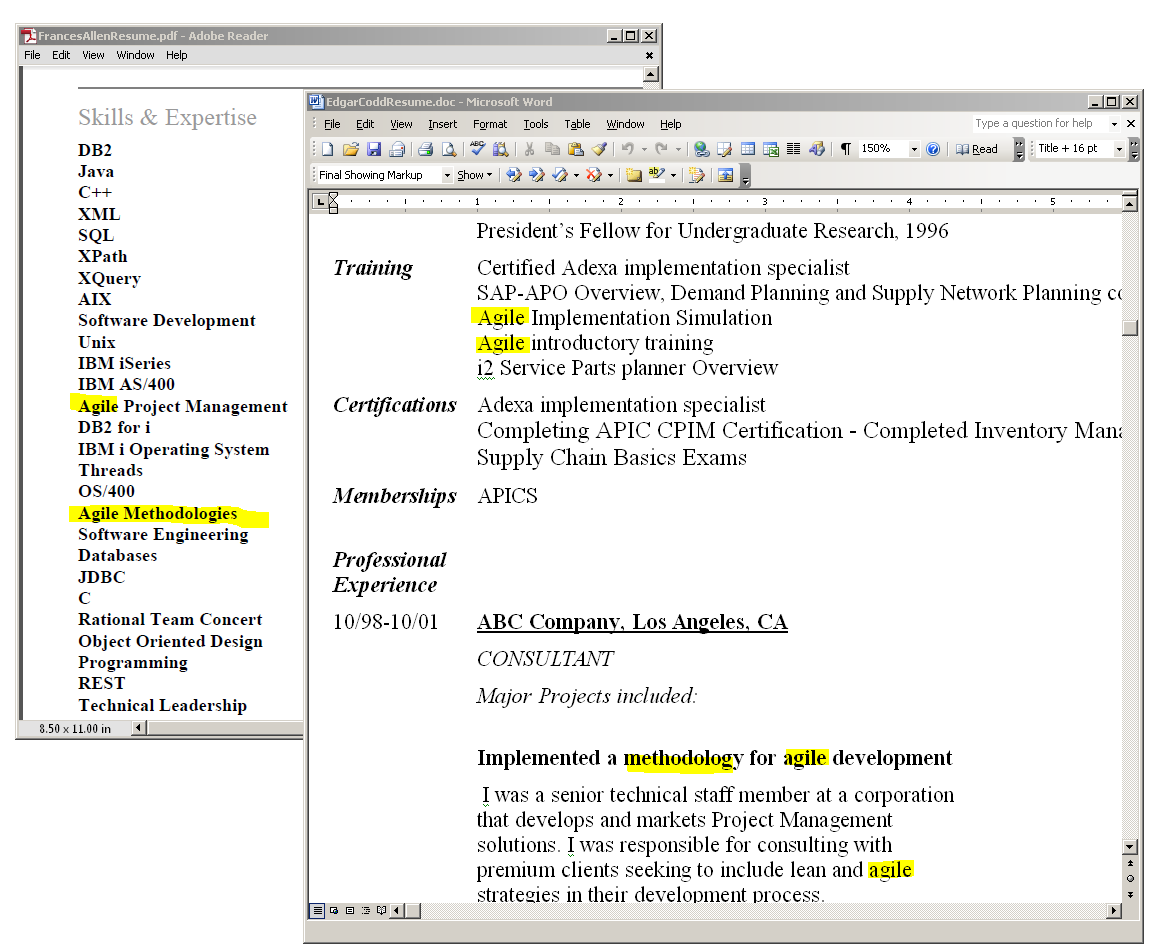
Figure 3: Both documents contain the keywords "Agile" and "Methodology."
This is where the OmniFind Text Search Server for DB2 for i product shines. OmniFind implements the SQL built-in CONTAINS and SCORE functions for searching these documents and ordering the results by relevance.
In order to use the CONTAINS and SCORE functions to perform searches and orderings, a text search index must first be created and updated. This setup can be performed using IBM i Navigator, or in SQL, using the SYSTS_CREATE and SYSTS_UPDATE stored procedures. Due to the performance considerations of the indexing process, text search indexes are not immediately maintained; however, a text index can be either explicitly updated or scheduled to automatically update on a regular basis. IBM STG Lab Services has published a white paper that discusses the necessary steps for creating and configuring a text index.
For this example, a text search index was created over the resume column, and an update was performed using the SQL statements shown in Listing 2. When the index was created, the FORMAT INSO option was used to indicate to OmniFind that the column contains "rich text" documents such as Microsoft Word, RTF, PDF, OpenOffice, etc. The update process will then automatically extract the text from the documents for indexing.
CALL SYSPROC.SYSTS_CREATE('RESUME_APP',
'RESUME_IDX',
'RESUME_APP.APPLICANT(RESUME)',
'FORMAT INSO');
CALL SYSPROC.SYSTS_UPDATE('RESUME_APP', 'RESUME_IDX', '');
Listing 2: These SQL procedure calls create and update a text search index.
Once the index has been created and updated, the SQL CONTAINS function can be used to search the documents for keywords. The CONTAINS function returns a value of 1 if the document matches the keyword or a 0 if it does not.
While the CONTAINS function indicates whether a document matches a search phrase, the SCORE function can be used to determine how well a document matches the search phrase, in comparison to other documents in the index. The value returned will be between 0 and 1, where 0 is not at all relevant and 1 is extremely relevant. The actual result of the SCORE function is usually used only for ordering search results by relevance; the score value is not meaningful by itself.
Listing 3 shows how the SQL query in Listing 1 can be modified to incorporate the CONTAINS and SCORE functions.
SELECT
applicant.name AS "Applicant Name",
SCORE(applicant.resume, 'Agile Methodology') AS "Score value",
'http://www.example.com/applicant_resume/' ||
CAST(applicant.applicant_id AS VARCHAR(10)) AS "Resume URL"
FROM resume_app.applicant applicant
INNER JOIN resume_app.position job USING (position_id)
WHERE job.job_code = 'JB001' AND
CONTAINS(applicant.resume, 'Agile Methodology') = 1
ORDER BY SCORE(applicant.resume, 'Agile Methodology') DESC;
Listing 3: This SQL query uses CONTAINS and SCORE to filter and order the results.
Figure 4 shows the results of the query that was shown in Listing 3. In comparison to Figure 2, the result set includes only the relevant rows, and the most relevant rows appear first in the result set.
![]()
Figure 4: Listing 3 delivers these results.
Embedding the query in Listing 3 into a CGI program that exports the results shown in Figure 4 as HTML is a straightforward task. Listing 4 illustrates an RPG procedure that could be used as part of a CGI program. The procedure takes two parameters as input: a job code and search string. The procedure in Listing 4 runs an SQL query and returns the results as a string containing HTML code. In the result string, each row from the result set becomes a row in an HTML table. For simplicity, the example ignores some trivial tasks, such as escaping characters with special meanings for HTML (such as '<') in the output string.
The most interesting bit of code in Listing 4 is the APPLICANTS_CSR cursor, which is defined in a similar way as the query shown in Listing 3. Using static SQL improves performance by preparing the query at precompile time. In addition, the use of host variables reduces the risk of problems due to malevolent user-provided search phrases. Unlike the query in Figure 3, the score value is used only for ordering and does not appear in the result set; this is because the exact score value is not meaningful to the user of the service.
*****************************************************************
*Implementation of a Function to do a search
*****************************************************************
P doSearch B
D PI 16000A varying
D SqlJobCode 5A const
D SqlSearchStr 255A varying const
D ApplicantNM S 200A varying
D URLForResume S 4096A varying
D resultStr S 16000A varying
* CRLF is a newline character
D CRLF C x'0d25'
/free
// These DECLARE statements tell SQL what the ccsid of the
// input or output character variables will be.
EXEC SQL DECLARE :SqlSearchStr VARIABLE CCSID 37;
EXEC SQL DECLARE :URLForResume VARIABLE CCSID 37;
// define the cursor that is used to retrieve the results
EXEC SQL DECLARE APPLICANTS_CSR CURSOR FOR
SELECT applicant.name,
'http://www.example.com/applicant_resume/' ||
CAST(applicant.applicant_id AS VARCHAR(10)) AS url
FROM resume_app.applicant applicant
INNER JOIN resume_app.position job USING (position_id)
WHERE job.job_code = :SqlJobCode AND
CONTAINS(applicant.resume, :SqlSearchStr) = 1
ORDER BY SCORE(applicant.resume, :SqlSearchStr) DESC;
// open cursor
EXEC SQL OPEN APPLICANTS_CSR;
// Initialize result with an HTML table tag and headers
resultStr =
'<b> Job Code: </b><I>' + SqlJobCode + '</I><BR/>' + CRLF +
'<b> Search Phrase: </b><I> ' + SqlSearchStr + '</I><HR>' + CRLF +
'<table border=1>' + CRLF +
'<tr><td><b>Applicant Name</b></td>' +
'<td><b>Resume URL </b></td></tr>' + CRLF;
// fetch first row
EXEC SQL FETCH APPLICANTS_CSR INTO :ApplicantNM, :URLForResume;
///////////////////////////////////////////////////////////////////
// Loop over each row that is retrieved from the cursor until no
// more rows.
// For each row, build a string with HTML code for the table's row
///////////////////////////////////////////////////////////////////
DOW SQLCOD = 0;
resultStr = resultStr +
'<tr>' + CRLF +
' <td>' + ApplicantNM + ' </td> ' + CRLF +
' <td><a href="' + URLForResume +
'"> Resume </a></td>' + CRLF +
'</tr>' + CRLF;
// fetch next row
EXEC SQL FETCH APPLICANTS_CSR INTO
:ApplicantNM, :URLForResume;
ENDDO;
// close cursor
EXEC SQL CLOSE APPLICANTS_CSR;
// close HTML table tag
resultStr = resultStr + '</table>' + CRLF;
// return results
return resultStr;
/end-free
P E
Listing 4: RPG procedure to perform search and return the results as an HTML table
Figure 5 shows how the HTML string that is returned by the procedure in Listing 4 might appear in a web browser.
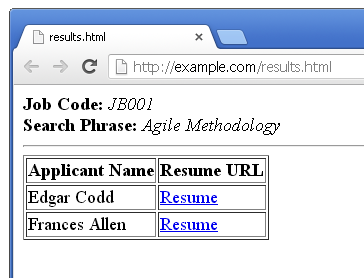
Figure 5: Here's the web-browser view of the result from the RPG procedure.
An important idea is that the CONTAINS and SCORE functions are understood by the DB2 for i optimizer; thus, the optimizer knows how to optimize the SQL query with them in mind.
Figure 6 shows a "visual explain" for the SQL query that ran within the RPG function shown in Listing 4. In this query, the DB2 for i optimizer was able to combine the CONTAINS and SCORE function calls into a single SCORE call and was further able to rewrite the query so that the function call was implemented as a table function. In this example, the optimizer has determined that the join between the applicant table and the table function is faster than a scalar function call for each row in the applicant table. The ability of the optimizer to optimize an SQL query that involves a full text search is a strong motivation to use the built-in CONTAINS and SCORE functions, rather than external solutions for which the optimizer has no awareness.
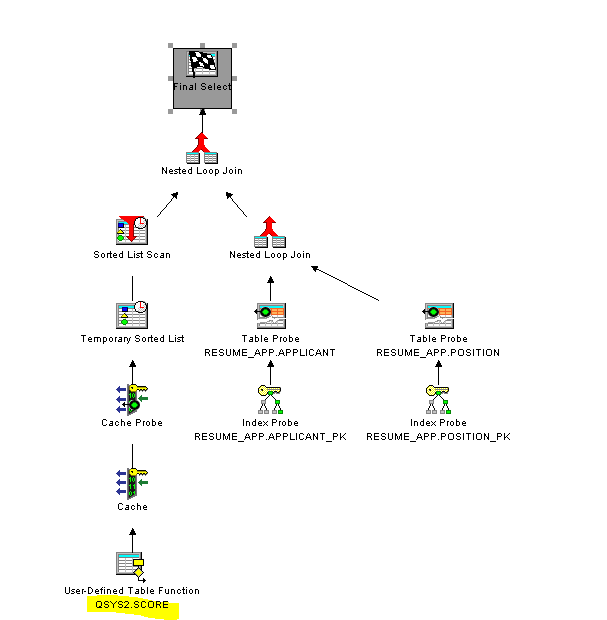
Figure 6: Visual explain shows how the CONTAINS and SCORE functions have been optimized.
This article has shown why text search capabilities can be an advantage and how these capabilities can be integrated into an application by using DB2 for i and OmniFind Text Search Server for DB2 for i. The OmniFind Text Search server product provides an efficient way to index and search text data in a database column, even when that data is stored in rich text documents such as Microsoft Word or PDF.
It's also worthwhile to look at the OmniFind documentation in the Information Center.
You'll also benefit from looking into the new functionality that was added to OmniFind Text Search Server for DB2 for i 7.1. OmniFind V1R2 and DB2 for i 7.1 add extensive capabilities for searching XML data. In addition, there are new capabilities to index Integrated File System (IFS) stream files (also called UNIX or PC files), members of source physical files, and spooled files. The following links are for articles that provide more details on these topics:
Customers interested in the latest and greatest enhancements for OmniFind may find the resources on DeveloperWorks interesting.

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online