









Walk through a real-world scenario of how Aaron Bartell approaches changes to open-source projects.
In a recent blog post, Jesse Gorzinski, Business Architect - Open Source on IBM i, focused on the "Power of Community." The community is the only way open source not only survives but thrives. There's a lot of activity in IBM i open source right now, and I hope that trend continues.
One aspect that kept me from originally participating with open source is I didn't know how to interoperate with the community and participate in changing code repositories. This article documents a real-world scenario where a community member, Magne Kofoed, posted on the OpenSource Midrange.com forum a need to pass parameter names on RPG calls from the Node.js iToolkit. As you can see from the thread, I didn't think the feature was available, and it turns out I was wrong…well, partially wrong. The Node.js iToolkit wrappers the XMLSERVICE tool and XMLSERVICE supports the passing of arbitrarily created metadata attributes, but the Node.js iToolkit didn't yet support that feature. Magne then formally logged the feature request here in the Node.js iToolkit repo's Bitbucket Issue tracker and assigned it to yours truly. So I figured I'd take a swing at the changes with a slightly different approach than I had taken with previous ones.
In a previous article, I documented how to add unit tests to the Node.js iToolkit project, and in that article I changed the repository directly, which I can do because I am a core committer. This means I have permissions on Bitbucket that allow me to write to the repository; it is not open to be written to by just anyone. Well, in this case I am not adding unit tests and instead changing foundational code in the repository, so I wanted to tread a little more lightly. What I did instead is forked the repository with subsequent plans to issue a pull request so the other core committers, IBMers, could review my changes before accepting them. I could have also gone the route of putting this in what's a called a Git "feature branch," but I wanted to show how non-core-committers would need to do this, so forking it is! I documented how forking works in this article, so I won't be covering that again here.
My forked repo is here: https://bitbucket.org/aaronbartell/nodejs-itoolkit. You can tell it is my personal fork because it has "aaronbartell" instead of "litmis" in the URL. Obtaining the code down to my IBM i is as simple as the following.
$ git clone
$ cd nodejs-itoolkit
Before going further, it's necessary to describe exactly what the result should look like, as shown below. Look specifically at the second pgm.addParam statement, which adds in the name attribute. According to the current documentation for addParam, there isn't an attribute titled name that exists for the optional object that can be passed. What we want is for this attribute of name to be returned on the response so we can correctly identify the result fields instead of relying on positional relation.
var xt = require('/QOpenSys/QIBM/ProdData/OPS/Node6/os400/xstoolkit/lib/itoolkit');
var conn = new xt.iConn("*LOCAL");
var pgm = new xt.iPgm("PGM1");
pgm.addParam("Gill", "10A");
pgm.addParam("", "10A", {"name":"FIRSTNAME"});
conn.add(pgm);
conn.run(function(str) {
var results = xt.xmlToJson(str);
console.log(results[0].data[1].name);
});
In the above code, you can see the accessing of results[0].data[1].name, which is testing whether the process worked. And below is what the call to xt.xmlToJson(str) should produce once my changes are implemented. Note that the "name": "NEW_NAME" portion is what needs to be added.
[
{
"type": "pgm",
"success": true,
"pgm": "ZZSRV6",
"lib": "XMLSERVICE",
"data": [
{
"value": "Gill",
"type": "10A",
},
{
"value": "my name is Gill",
"type": "20A",
"name": "NEW_NAME"
}
]
}
]
At this point, it's time to dive into the Node.js iToolkit code and determine what needs to be changed. How do we know where to look? Well, going back to the code sample above, we can see the .../lib/itoolkit.js file (extension of .js not necessary on require statement) being assigned to the xt variable. Then we see xt.iPgm is used to create the pgm object, which is in turn used on the call to pgm.addParam. That leads me to think the .../lib/itoolkit.js file is where we need to look.
Sure enough, the addParam function exists in itoolkit.js here, though I've also copied it below so we can more easily discuss it.
iPgm.prototype.addParam = function(data, type, options, inDs) {
if(__getClass(type) == "Object") // DS element has no 'type', so if the second param 'type' is an Object, then it is the options.
opt = type;
else
opt = options;
if(!inDs) { // In recursive mode, if it is an element in DS, then no <parm> or </parm> needed.
if(opt && opt.io)
this.xml += i_xml.iXmlNodeParmOpen(opt.io);
else
this.xml += i_xml.iXmlNodeParmOpen();
}
if(__getClass(data) == "Array") { // If it is a struct parameter, recursivly parse its children.
if(opt)
this.xml += i_xml.iXmlNodeDsOpen(opt.dim, opt.dou, opt.len, opt.data);
else
this.xml += i_xml.iXmlNodeDsOpen("", "", "", "");
for(var i = 0; i < data.length; i++) {
this.addParam(data[i][0], data[i][1], data[i][2], true);
}
this.xml += i_xml.iXmlNodeDsClose();
}
else { // A simple parameter
if(opt)
this.xml += i_xml.iXmlNodeDataOpen(type, opt.dim, opt.varying, opt.enddo, opt.setlen, opt.offset, opt.hex, opt.before, opt.after, opt.trim) + data + i_xml.iXmlNodeDataClose();
else
this.xml += i_xml.iXmlNodeDataOpen(type, "", "", "", "", "", "", "", "", "") + data + i_xml.iXmlNodeDataClose();
}
if(!inDs) { // In recursive mode, if it is an element in DS, then no <parm> or </parm> needed.
this.xml += i_xml.iXmlNodeParmClose();
}
}
One of the parameters for addParam is the options variable, and we need to see how that is used in this function to learn whether we can arbitrarily add new options. About five lines in, we see the following line:
opt = options;
So now we're looking for how opt is used. A quick scan has my eyes locking in on this line:
this.xml += i_xml.iXmlNodeDataOpen(type, opt.dim, opt.varying, opt.enddo, opt.setlen, opt.offset, opt.hex, opt.before, opt.after, opt.trim) + data + i_xml.iXmlNodeDataClose();
We learn a couple things by looking at this. We can see that the opt attributes are being broken out into specific parameters, and that means we can't blindly pass additional options to iXmlNodeDataOpen because it isn't expecting them. So an API refactoring is most likely in order. The good thing is we don't need to refactor the addParam parameter list because it accepts the options object with any number of attributes. It is preferred to not change the addParam signature because that's the one many are using in production in businesses at this point.
The iXmlNodeDataOpen API is brought in with a require statement at the top of itoolkit.js, and its full definition can be found here. I've also copied it below for the sake of conversation.
var iXmlNodeDataOpen = function(xtype, xdim, xvarying, xenddo, xsetlen, xoffset, xhex, xbefore, xafter, xtrim) {
return iXmlNodeOpen(I_XML_NODE_DATA_OPEN)
+ iXmlAttrDefault(I_XML_ATTR_KEY_TYPE,xtype,I_XML_ATTR_VALUE_TYPE)
+ iXmlAttrDefault(I_XML_ATTR_KEY_DIM,xdim,I_XML_ATTR_VALUE_OPTIONAL) //I_XML_ATTR_VALUE_DIM? Change to I_XML_ATTR_VALUE_OPTIONAL
+ iXmlAttrDefault(I_XML_ATTR_KEY_VARYING,xvarying,I_XML_ATTR_VALUE_OPTIONAL)
+ iXmlAttrDefault(I_XML_ATTR_KEY_ENDDO,xenddo,I_XML_ATTR_VALUE_OPTIONAL)
+ iXmlAttrDefault(I_XML_ATTR_KEY_SETLEN,xsetlen,I_XML_ATTR_VALUE_OPTIONAL)
+ iXmlAttrDefault(I_XML_ATTR_KEY_OFFSET,xoffset,I_XML_ATTR_VALUE_OPTIONAL)
+ iXmlAttrDefault(I_XML_ATTR_KEY_HEX,xhex,I_XML_ATTR_VALUE_OPTIONAL)
+ iXmlAttrDefault(I_XML_ATTR_KEY_BEFORE,xbefore,I_XML_ATTR_VALUE_OPTIONAL)
+ iXmlAttrDefault(I_XML_ATTR_KEY_AFTER,xafter,I_XML_ATTR_VALUE_OPTIONAL)
+ iXmlAttrDefault(I_XML_ATTR_KEY_TRIM,xtrim,I_XML_ATTR_VALUE_OPTIONAL)
+ I_XML_NODE_CLOSE;
}
The iXmlNodeDataOpen function definition has the parameters we could expect based on how it is being called from itoolkit.js. The body of iXmlNodeDataOpen is fairly straightforward in that it immediately returns an XML string it is composing by calling iXmlAttrDefault a number of times. Remember that XMLSERVICE, today, operates only on XML, not JSON. So that means we need to do conversion to and from XML and JSON to make it easy for Node.js (aka JavaScript) programmers to easily interface with XMLSERVICE.
After pondering it a bit, I determined the best approach would be to simplify the function signature to not have individual options and instead receive in a single options object that could have any number of arbitrary or predefined attributes defined and iterate through those attributes to create the XML tag attributes, as shown below.
var iXmlNodeDataOpen = function(xtype, options) {
var result = iXmlNodeOpen(I_XML_NODE_DATA_OPEN) + iXmlAttrDefault(I_XML_ATTR_KEY_TYPE,xtype,I_XML_ATTR_VALUE_TYPE);
for (var o in options) {
result += iXmlAttrDefault(o, options[o], I_XML_ATTR_VALUE_TYPE);
}
return result += I_XML_NODE_CLOSE;
}
Next, the call from itoolkit.js to ixml.js needs to be addressed. Below, I have a snippet from the itoolkit.js addParam function definition that shows how both calls to iXmlNodeDataOpen have changed to pass a single opt object that contains all the various attributes.
. . .
else { // A simple parameter
if(opt)
this.xml += i_xml.iXmlNodeDataOpen(type, opt) + data + i_xml.iXmlNodeDataClose();
else
this.xml += i_xml.iXmlNodeDataOpen(type, opt) + data + i_xml.iXmlNodeDataClose();
}
. . .
It's possible my above code changes are hard to mentally put into context because you're not the one who made them. That's where Git commit diffs come into play. I made all my changes and committed them back to my fork repo on Bitbucket, which you can see here.
Figure 1 has a screenshot of the aforementioned link. As you can see, it conveys that six (6) files were changed and declares how many additions and removals of source code were done. We obviously haven't talked about all of the changes yet. The second arrow points at an "Oops, how did that change make it into my commit?" In short, the change on this line is the removal of spaces from the end of the line. I shouldn't have included this in the commit but didn't catch it before I did the commit.

Figure 1: Git commit visual
Also in Figure 1, at line 122, we see the additional code I realized was necessary to parse the response XML from XMLSERVICE and dynamically put it into the JSON result. Previously, the resulting JSON was being populated only with the type and value attributes.
Figure 2 shows the changes I made to ixmljs, which is much easier to read than the previous text-only code snippet I used.

Figure 2: Git diff of ixml.js change
At this point, I've refactored the XML composition and parsing. The next step is to make sure I didn't break anything by running the existing unit tests and composing some new ones. Unit tests are stored in the test/ directory, and for the purposes of this change, I modified the test/test.js file. You can see the commit changes online here or look at Figure 3.

Figure 3: Git diff of additional unit test
The important thing to notice is the addition of 'name' : paramValue on line 132. Again, name isn't a documented option in the iToolkit documentation and is instead an arbitrary name-value pair we want to include on the call to XMLSERVICE and have it returned to us on the same parameter. Line 138 and 139 test to see whether the name attribute made the round trip back to our program and whether it contains the value set for paramValue, which is 'errno'.
Now it's time to run the unit tests. The simple way to run the unit tests is to do the following:
$ cd test
$ npm test
The problem with that is it will run all of the tests when I really want to run only one test. You'll eventually want to run all tests, but when you're honing in on a specific change, you'll want to just run that test so it doesn't take so long. Below is a screenshot showing how to use the -g option (grep) to run a specific unit test inside a specific file.
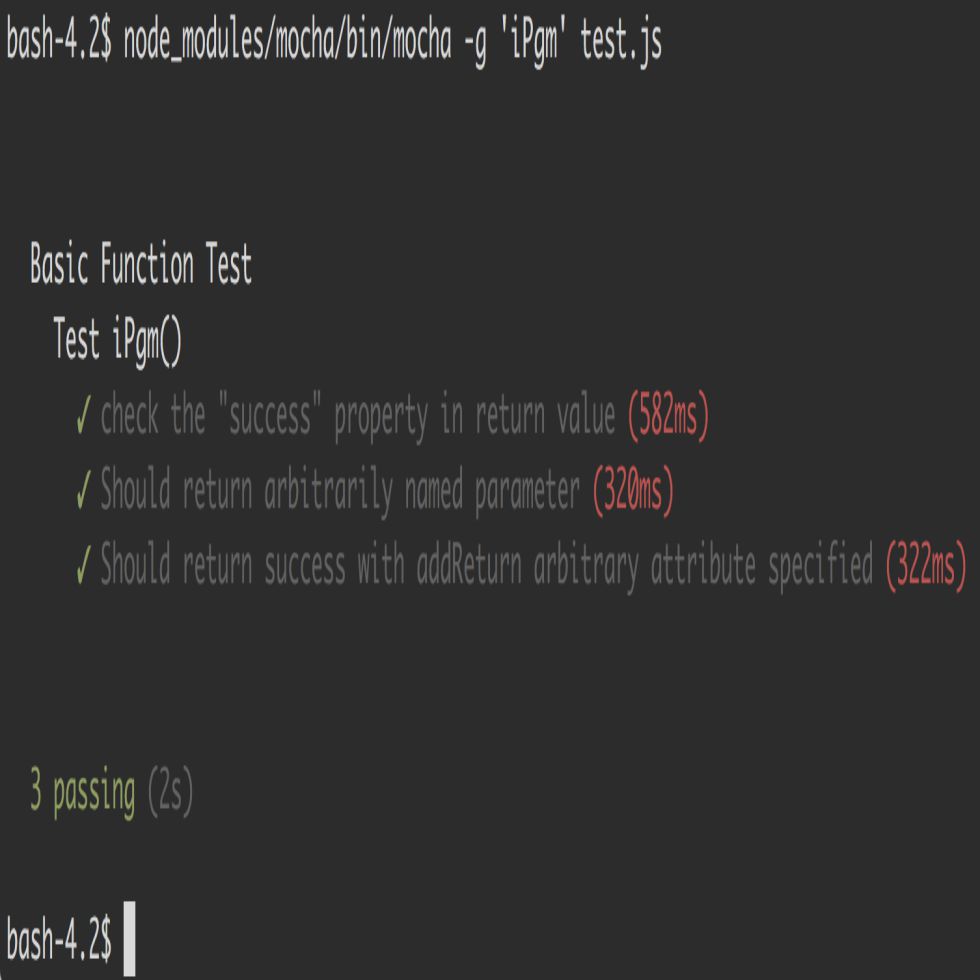
Figure 4: Running the unit tests
As you can see, all of the tests passed. It's worth noting I went through a dozen or more iterations to figure out exactly how the unit test should be composed. To that point, I also discovered my machine didn't have some of the XMLSERVICE test programs installed (e.g., ZZCALL and ZZSRV6). This led me to create the test/rpg directory and copy both of those programs from the XMLSERVICE repo into this repo. I included compile commands at the top of the files so that it was clear this needed to be compiled from the IFS using the STMF option. I could have skipped this step of documenting and including unit test mechanisms, but that would mean the next person would have to create them also.
At this point, it's time for me to issue a pull request from my "aaronbartell/nodejs-itoolkit" repo to the "litmis/nodejs-itoolkit" repo. The changes won't be automatically accepted into the parent repo and instead will allow for the core committers to review beforehand. Figure 5 shows how this is accomplished on Bitbucket.

Figure 5: Create pull request
That's it for this article. I hope you now have more insight as to how community involvement in open source can happen in tangible real-world scenarios. The Node.js iToolkit project still suffers from lack of comprehensive unit tests. It would help a lot if others could donate their time and contribute unit tests. It's a great learning opportunity!
If you have any questions or comments, then please comment below or email me at

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online