















Why is it that once we move into the workforce—and indeed to a great extent even before that—"play" becomes a four-letter word? When we were kids, nobody expected anything permanent to come out of our attempts to build houses with wooden blocks or Lego. Nobody told us to stop wasting time; it was not only accepted but even encouraged as part of the process of growing and learning. Yet in most System i shops, developers who dare to take a few minutes out of the day to "play" with a new technique or tool are likely to find themselves in trouble and be told to "get to work."
This attitude has always puzzled and depressed me. Many of the techniques that I have exploited to good effect as a programmer over the years were the direct result of simply playing with an idea to see what might come out of it. In fact, I became so convinced of the value of this practice that when I became an IT manager, I initiated the practice of "play time" for my programming staff. They were to spend half a day every couple of weeks simply exploring some new tool or technique. Sometimes they spent their time reading a technical journal, sometimes they worked with a program inspired by something they had read, or sometimes they simply worked with a tool we already owned to see if it offered any capabilities that we were not utilizing.
I know what you're thinking—that [insert programmer's name here] might simply take advantage of that to pad his resume. Certainly that could happen, although it has not been my experience. And who is to say that his "padding" today won't be a valuable asset to your company six months from now? Besides, if he really is that ready to goof off at the slightest provocation, what makes you think he's doing useful work right now?
By now, you might be wondering what all of this has to do with today's topic. Good question. The simple answer is that many aspects of the approach I'm about to describe emerged not out of sitting down to engineer a solution to a specific problem, but rather out of curiosity, an "I wonder what else I could do with this" approach if you like. I hope this will be the first in a number of articles that encourage you to explore new ideas and techniques.
Generating XML
Some time ago, when I first became interested in XML, I wrote a number of RPG programs that generated XML documents. RPG IV's string-handling extensions and varying-length field support certainly made this a lot simpler than it could ever have been with RPG/400, but it didn't take long for the "there has to be an easier way to do this" feeling to strike me. This was closely followed by "I guess I could write a set of subprocedures something like CGIDEV2 but for XML." No sooner did that pop into my head than I had the classic Homer Simpson "Doh!" moment. I didn't have to write anything; I could simply use CGIDEV2 for the purpose, but with an XML template rather than an HTML one!
For those of you unfamiliar with CGIDEV, a quick introduction is probably in order here before we go any further. CGIDEV2 was originally developed by IBM Rochester's business partner group to simplify the task of writing Web applications in RPG. Its designer, Mel Rothman, had the aim of making it as easy to write a Web page to a browser as it was to write a screen to a 5250 display. Since RPG programmers were familiar with the notion of using DDS to externally describe their 5250 screens, he designed a similar template-based system to provide a "fill in the blanks" approach to building HTML streams. Admittedly, as you can see in the extract from the sample template below, the result doesn't look like DDS. The principle is the same, however, in that the three basic elements of formats, variables, and literals all have equivalents in CGIDEV2. Of course, because there are no fixed columns, it looks very different, and special characters have to be used to identify the different components.
/$ProductData
. . . . . .
Record format names (in red) are known by CGIDEV2 as section names. By default, they begin with "/$" but this, as with all the delimiters used by CGIDEV2, can be changed if you wish.
Variable Names (in blue) are referred to by CGIDEV2 as substitution variables, and they are identified by the paired "/%" and "%/" marks, which bracket the variable's name. These serve exactly the same purpose as in a display file in that they will be replaced by the contents of the variable when the section in which they are contained is written.
The balance of the template consists of literals. These will simply be output as-is, just as, for example, column headings in a display file would be.
Since the support for CGIDEV2 is not built in to the RPG IV compiler as display and printer files are, we use the CGIDEV2 APIs to perform the various tasks involved, such as writing records, supplying the data for the substitution variables, and writing the resulting XML data to the IFS.
Sample Program MCPRESSXML
The XML document we are producing will itemize all of the categories of goods sold by our company. Each category element will contain details of the products in that category. We will take a brief look at the RPG code used to generate the document in just a moment. Before we do, though, take a quick look at the portion of the finished XML document, which is shown below. You should be able to see the correlation between the template I showed you earlier and the finished document. As you can see, the Category section is repeated, just as a subfile record or printer file detail line might be repeated. Similarly, the Product section is repeated within its category.
. . . . . .
If you prefer to study the full source of the RPG program, you can find it here. I'll just highlight the critical points in the process in this article. If you would like to see the full version of the XML template, it can be found here.
The program begins by loading the XML template into memory from the IFS. Alternatively, we could have stored it in a source physical file, but the IFS is normally preferred since we can use XML tools such as those provided in WDSC to help in its design. As you might expect, since CGIDEV2 was designed for building Web applications, many of the subprocedures have "HTML" incorporated into their names. If this bugs you, you can always create a new version of the relevant routines using "XML" instead of "HTML" in the names. Since the source code is supplied for all of the routines in CGIDEV2, this is not a difficult task. Once the template is loaded, the program writes the FILEHEADER section to the buffer before entering the loop that processes the Product file.
WrtSection('FILEHEADER');
The product file we are processing (PRODUCT2) is a logical view of the product master, which has the category code as its primary key and the product code as the secondary. Since the relevant information must be output at the beginning of each new category, we check for a change in the category code, and if we find one, arrange for the output of a trailer section to close off the previous element. The WrtSection API is used to perform this task. It is the logical equivalent of doing a write to a display or printer file and causes the related XML data to be added to the buffer.
The UpdHTMLVar API causes the data identified by the second parameter to be set up as the value associated with the substitution variable named in the first parameter. The data stored in this way is not actually used until a section containing that variable is written. In this case, the values for CatCode and CatName are used immediately after being set, since they are used in the CategoryHeader section.
If Not firstrecord;
WrtSection('CategoryTrailer'); // Not output first record
Else;
firstRecord = *Off;
EndIf;
lastCategory = CATCOD;
Chain CATCOD CATEGOR1;
UpdHTMLVar('CatCode': CATCOD);
UpdHTMLVar('CatName': CATDES);
WrtSection('CategoryHeader');
The section for the product information is set up and output in a similar fashion. Note that because three of the values involved are numeric, it is necessary to use the %CHAR built-in function (BIF) in order to convert the values to a character string. Unlike display or printer files, XML data streams can only consist of character data; it is up to us to convert it to the desired format before setting it into the substitution variable. If you want more sophisticated editing than that supplied by %CHAR (for example, you need to have leading zeros included in the string), you can use the BIFs %EDITC or %EDITW to provide the necessary formatting.
UpdHTMLVar('Description': PRODDS);
UpdHTMLVar('SellPrice': %Char(SELLPR));
UpdHTMLVar('CostPrice': %Char(LNDCST));
UpdHTMLVar('QtyOnHand': %Char(STOH));
WrtSection('ProductData');
This process continues until the end of the product file is reached, at which time a final CategoryTrailer section is output followed by the FileTrailer section, which wraps up the XML document. At this point, our document is complete and all that remains is to write it out to the IFS. This task is performed by the WrtHTMLToStmf API, as shown below. We simply supply the path name and the code page in which it is to be written. Why specify the code page? Because if we did not do so, the file would be created in the code page of our job, which would mean EBCDIC. There are many code pages in which we might want our XML file, but EBCDIC is not likely to be one of them! Normally, the data would be written in ASCII (which is the case in my example—code page 819 being a commonly used ASCII code) or possibly in UCS-2 (Unicode), which would be represented by a code page of 13488.
rc = WrtHtmlToStmf(XML_Output: 819);
Beyond XML Documents
After I experimented with creating XML documents in the manner I have been describing, it occurred to me that there might be other applications for this technique. It didn't require a degree in rocket science to determine that any character-based "document" could be used as a template, and if substitution variables were imbedded in the text, then a "mail merge" operation could effectively be performed on it.
Some of the things I have played with include MS Word documents, Rich Text Format (RTF) documents, PDF files, and Excel spreadsheets. And of course I have also used the technique for the purpose it was originally intended for—namely, creating static Web pages programmatically. In fact, many of the Web pages for our RPG & DB2 Summit event are built in this way from entries in our session and speaker databases. You can see an example here. I can't claim credit for these pages, though; my colleague Paul Tuohy gets the honors for that.
RTF files work quite well, as the basic format is relatively straightforward, which is more than can be said for MS Word documents and Excel spreadsheets in their native format. It is hard to think of a word to describe how I feel about those (or at least it is hard to think of one that MC Press will publish!). Let's just say that it is a really good thing that MS is switching to XML as the default storage format for Office documents.
And that brings us full circle, since XML was where we started.
Generating Excel Spreadsheets
I have been generating Excel spreadsheets using RPG IV's Java interface capabilities since V5R1 became available, taking advantage of the facilities provided by the Apache POI project. While this provides for great flexibility, it can be a complex and tedious process if significant formatting is required. So, once I could save spreadsheets in XML format, I began to explore using the CGIDEV2 template technique to generate them. The spreadsheet shown in Figure 1 was built in this manner and, although it is very simple, demonstrates what can be done. The major benefit is the ability to incorporate cell formatting—something you just cannot do by using Comma Separated Value (CSV) files. For this example, I created a very simple spreadsheet containing the basic formatting that I needed and then saved it in XML format. I then edited the XML to form a skeleton for CGIDEV2 to use.
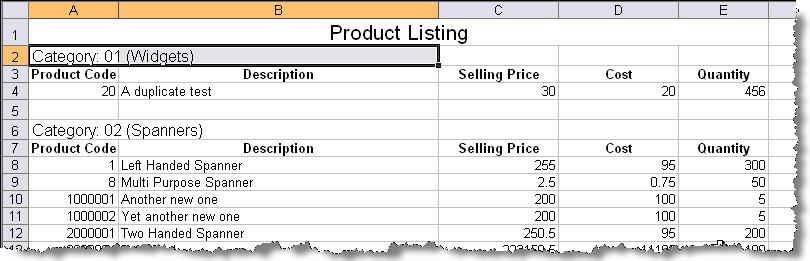
Figure 1: You can use CGIDEV2 to build XML spreadsheets like this one. (Click image to enlarge.)
You might notice that the data incorporated in this spreadsheet is the same as in the XML document we saw earlier. In fact, the only difference between the program that built this spreadsheet and the one that built the XML documents is the template that was used!
One quick word of warning on the XML generated by Excel: It often includes absolute cell references (e.g., ss:Index="5") or row and column counts (e.g., ss:ExpandedRowCount="6"). For our example, I had to remove these entries from the template; otherwise XML errors were flagged when I attempted to load the generated file. Although the dialog that appears when such errors occur informs you that details of the errors have been logged, I have yet to be able to locate the directory in which the file is located. Comments on the Internet lead me to believe that it is a "deeply hidden" directory, but I have not yet bothered to follow up on this and have been able to resolve any problems by experimentation.
An extract from the CGIDEV2 template used is shown below.
<row ss:height="15">
<cell ss:styleid="s27"><data ss:type="string">
Category: /%CatCode%/ (/%Catname%/)
<row >
<cell ss:styleid="s28"><data ss:type="string">
Product Code
<cell ss:styleid="s28"><data ss:type="string">
Description
<cell ss:styleid="s28"><data ss:type="string">
Selling Price
<cell ss:styleid="s28"><data ss:type="string">
Cost
<cell ss:styleid="s28"><data ss:type="string">
Quantity
/$ProductData
This is the format used by Excel 2003, and as you can see, while it is more complex than our original document, is not hard to understand. With the help of a good XML editor, like the one built in to WDSC, it is relatively easy to determine which pieces map to which sections of the spreadsheet. If you need to delve more deeply into the topic, the full XML specifications used by different releases of Excel are documented on Microsoft's Web site. I have found that I can do most of what I need to do simply by studying the XML output from Excel, editing it, and then attempting to reload the document into Excel.
Closing Thoughts
Some of you may be in the process of converting existing applications so that they can be used as Web services as part of your application modernization process. Perhaps you are modifying your RPG programs to take advantage of Web services. If you are, you may be wondering, as I did, if it is possible to simply use CGIDEV2 to generate the XML for the required request and response packets—in particular, to have that data accessible within your program without having to first write it to an IFS file. The answer is "Yes, but...". It is possible, but it requires that you write a couple of additional subprocedures for inclusion in CGIDEV2's XXXWRKHTML module. I am hoping to be able to publish the required procedures shortly, together with instructions on how to rebuild the CGIDEV2 service program. If you are interested in receiving them, please post a comment in the forum and I'll get them to you ASAP—or help you write them for that matter.
So go thou forth and play! You have nothing to lose but your upper management's conviction that RPG and the System i are "old fashioned and can't do that kind of thing."
Editor's Update: Please find the code for this article here and here.




 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online