








A recent article, "Legacy Maintenance: Evaluating and Documenting Business Rules in Legacy Code," addressed the idea of documenting business rules. It gave a specific example of documenting business rules for a free-form RPG program. While that was a helpful exercise, it was for a single platform, which is fairly easy to manage. In this article, I want to show why documentation is even more important in architectures spanning multiple platforms.
This article will cover data definitions in particular, because I'm a little bit old-fashioned and I believe that the data defines the system. Everything in an application flows from and is influenced by not only how the data is stored in the database, but also how data is communicated between components of the application.
But before I delve into that documentation, I want to review a little bit about what documentation is used for in a traditional development shop. In these days of "code first and document later" programming, documentation—and particularly application design documentation—is afforded less significance than in times past, if indeed it's considered at all.
Which Came First, the Design or the Documentation?
I must stress that I am a firm believer in designing before programming. The whole idea of programming by refactoring just doesn't make a lot of sense to me. I lean more toward the Big Upfront Design (BUD) school of programming, where the majority of your design is done before you actually write any code. I'm not immune to the allure of some of the "agile" programming strategies that allow you to sit down and code immediately, but I still have a lot of old-school in me, so I tend toward the classic development strategies. I'm not a complete Luddite; as the new RPG Developer publication evolves, I will be looking for some of the next-generation programmers to explain how and when the newer, extreme techniques can be applied to RPG development.
But for this article, I will examine the product development life cycle techniques that were prevalent during my formative years (and are still in use today). A quick bit of history (as if you didn't see that coming): Before the advent of agile programming, we used software development techniques with a number of names, including one called the waterfall method. In the waterfall method, there were various phases of the development process, each of which led to the next phase. A typical project plan looked like this at the highest level:

Figure 1: The standard waterfall development cycle is made up of discrete steps. (Click images to enlarge.)
Each step (or "phase") had its own pieces. The requirements phase involved talking to users and identifying the new features or modifications needed to make them more productive. Functional design was typically done by business analysts who sort of bridged the gap between users and coders; they understood much of the technical nature of the system but usually came from a business background. They identified the programs and files that needed modification and the business rules that needed to be implemented. A programmer then created the technical design, including the specific fields to be added or the modifications that would be made to a program. In a large shop, these designs were detailed enough that they could be written by a senior programmer and then handed off to a junior programmer. The coding phase was just that: Write the code and debug it. Usually this involved a unit test plan. The integration phase then made sure that the new code interacted properly with the other parts of the system.
The idealized waterfall model had specific, discrete steps, each of which began just as its predecessor ended. This is one of the criticisms of the method, because in a system of anything more than trivial complexity, you are almost guaranteed to have design changes, due to either unforeseen issues or changing business requirements. Such is the nature of business programming; it is not static. And so the real project plan for most projects looked more like this:

Figure 2: The "waterfall with feedback" model included overlapping phases.
Figure 2 shows an adaptation of the waterfall method with overlapping phases. Each phase then provides feedback to previous phases. The amount of overlap is not accidental, either: In the best design, feedback should go back one phase. For example, it's actually quite likely that the functional design phase will uncover issues that need to be taken back to the users, which will in turn affect the requirements phase. However, it should be rare that technical design issues should do so and pretty much impossible for coding issues to do so. That's because each phase acts as a buffer between the phases before and after it.
And that is where documentation comes in.
Documentation: The Glue Between the Phases
Let me talk now about some specifics. I'm going to go into the way-back machine and use my experiences at a rather large software vendor that shall remain nameless. We didn't actually call the documents that moved between phases "documents." This wasn't just obfuscation; we had a better name: deliverables. Deliverables were the components that were "delivered" from one phase to another. They clearly highlighted the delineation between phases. And while different shops had different names for both the phases and the deliverables, they usually did pretty much the same thing. Here is an example list.
| Phases and Associated Deliverables | ||
| From Phase | To Phase | Deliverable |
| Requirements | Functional Design | Specifications. These documents identified at the highest level the features and functions that the proposed programming task would accomplish. These were typically couched in the most business-oriented terms, such as "provide lot-level tracking for inventory." It would identify business issues such as FIFO allocations, as well as areas that weren't affected (for example, costs might not be tracked by lot). |
| Functional Design | Technical Design | Application Design. This was the bridge from user to computer requirements. A given task often affected many objects. Something like the lot-level tracking would affect everything from maintenance programs to allocations to order entry. It was the job of the business analyst to identify all those areas and explain how each program was affected by the requirement. |
| Technical Design | Coding | Detailed Design. This outlined the exact files and fields to be updated, as well as the routines within the affected program and the logic that was to be added. Calculations and results would be described here, although the final code was left to the discretion of the programmer. One of the primary components of the detailed design deliverable was the unit test plan, which the programmers used to determine the accuracy of their coding. |
| Coding | Integration | Object List. This was the list of affected objects. Once all tasks for a given part of the system were completed, integration and system testing could begin. This was often the tricky part; coordinating all the changes for order entry was always an interesting task. |
So the specifications were the definition of the enhancement in business terms. The enhancement then filtered down through the phases, with each deliverable moving closer to the actual code required. The application design identified at a high level the objects that needed to be updated and the modifications required, while the detailed design mapped out the individual changes to the affected objects—for example, database files, report layouts, or programs.
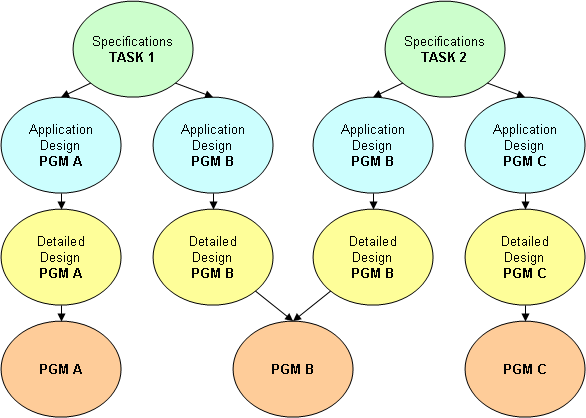
Figure 3: The business requirement is refined via each phase of the development cycle.
Figure 3 shows the process in some detail and brings up one of the crucial points. Note that PGM B in the diagram actually has two detailed design documents, one from TASK 1 and one from TASK 2. One of the most difficult tasks in a large development project is managing multiple changes to a single object. Consistent documentation is crucial.
Consistency Is the Hallmark of Good Design
Although Emerson remarked that a foolish consistency is the hobgoblin of little minds, he never really defined the difference between foolish and intelligent consistency. And no matter what the poet meant, I can assure you that consistency is an absolute requirement in system design.
Picture this: During the design of the lot tracking enhancement, somebody creates a field called EXPIRES to capture the expiration date for the lot. However, names can often be misleading in the design process. One analyst might see the expiration date as the last date that the lot is good, while another designer might see it as the first day the lot is expired. Obviously, these are very different meanings, and a mistake could have disastrous effects.
The best way to avoid this is to establish a dictionary of common terms and to be sure that your field naming conventions follow that dictionary. This is one of the few places where DDS file definition actually has an advantage over DDL (the SQL data definition language). DDS fully supports the concept of a reference file, and that can help when defining fields. You can, for example, come up with a standard field name for a concept like expiration date and then define that concept in your field reference file. Any fields in your database that are meant to be expiration dates can then be based on that field. Standard i5/OS tools will then show you the referenced field.
You can still do something along those lines with DDL, although it's not quite as smooth. At the very least, I suggest using a naming convention that includes the reference field name as part of the actual column name in the table. But that technique goes for DDS as well: Your actual physical file field names should include the reference field name. I'll leave for another day the debate as to whether fields in two files should have the same name or should have a prefix identifying the table.
And Now We Return to Our Regularly Scheduled Article
This brings us back to the issue of documentation. Even if you do have consistent naming for each of your fields, those definitions should be further codified in a binder that identifies these field names and their functions. Let's take a look at a field definition:
| Field Name | EXPIRES |
| Field Type | DATE (platform-specific) |
| Definition | This lot expiration date identifies the last date that a lot is available. After this date, the lot is considered "expired" and can no longer be allocated. |
Again, the name is probably less important than the fact that you have a name and use it consistently. If you stick with DDS naming, you're limited to a total of 10 characters; if you use a two-character prefix, that leaves you only eight, so your naming will need to be a little bit creative (I know that those of you who remember six-character field name limitations are chuckling to yourselves; consider yourself lucky these days).
You might notice that in field type, I have "DATE (platform-specific)." Ah, finally we talk about platforms! And indeed, the ability to properly manage multi-platform design hinges on consistent documentation of data elements. If two parts of your system treat the same element differently, you will introduce the most difficult bugs of all: ones that are identifiable only through the analysis of inter-platform transactions. Ugh. It's hard enough to set up a test environment on one machine; imagine trying to set one up when it involves two (or more!) different platforms. Not only do you have to set up the test environments on each platform, but you have to have a way to configure your inter-platform communications easily and in a foolproof manner, because changes in those communications parameters could themselves introduce bugs! And yes, you can assume that I speak from painful experience on these matters.
I just got done helping a client replace a SQL Server application communicating via XML over HTTP with a servlet running on the System i. The only test bed we had was the existing SQL Server machine, and the test tools on that box were limited at best. Because there was no formal documentation of the system, we had to do a lot of the testing by trial and error, and believe me, I'd rather have been...well, just about anywhere.
So How Does Documentation Help Multi-Platform Programming?
Most importantly, documentation helps because it makes sure that the data elements throughout the application remain the same. For example, a thick client can interface with a host application in two ways: It can store data locally, or it can get data from the host. Both designs have their benefits and drawbacks, but each can benefit from careful documentation.
Let's look at an example. Suppose that your application has a unit price field that currently stores two decimal places and that, due to business requirements, you now have to add a third decimal place. You might go through all of your System i applications and update everything, including master files, maintenance programs, processing programs, you name it. In fact, except for trying to find room on some green-screen displays, if you have a good reference file, this might not even be a difficult change.
But let's then say you have an offline order entry program. This is a thick client that runs on the laptops of the salespeople. It allows them to download current prices when they have an Internet connection and then go to clients and actually quote and take orders. Later, they upload the orders to the system to be processed.
Well, if you forget about that program in your analysis, you don't put in the extra decimal position. And while that may not mean much, on orders with quantities in the thousands or millions, those tenths of a penny add up pretty quickly. Suddenly your host system is printing invoices that don't match the quoted orders. Luckily, the number is too high, because then someone complains. If the number were too low, your customers would probably just keep the discrepancy to themselves, and you'd only find out way down the road when you analyze your books.
So why would documentation help? Well, because if you had a master document that identified the database on both the host and the laptop, and that document properly identified the price field on the laptop as being dependent upon the system-wide price field, then your initial analysis of the requirements would identify that file (and the programs that use it) as requiring modification. You may rely on a tool that provides all sorts of cross-reference capabilities, but I have yet to find one that can recognize that a field from a database is passed as a field in an XML file to a bit of AJAX running in a browser and then tell you to update the JavaScript when you change the field attributes. However, a solid system design document should tell you just that sort of information.
But it only matters if the documentation is consistent and complete across all of your systems. I've introduced the topic here and explained why it's important, but I've only touched on the database aspect. As you might guess, the issue extends to business rules as well. If there's interest, I'd like to write another article identifying some possibilities for documenting both data elements and business rules across multiple platforms, maybe even offering some specific examples of how to document different languages in a manner that allows consistent cross-referencing. Let me know if this is an area that needs further exploration.
Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. and has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at

Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including Developing Web 2.0 Applications with EGL for IBM i, E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at
MC Press books written by Joe Pluta available now on the MC Press Bookstore.
 |
Developing Web 2.0 Applications with EGL for IBM i Joe Pluta introduces you to EGL Rich UI and IBM’s Rational Developer for the IBM i platform. List Price $39.95 Now On Sale
|
|
 |
WDSC: Step by Step Discover incredibly powerful WDSC with this easy-to-understand yet thorough introduction. Now On Sale
|
|
 |
Eclipse: Step by Step Quickly get up to speed and productivity using Eclipse. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online