









Next in our series on Artificial Intelligence fundamentals, we examine the workhorse of deep learning – Neural networks.
If you missed them, Read Part 1, Understanding Data, Part 2: Artificial Intelligence, Machine Learning, and Deep Learning, Part 3: Data Preparation and Model Tuning and Part 4: Machine Learning Methods here.
Neural networks are the workhorses of deep learning (DL). Modeled loosely after the neuronal structure of the cerebral cortex in the human brain, neural networks are computing systems that learn to perform tasks by analyzing examples. For example, in image recognition, a neural network can learn to identify images that contain cats by analyzing images that have been manually labeled as "cat" or "not cat" and automatically generating identifying characteristics such as fur, tails, whiskers, and pointed ears that can then be used to identify cats in other images. The concept of neural networks was inspired by the way neurons in the human brain function together to understand inputs from the five senses (touch, sight, hearing, smell, and taste). And, while neural networks may seem like “black boxes” to many, deep down they are trying to accomplish the same thing that any other machine learning (ML) model is trying to do – make accurate predictions.

Figure 1: A neural network
Essentially, a neural network is a collection of interconnected “feed-forward” nodes (meaning that data moves through them in only one direction) that loosely model the neurons in the brain. The nodes are organized into layers and an individual node may be connected to several nodes in the layer beneath it, (from which it receives data), as well as to multiple nodes in the layer above it (to which it sends data). Like the synapses in a biological brain, each connection can transmit a signal to other nodes.
A node will assign a number known as a “weight” to each of its incoming connections and when it receives a different data item over its connections, it will multiply the item by the associated weight. It then adds the resulting products together, yielding a single result and if that result exceeds a threshold value, the node will “fire,” which means it will send the sum of the weighted inputs (in the form of a number) along all its outgoing connections. (If the result is below the threshold, the node doesn’t fire.)
Patterns are presented to the network via an “input layer” (which serves as the bottom layer), and from there, data items are passed to one or more “hidden layers,” which is where the bulk of the nodes reside and where the actual processing is done. The top-most hidden layer links to an “output layer,” and this is where the answer that gets generated is provided. The illustration shown in Figure 1 depicts, at a high level, what a simple neural network looks like.
Most neural networks contain some type of “learning rule” that modifies the weights of the connections according to the input patterns they are presented with. In a sense, neural networks learn by example, much like a child learns to recognize dogs from their interactions with different examples of dogs. The most common rule used is the delta rule, which uses the difference between target output values and obtained values to drive learning. So, in essence, when a neural network is initially presented with a new pattern, it makes a random guess as to what the pattern might be. Then, it sees how far this guess was from what it should have been and makes an appropriate adjustment to its connection weights through backpropagation (an abbreviation for the backwards propagation of error). Initially, all node weights and thresholds are set to random values. However, as training takes place, data is fed to the input layer and passes through the succeeding hidden layers, getting multiplied and added together in complex ways, until it finally arrives, radically transformed, at the output layer. During the training process, the weights and thresholds are continually adjusted until training data with the same labels consistently yield the expected results.
For example, if a neural network was designed to identify images that contain cats, the first hidden layer might detect lines, arcs, circles, etc., which then get passed on to the next hidden layer, which might use these shapes to identify features like nose, tail, whiskers, and so forth. This information then gets passed on to the next layer, and this type of processing continues until the output layer is reached. If during training, the neural network did not correctly identify an image of a cat, those branches within the network that favored the output of “not cat” would be weakened (thus, the weights of those connections would be reduced) and the connections and nodes that favored the image as being “cat” would be strengthened (in other words, the weights of those connections would be increased).
Because neural networks are universal approximators, they work best if they are used to model systems that have a high tolerance to error. Consequently, they work very well for capturing associations or discovering regularities within a set of patterns where the volume, number of variables, or diversity of the data is very great; the relationships between variables is vaguely understood; or the relationships are difficult to describe adequately with conventional approaches. That said, there are some specific issues potential users of neural networks should be aware of:
- Apart from defining the general architecture of a neural network and perhaps initially seeding it with a random number, the user has no other role than to feed it input and await the output. In fact, it has been said that because of backpropagation, "you almost don't know what you're doing." Some freely available software packages allow a user to sample a neural network’s training “progress” at regular intervals, but the actual learning progresses on its own. The final product is a trained neural network that provides no equations or coefficients that can be used to define a relationship beyond its own internal mathematics. The network itself is the final equation of the relationship, making it, in a sense the ultimate "black box. "
- Backpropagational neural networks tend to be slower to train than other types of neural networks and sometimes require thousands of training cycles with new input patterns. If run on a truly parallel computer system this is not really a problem, but if the neural network is being simulated on a standard serial machine (such as a Mac or PC), training can take a significant amount of time. That’s because the machine’s CPU must compute the function of each node and connection separately, which can be problematic with very large neural networks that process large amounts of data.
There are a number of different types of neural networks available. However, two types that tend to be used the most are convolutional neural networks (CNNs), which are frequently used in image processing and recurrent neural networks (RNNs), which are often used for text and speech recognition. If you want to learn more, you will find a list of most of the different types of neural network available and what they are used for here:
The mostly complete chart of Neural Networks, explained
https://towardsdatascience.com/the-mostly-complete-chart-of-neural-networks-explained-3fb6f2367464
6 Types of Neural Networks Every Data Scientist Must Know: The most common types of Neural Networks and their applications
https://towardsdatascience.com/6-types-of-neural-networks-every-data-scientist-must-know-9c0d920e7fce
Image recognition – Convolutional Neural Networks (CNNs)

Figure 2: Image recognition with Convolutional Neural Networks (CNNs)
Sight and vision are important because they allow us to connect with our surroundings, stay safe, and keep our minds sharp. And, while sight and vision are often used interchangeably, they are completely different entities – sight is a sensory experience in which the eyes focus the light that is reflected off shapes and objects to create signals that are sent to the brain. Vision, on the other hand, is how the brain interprets these signals. Sight may allow a person to witness an event, but vision helps the person understand the significance of the event and draw interpretations from it.
Unlike humans, computers “see” images in still photographs, videos, graphic drawings, or live stream video feeds as an array of numerical values. Consequently, image recognition is a term that is often used to describe computer technologies that look for numerical patterns in a digital image to identify key features. The term itself (image recognition) is connected to “computer vision,” which is an overarching label for the process of training computers to “see” like humans, and “image processing,” which is a catch-all term for computers doing intensive work on image data.
Image recognition is done in a variety of ways, but the most popular technique used relies on a convolutional neural network (ConvNet/CNN) to filter images through a series of artificial neuron layers. A CNN is a DL algorithm that can take in an image, assign importance (in the form of learnable weights and biases) to various aspects of the image, and then differentiate one aspect from another. The architecture of a CNN is analogous to that of the connectivity pattern of neurons in the brain and was inspired by the organization of the visual cortex (which is the part of the brain that processes visual information).
Suppose you are shown a photograph of a car that you’ve never seen before. Chances are, you’ll know the item in the picture is a car by observing that it contains some combination of the parts that typically make up a car – for example, a windshield, doors, headlights, taillights, and wheels. By recognizing each of the smaller parts and adding them together, you know this is a picture of a car, despite having never encountered this precise combination of “car” parts before.
A CNN tries to do something similar. That is, learn the individual parts of objects and store them in individual neurons, then add them up to identify the larger object seen. This approach is advantageous because a greater variety of a particular object can be captured within a smaller number of neurons. For example, if we memorize templates for 10 different types of wheels, 10 different types of doors, and 10 different types of windshields, we can capture 10 ∗ 10 ∗ 10 = 1000 different cars for the price of only 30 templates. This is much more efficient than keeping separate templates around for 1000 cars (which, by the way, will contain a lot of redundancy). But even better, we can reuse the smaller templates for different object classes. Bicycles also have wheels. Houses also have doors. And airplanes have both wheels and doors, as well as windshields. Thus, it’s possible to construct a set of many more object classes by using various combinations of smaller parts. And this can be done very efficiently.
Despite having their own proper name, CNNs are not categorically different from other neural networks. In fact, they inherit all the functionality of neural networks, and improve them by introducing a new type of layer called a convolutional layer, along with other innovations such as a pooling layer, stride (which controls how the filter convolves around the input volume), and padding (which is an additional layer that can be added to the border of an image). As with other neural networks, CNNs are made up of neurons with learnable weights and biases. Each neuron receives several inputs, takes a weighted sum over them, passes the sum through an activation function, before responding with an output. The whole network has a loss function and suggestions that are applicable for neural networks still apply.
Image recognition isn’t just limited to scanning large volumes of photos in search of specific objects. It’s also the underlying technology behind a lot of different applications. For instance, it’s what enables cameras in cell phones to detect faces. Or, what makes it easy for Facebook to auto-detect family and friends. Cars with “self-driving” modes like those from Tesla are equipped with cameras that analyze their surroundings and make sure they don’t run into other cars, people, or anything else a car might hit unintentionally. Consumer-level drones now have cameras that not only keep them from crashing into building and trees, but also from getting lost when a Global Positioning System (GPS) signal is weak. And the medical industry uses image recognition technology for a host of applications, including analyzing X-Ray images, UV images, CT scans, and so forth to diagnose patients more accurately. Image recognition is also used in manufacturing to inspect production lines, monitor the quality of products, and assess the condition of workers. And it is used in businesses for everything from generating dynamically customized ads to analyzing social media shares and calculating the true value of sports sponsorships.
Natural language processing (NLP) – Recurrent Neural Networks (RNNs)
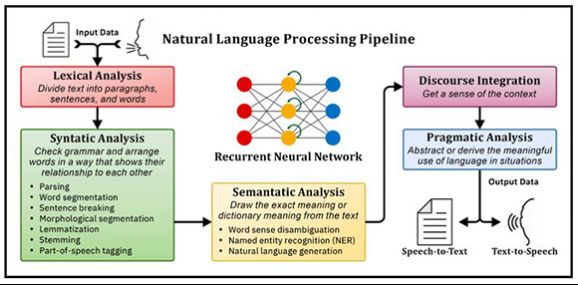
Figure 3: Natural language processing (NLP) with Recurrent Neural Networks (RNNs)
Natural Language Processing (NLP) is a branch of artificial intelligence (AI) that deals with the interaction between computers and humans, using human language. The ultimate objective of NLP is to read, decipher, understand, and make sense of the human language in a manner that is valuable. However, the development of NLP applications is challenging because computers traditionally require humans to "speak" to them in a programming language that is precise, unambiguous, and highly structured. Or more recently, through a limited number of clearly enunciated voice commands. Human speech, however, is not always precise – it’s often ambiguous and its linguistic structure can depend on many complex variables, including slang, regional dialects, and social context.
NLP is not an ML method per se, but rather a widely used technique to prepare text for ML. That said, NLP is typically performed using what is known as a Recurrent Neural Network (RNN), which takes the output of some layers and uses them as input for the same layer. RNNs are often used for text recognition because they learn from what they have found in the past. For example, an RNN is capable of learning that the word “dog” is different when the word “hot” is used in front of it. RNNs are also frequently used for speech recognition as this technology can understand the context of a sentence. (Looking at an entire sentence and not just each individual word in it is important in understanding the sentence’s context). A simple RNN is depicted in the center of the illustration shown in Figure 2.
The primary techniques that are used to perform NLP tasks are syntactic and semantic analysis. Syntax refers to how words are arranged in a sentence to make grammatical sense. Thus, syntactic analysis evaluates how natural language aligns with grammatical rules. Syntactic analysis techniques that are typically used for NLP include:
- Parsing: Involves performing grammatical analysis of a sentence
- Word segmentation: Involves dividing a large piece of continuous text into distinct units
- Sentence breaking: Involves placing sentence boundaries in a large piece of text
- Morphological segmentation: Involves dividing words into individual units called morphemes, which is the smallest meaningful language that cannot be further divided (for example, “in”, “come”, and “-ing”, forming incoming)
- Lemmatization: Involves reducing the various inflected forms of a word into a single form for easy analysis
- Stemming: Involves dividing words with inflection in them to their root form
- Part-of-speech tagging: Involves identifying the part of speech for every word
Semantics refers to the meaning that is conveyed by text. Semantic analysis is more difficult than syntactic analysis because it involves applying computer algorithms to understand the meaning and interpretation of words and how sentences are structured. Semantic analysis techniques used for NLP include:
- Word sense disambiguation: Involves giving meaning to a word based on the context in which it is used
- Named entity recognition (NER): Involves determining the parts of text that can be categorized into preset groups like “names of people” and “names of places”
- Natural language generation: Involves using databases to derive semantic intentions and convert them into human language
In addition to the work that is continuing to be done in research and academia, NLP is being used to solve a variety of problems today. Some of the more common uses of NLP include:
- Text classification: The goal of text categorization is to classify the topic or theme of a document. A popular classification use case is sentiment analysis where class labels represent the emotional tone of the source text – in other words, is the feeling “positive” or “negative“.
- Language modeling: Language modeling is really a subtask of some of the more interesting natural language problems. For example, language models can be used to generate text or speech for new article headlines. Or, to generate new sentences, paragraphs, or documents. Language modeling can also be used to suggest the continuation of an existing sentence.
- Speech recognition: The goal of speech recognition is to map an acoustic signal containing words spoken in a natural language into the text that was intended by the speaker. This might be done to transcribe a speech or recording; generate closed-captioning text for a movie or TV show; or understand commands given to the radio while driving.
- Language translation: Language translation involves converting a source text spoken in one language to another language.
- Document summarization: Document summarization is the task of producing a short description of a text document and can involve creating a heading for a document or creating an abstract of a document.
- Question answering: Question answering systems try to answer a user query that has been formulated in the form of a question by returning the appropriate natural language engineering (NLE) phrase – for example, a specific location, the name of an individual, or a specific date.
Generative adversarial networks (GANs)

Figure 4: Generative adversarial networks (GANs)
Generative adversarial networks (GANs) are DL architectures that consist of two neural networks that are pitted against each other (hence the word “adversarial”), to better analyze, capture, and copy the variations within a data set. Introduced by Ian Goodfellow and other researchers at the University of Montreal in 2014, GANs provide a clever, and better way of training a generative model. (A generative model describes how a data set is generated, in terms of statistics and probability.)
Generative modeling is a form of unsupervised learning that involves automatically discovering and learning patterns in input data, in such a way that the trained model can be used to generate new examples that plausibly could have been drawn from the original data set. For example, if a data set containing images of horses is used to train a generative model, the model should be able to generate an image of a horse that has never existed, but looks real, because the model has learned the general rules that govern the appearance of a horse.
It has been noticed that neural networks can be easily fooled into misclassifying things by adding just a small amount of noise to the original training data. And surprisingly, after adding noise, a model has a higher confidence in a wrong prediction than when its predictions are more accurate. One reason why is because most ML models learn from a limited amount of data (which, as we saw earlier, can result in overfitting). GANs train generative models by framing the task as a supervised learning problem and using two sub-models: a generator model, which is used to generate new plausible examples from the problem domain, and a discriminator model, which is used to classify examples as being either real (from the domain) or fake (produced by the generator model). In other words, the generator tries to fool the discriminator, and the discriminator tries to keep from being fooled. The two models are trained together in a zero-sum game, until the discriminator model is fooled about 50% of the time (which means the generator model is producing a significant number of plausible examples).
One of the biggest challenges of training a GAN is maintaining stability. Both the generator and the discriminator are constantly working against each other to stay one step ahead of the other. Yet, they also depend on each other for efficient training. If the discriminator is too powerful, the generator will fail to train effectively – if the discriminator is too lenient, the GAN will be useless.
Other problems encountered when GANs are used with images include:
- Problems with Counting: GANs fail to differentiate how many of a certain object should occur at a particular location. As a result, a GAN generator can generate more eyes in a human head than are naturally present.
- Problems with Perspective: GANs fail to adapt to three-dimensional (3D) objects because they don’t understand perspective. Consequently, a GAN generator will produce flat (2D) representations of 3D objects.
- Problems with Global Structures: GANs don’t understand a holistic structure. Therefore, a GAN generator can produce an image of a bear standing on its hind legs, while simultaneously standing on all four legs.
Though originally proposed as a form of a generative model for unsupervised learning, GANs have also proven useful for semi-supervised learning, fully supervised learning, and reinforcement learning.
Transfer learning

Figure 5: Transfer learning
Imagine that every time someone entered a new environment, they had to learn how to behave without the guidance of past experiences. Slightly novel tasks such as buying vegetables at a local farmer’s market would be confusing and dependent upon a trial-and-error approach. Fortunately, people use aspects of their prior experiences, (for example, the selection and purchase of items at a neighborhood grocery store), to guide their behavior in new settings. The ability to use learning gained in one situation to help with another is called transfer. And, whether you’re a student trying to earn a degree or a working professional looking to keep your skills current, the importance of being able to transfer what you have learned in one context to something new cannot be overstated.
In ML and DL in particular, transfer learning is based on this concept. The general idea is to use a model that has already been trained for one task to solve a different, but somewhat related problem. For example, if you trained a simple classifier to predict whether an image contains a flower, you should be able to use the knowledge the model learned during its training to recognize other objects, such as insects or birds. Basically, transfer learning tries to exploit what has been learned in one task to improve generalization in another. And, while it’s really more of a design methodology than an ML or DL technique, it has become quite popular because it enables deep neural networks to be trained with comparatively little data. This is important because most real-world problems typically do not have millions of labeled data points available that can be used to train complex neural networks. Other benefits of transfer learning include saving time, money, and the computational resources needed for training models or improving model performance.
As is often the case in data science, it’s hard to form rules that are always applicable. But there are some basic guidelines that can be used to determine when transfer learning might be beneficial:
- When there isn't enough labeled training data available to train a neural network from scratch
- When a neural network already exists that has been trained on massive amounts of data to perform a similar task
- When a new neural network is needed and an existing, pre-trained neural network that has the same input is available
Keep in mind that transfer learning only works if the features learned from the first task are general, meaning they can be used for other related tasks as well. Also, the input data for the new model must have the same number of features that were used to train the original model. If that’s not the case, it may be possible to use dimensionality reduction to resize the input for the new model needed.
There are several pre-trained models available for common DL tasks (such as image classification) that data scientists can use as the foundation for transfer learning. One of the most popular is Inception-v3, which is a convolutional neural network that has been trained on more than a million images from the ImageNet database. (The network is 48 layers deep and can classify images into 1,000 object categories.) Others include ResNet and AlexNet, as well as microsoftml (a Python package from Microsoft that provides high-performance machine learning algorithms for SQL Server Machine Learning Services) and MicrosoftML (an R package from Microsoft that is similar to microsoftml).
Deep learning frameworks

Figure 6: Some of the more popular deep learning frameworks
A deep learning (DL) framework is an interface, library, or tool that enables developers, researchers, and data scientists to build DL models efficiently, without having to spend time creating the code needed for the underlying algorithms. They offer building blocks – typically, in the form of a collection of pre-built, optimized components – for designing, training, and validating deep neural networks.
A variety of DL frameworks are available today and each is built in a different manner, and for different purposes. Most are open source and are available to anyone who wants to use them. And they are often used with a high-level programming language such as Python and R. Some of the more popular DL frameworks include:
- TensorFlow: Arguably one of the best DL frameworks that has been adopted by several well-known companies such as IBM, Airbus, Twitter, Uber, Airbnb, Nvidia, and others, mainly due to its highly flexible system architecture. TensorFlow is available on both desktops and mobile devices, and it can be used with programming languages like Python, C++, R, Java, and Go to create DL models, as well as wrapper libraries. TensorFlow comes with 2 tools which are widely used: TensorBoard, which is used for effective data visualization of network modeling and performance, and TensorFlow Serving, which is used for rapid deployment of new algorithms while retaining existing server architectures and APIs, as well as providing integration with other TensorFlow models. TensorFlow is handy for creating and experimenting with DL architectures, and its formulation is convenient for data integration (for example, in putting graphs, SQL tables, and images together).
- PyTorch: PyTorch (pronounced “pie torch”) is an open-source machine learning library that is based on the Torch library, which is a scientific computing framework with wide support for ML algorithms that put graphics processing units (GPUs) first. It is used widely amongst industry giants such as Facebook, Twitter, and Salesforce and is considered a strong competitor to TensorFlow. The Torch library is easy to use and efficient, thanks to a fast-scripting language called LuaJIT, and an underlying C/CUDA implementation. Unlike Torch, PyTorch runs on Python which means that anyone with a basic understanding of Python can get started building their own DL models. PyTorch is well suited for small projects and prototyping; the process of training a PyTorch-built neural network is simple and clear.
- Keras: An open-source neural network library written in Python that is capable of running on top of TensorFlow, Microsoft Cognitive Toolkit, Theano, PlaidML, or Microsoft Cognitive Toolkit (CNTK). (Keras is a part of TensorFlow’s core API.) Designed to enable fast experimentation with deep neural networks, Keras focuses on being user-friendly, modular, and extensible. It is probably the best DL framework for those just starting out and is ideal for learning and prototyping simple concepts. Keras is used primarily for classification, text generation and summarization, tagging, translation, and speech recognition model development.
- Scikit-learn: Scikit-learn is a free software ML library for the Python programming language. It features various classification, regression, and clustering algorithms including support vector machines, random forests, gradient boosting, k-means, and DBSCAN. It is designed primarily to interoperate with the Python numerical and scientific libraries NumPy and SciPy, however, it integrates well with many other Python libraries, such as Matplotlib and plotly for plotting, Pandas dataframes, and many more.
- MXNet: Designed specifically for high efficiency, productivity, and flexibility, MXNet (pronounced as mix-net) is a DL framework that is supported by Python, R, C++, Julia, and Scala. MXNet gives the user the ability to train DL models with their programming language of choice, and is known for its capabilities in imaging, handwriting/speech recognition, forecasting, and natural language processing (NLP). Because the backend is written in C++ and CUDA, MXNet can scale and work with a myriad of GPUs, which makes it indispensable to enterprises. MXNet supports Long Short-Term Memory (LTSM) networks along with recurrent neural networks (RNN), which are used in problems that can be framed as “what will happen next given…” and convolutional neural networks (CNN) which are good at solving problems like image classification.
- MATLAB: With tools and functions for managing and labeling large data sets, MATLAB also offers specialized toolboxes for working with ML, neural networks, computer vision, and automated driving. MATLAB is designed to make DL easy for engineers, scientists, and domain experts – with just a few lines of code, users can quickly create and visualize models, as well as deploy those models to servers and embedded devices. (MathWorks is a privately held corporation that specializes in mathematical computing software. Its major products include MATLAB and Simulink, which support data analysis and simulation.)
- Caffe: Caffe is a DL framework that is supported with interfaces like C, C++, Python, MATLAB, and a Command Line Interface. It is well known for its speed and transposability, along with its applicability in modelling CNNs. The biggest benefit of using Caffe’s C++ library (which comes with a Python interface) is access to the deep net repository Caffe Model Zoo which offers pre-trained neural networks that can be used immediately. Another benefit Caffe offers is speed – it can process over sixty million images a day with a single Nvidia K40 GPU. Caffe is a popular DL framework for vision recognition. However, it does not support fine granularity network layers like those found in TensorFlow or the Microsoft Cognitive Toolkit (CNTK).
Other DL frameworks available include Gluon, Swift, Chainer, DL4J (short for Deep Learning for Java), and Open Neural Network Exchange (ONNX).
Stay Tuned
In the last part of this article series, we’ll look at some of the methods used to measure model accuracy. And we’ll look at some of the challenges of implementing ML/DL in a production environment.

Roger E. Sanders is a Principal Sales Enablement & Skills Content Specialist at IBM. He has worked with Db2 (formerly DB2 for Linux, UNIX, and Windows) since it was first introduced on the IBM PC (1991) and is the author of 26 books on relational database technology (25 on Db2; one on ODBC). For 10 years he authored the “Distributed DBA” column in IBM Data Magazine, and he has written articles for publications like Certification Magazine, Database Trends and Applications, and IDUG Solutions Journal (the official magazine of the International Db2 User's Group), as well as tutorials and articles for IBM's developerWorks website. In 2019, he edited the manuscript and prepared illustrations for the book “Artificial Intelligence, Evolution and Revolution” by Steven Astorino, Mark Simmonds, and Dr. Jean-Francois Puget.
From 2008 to 2015, Roger was recognized as an IBM Champion for his contributions to the IBM Data Management community; in 2012 he was recognized as an IBM developerWorks Master Author, Level 2 (for his contributions to the IBM developerWorks community); and, in 2021 he was recognized as an IBM Redbooks Platinum Author. He lives in Fuquay Varina, North Carolina.
MC Press books written by Roger E. Sanders available now on the MC Press Bookstore.
 |
QuickStart Guide to Db2 Development with Python Discover how Python, SQL, and Db2 can successfully be used with each other. List Price $9.95 Now On Sale
|
|
 |
DB2 10.5 Fundamentals for LUW (Exam 615) Don't even think about attempting to take the DB2 Fundamentals exam without this indispensable study guide. Now On Sale
|
|
 |
DB2 10.1 Fundamentals (Exam 610) Let one of the world's leading DB2 authors and a participant in the exam development help you succeed. List Price $79.95 Now On Sale
|
|
 |
Artificial Intelligence: Evolution and Revolution Operational AI has become available to the masses, setting the wheels in motion for a worldwide AI revolution that has never been seen before. Now On Sale
|
|
 |
DB2 10.5 DBA for LUW Upgrade from DB2 10.1: Certification Study Notes Here's everything you need to know to take and pass Exam 311, complete with a practice exam and study key. List Price $21.95 Now On Sale
|
|
 |
From Idea to Print Here's everything you need to know to turn your technical knowledge and expertise into a published article or book. Now On Sale
|
|
|
DB2 9 Fundamentals (Exam 730) Use this review before taking the test to prove you've mastered the basics of DB2 9. List Price $59.95 Now On Sale
|
|
 |
DB2 9 for Linux, UNIX, and Windows Database Administration (Exam 731) Use this indispensable study guide to prepare to take, and pass, Exam 731. Now On Sale
|
|
 |
DB2 9.7 for Linux, UNIX, and Windows Database Administration (Exam 541) Get ready to take the DB2 9.7 certification exam with this handy study guide. List Price $21.95 Now On Sale
|
|
 |
DB2 9 for Linux, UNIX, and Windows Advanced Database Administration (Exam 734) Review all exam topics and take the included practice test to be sure you're ready on testing day. Now On Sale
|
|
 |
DB2 9 for Linux, UNIX, and Windows Database Administration Upgrade (Exam 736) Prep for success with the master of DB2 certification study guides! List Price $34.95 Now On Sale
|
|
 |
Data Fabric: An Intelligent Data Architecture for AI This book explains the concepts and values that a data fabric approach can deliver to both technical and business communities. Now On Sale
|
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online