








Linux, an open-source implementation of UNIX, is rapidly gaining
acceptance among IBM eServer iSeries users. With the V5R2 enhancements, Linux
for 64-bit PowerPC can run natively in up to 31 separate logical partitions
(LPARs). Traditionally, the iSeries server is used by many organizations as a
reliable and highly scalable database server. The iSeries database, DB2
Universal Database (UDB) for iSeries is fully integrated in OS/400 and exploits
its robust features, such as single-level storage, tight security, and
object-based architecture. For these reasons, we at IBM believe that DB2 UDB for
iSeries will remain the database of choice for many iSeries shops.
Generally, Linux applications can use three programming environments to
access the iSeries database: ODBC, JDBC, and DB2 Connect gateway. This article
provides implementation tips and coding examples that illustrate how to optimize
the access to your DB2 UDB for iSeries database from a Linux partition by using
various JDBC drivers.
Currently, IBM offers several Power PC
Linux-enabled JDBC drivers that support DB2 UDB for iSeries:
- Type 4 drivers--IBM Toolbox for Java & JTOpen, and DB2 Universal JDBC Driver
- Type 2 driver--DB2 JDBC Type 2 Driver
The IBM Toolbox for
Java iSeries driver has been implemented in pure Java and optimized for
accessing DB2 for iSeries data. It uses native iSeries protocol to communicate
with the back-end database server job. JTOpen is the open-source version of the
IBM Toolbox for Java Licensed Program Product (LPP).
The DB2 Universal
JDBC Driver is also a pure Java implementation. It is a part of the DB2 UDB
Version 8 for Linux product, and it uses the Distributed Relational Database
Architecture (DRDA) protocol for client/server communications. The driver is
compatible with various DB2 server platforms with appropriate DRDA Application
Server (AS) level support and prerequisite stored procedures. It also supports
Type 2 connectivity when accessing DB2 for Linux, UNIX, and Windows (DB2 LUW)
databases.
The traditional DB2 JDBC Type 2 Driver is built on top of DB2
Call Level Interface (CLI). It requires DB2 Connect functionality to access DB2
UDB for iSeries. This is a legacy driver, and IBM currently recommends that the
DB2 Universal JDBC driver is used instead.
Disclaimer:
The performance information in this document is for guidance only.
System performance depends on many factors, including system hardware, system
and user software, and user application characteristics. Customer applications
must be carefully evaluated before estimating performance. IBM does not warrant
or represent that a user can or will achieve a similar performance. No warranty
on system performance or price/ performance is expressed or implied in this
document.
Initial Configuration Considerations
Practical experience shows that the JDBC application performance greatly depends on the programming techniques and the SQL access tuning. However, significant performance gains can be achieved by simply "tweaking" the Linux partition environment. In this section, I look at two configuration options: Java Runtime Environment (JRE) and virtual versus physical LAN.
Java Runtime Environment
Although JRE is usually
pre-installed in a Linux partition, I strongly recommend that you download the latest IBM
SDK for 64-bit iSeries/pSeries from the IBM Java
support site. The JRE implements the state-of-the-art Just-In-Time (JIT)
compiler that can dramatically improve performance of a Java application, as
illustrated in Figures 1 and 2. In both cases, a simple Java program was
executed in a loop.

Figure 1: Blackdown JRE, No JIT (Click images to enlarge.)

Figure 2: IBM build JRE, JIT-enabled
Virtual Versus Physical LAN
One of the most
significant benefits of installing Linux in an iSeries partition is the ability
to utilize virtual LAN and virtual DASD. This usually results in reduced
hardware costs through improvements in data transfer performance and enhanced
disk protection. The performance tests conducted by the Solutions Enablement
team showed that the Virtual 1Gb LAN delivered a data throughput similar to
dedicated 1Gb Ethernet adapters (model #2743) connected via a point-to-point
multimode fiber. The test configuration is illustrated in Figure 3.
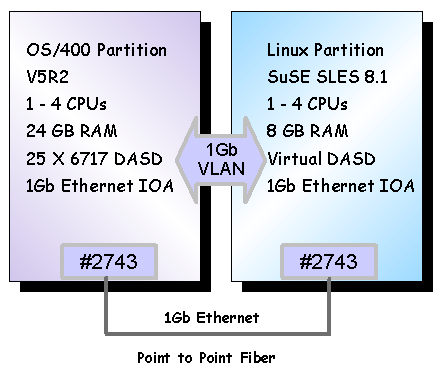
Figure 3: VLAN vs. 1 Gb Ethernet IOA configuration
Figure 4
shows the test results measured for a sample Java application.

Figure 4: VLAN vs. 1 Gb Ethernet IOA throughput
Other real-life
database access scenarios tested for existing Independent Software Vendor (ISV)
solutions show that you can expect similar performance for VLAN and 1Gb Ethernet
(#2743).The VLAN configuration, however, has two advantages over the physical
LAN connection:
- No additional communications gear is required.
- It is a dedicated point-to-point connection, so there is no interference from other devices on the same network segment.
On the other hand, certain application scenarios may benefit from a physical LAN adapter dedicated to a Linux partition. For instance, in a three-tier application architecture, clients connect to an application server running in a Linux partition. The application server, in turn, connects to the DB2 for iSeries to store and retrieve data. In this case, configuring a separate physical LAN connection in a Linux partition has the following advantages:
- An unnecessary additional hop is eliminated from the network route.
- Client-application server traffic does not unnecessarily saturate OS/400 communications gear.
Tuning DB2 for iSeries Access with IBM Toolbox for Java and JTOpen Driver
This section covers JDBC
implementation details for a sample Java program called
TestJDBC. The application uses the
Java Naming and Directory Interface (JNDI) to obtain a database connection,
deletes 5,000 records, then generates and inserts 5,000 records, and finally
retrieves the newly inserted records from an SQL table called COFFEES. The
application executes in a Linux partition and accesses the DB2 for iSeries
through the JTOpen (or IBM Toolbox for Java) driver. Figure 5 shows the software
components involved in the execution of this simple application.
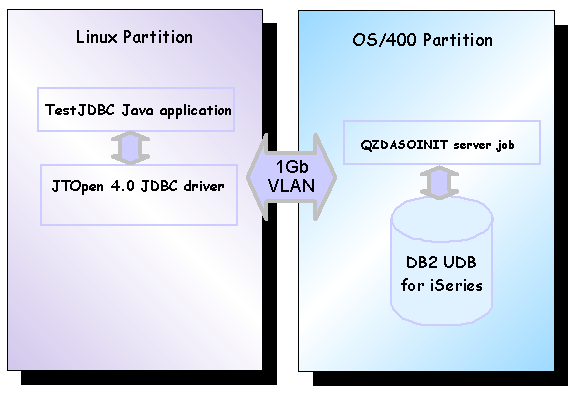
Figure 5: JDBC client accessing DB2 UDB for iSeries
Apart from the JTOpen driver, which can be downloaded
from the IBM Toolbox for Java Web site, you need three other JAR files to
successfully compile and execute the JDBCTest application in a Linux
partition:
- providerutil.jar and fscontext.jar--Download a simple file system JNDI provider from Sun Microsystems' JNDI Web site.
- jdbc2_0-stdext.jar--Copy the javax.sql package from the /QIBM/UserData/Java400/ext IFS directory on the iSeries server.
The location of the JAR files needs to be added to the
CLASSPATH environment variable. For instance, the following entry could be added
to the Linux .profile script:
CLASSPATH=$CLASSPATH:/home/code/fscontext/providerutil.jar
CLASSPATH=$CLASSPATH:/home/code/fscontext/fscontext.jar
CLASSPATH=$CLASSPATH:/home/code/JTOpen/jdbc2_0-stdext.jar
export CLASSPATH
To compile the source, use the following command in the Linux
partition:
javac
TestJDBC.java
Although the TestJDBC application is fairly
simple, it illustrates several important aspects of efficient JDBC programming
for DB2 UDB for iSeries.
Connection Pooling
A JDBC connection can be obtained through either the
DataSource or DriverManager object. Either method involves significant overhead.
A fairly large amount of system resources is required to create the connection,
maintain it, and then release it when it is no longer needed. JTOpen allows you
to establish a pool of database connections that can be shared by multiple
client applications. Connection pooling can improve the response time because
the connection pool manager can locate and use an existing connection. When the
database request is completed, the connection returns to the connection pool for
reuse.
In the JDBCTest sample, I first used JNDI to register a
connection pool-capable data source. Here's an excerpt from the deployDataSource
method of the sample application:
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY,
"com.sun.jndi.fscontext.RefFSContextFactory");
Context ctx = new InitialContext(env); [1]
// Register an AS400JDBCConnectionPoolDataSource object.
AS400JDBCConnectionPoolDataSource tkcpds = new
AS400JDBCConnectionPoolDataSource(); [2]
tkcpds.setServerName(serverName) ;
tkcpds.setDatabaseName(databaseName) ;
tkcpds.setUser(userName) ;
tkcpds.setPassword(password) ;
tkcpds.setDescription("Toolkit Connection Pooling DataSource object");
...
ctx.rebind("jdbc/ToolkitDataSource", tkcpds); [3]
At [1], the initial JNDI context is created.
Then at [2], an
AS400JDBCConnectionPoolDataSource object is instantiated. This is the JTOpen
implementation of the javax.sql.ConnectionPoolDataSource interface. An
AS400JDBCConnectionPoolDataSource object supports a number of methods that you
can use to set iSeries-specific properties of the underlying DataSource object.
I'll discuss some of these properties in greater detail in the following
sections.
At [3], the data source object is bound to an arbitrary name
that will be used in the main application. Note that the deployDataSource method
needs to be executed just once unless you want to change some of the data source
properties. In that case, you'd need to rebind.
The JNDI registered data
source is then used in the main application to initialize the connection
pool:
(AS400JDBCConnectionPoolDataSource)ctx.lookup("jdbc/ToolkitDataSource");
// Create an AS400JDBCConnectionPool object.
AS400JDBCConnectionPool pool = new AS400JDBCConnectionPool(tkcpds);[2]
// Adds 1 connection to the pool that can be used by the application
//(creates the physical database connections based on the data source).
pool.fill(1); [3]
...
con = pool.getConnection();[4]
At [1], the JNDI service is used to instantiate the
AS400JDBCConnectionPoolDataSource.
Then at [2], an
AS400JDBCConnectionPool object is created. This object is responsible for
managing the connection pool.
At [3], the connection pool is initialized
with one connection.
The pool object is used at [4] to obtain a database
connection. There are several additional things you should know about this code
snippet:
- The advantage of using JNDI to register the data source object as opposed to just instantiating it in the main method is that in a more realistic scenario the data source would be registered just once at application deployment time. Additionally, the data source properties do not have to be hard-coded in the main method and can be changed at any time and then rebound without affecting the application.
- The AS400JDBCConnectionPool is a proprietary JTOpen implementation of a connection pool. Specifically, it does not implement the Referenceable interface and thus cannot be bound through JNDI services.
- The JTOpen AS400JDBCConnectionPoolDataSource does not support statement caching as described in the JDBC 3.0 specification. Statement caching is implemented through SQL packages. This feature is covered in the following section.
Note: The native iSeries JDBC driver supports
both connection pooling and statement caching in a JDBC 3.0 compliant
manner.
Extended Dynamic SQL and Statement Caching
As mentioned, the JTOpen data source object supports
a number of properties that can be used to fine-tune the database performance.
In this section, I discuss properties used to enable extended dynamic SQL
support and local statement caching. Here's a relevant code excerpt from the
deployDataSource method:
AS400JDBCConnectionPoolDataSource tkcpds = new
AS400JDBCConnectionPoolDataSource();
...
tkcpds.setExtendedDynamic(true);[1]
tkcpds.setPackage("JDBCDS"); [2]
tkcpds.setPackageCache(true); [3]
tkcpds.setPackageCriteria("select"); [4]
At [1], the extended dynamic SQL support is enabled. Note that the
default is disabled for JTOpen. The extended dynamic SQL functionality is often
referred to as SQL package support. The SQL packages are server-side
repositories for SQL statements. Packages contain the internal structures--such
as parse trees and access plans--needed to execute SQL statements. Because SQL
packages are a shared resource, the information built when a statement is
prepared is available to all the users of the package. This saves processing
time, especially in an environment where many users are using the same or
similar statements. Because SQL packages are permanent, this information is also
saved across job initiation/termination and across IPLs. In fact, SQL packages
can be saved and restored on other systems.
At [2], the SQL package is
named. Note that the actual package name on the iSeries is JDBCDSBAA. The
package name is generated by taking the name specified on the client and
appending three letters that are an encoded set of the package configuration
attributes. By default, an SQL package does not contain unparameterized select
statements. This behavior is overridden at [4] by setting the PackageCriteria
property to "select".
At [3], the local statement cache is enabled. A
copy of the SQL package is cached on the Linux client. This may improve
application performance in a way similar to JDBC 3.0 statement caching. Note,
however, that local statement caching is not recommended for large SQL packages.
The copy of an SQL package is cached when the database connection is obtained.
This may cause increased network traffic as well as slow down the connection
setup time.
Reusable Open Data Paths (ODPs)
An ODP definition is an internal OS/400 object that
is created when certain SQL statements (such as OPEN, INSERT, UPDATE, and
DELETE) are executed for the first time in a given job (or connection). An ODP
provides a direct link to the data so that I/O operations can occur. The process
of creating new ODP objects is fairly CPU- and IO-intensive, so whenever
possible, the iSeries DB2 runtime tries to reuse existing ODPs. For instance, a
ResultSet.close() call may close the SQL cursor but leave the ODP available to
be used the next time the cursor is opened. This can significantly reduce the
response time in running SQL statements. A reusable OPD usually requires 10 to
20 times less CPU resources than a newly created ODP. Therefore, it is important
that the applications employ programming techniques that allow the DB2 runtime
to reuse ODPs.
With dynamic programming interfaces, such as JDBC, the
most efficient way to avoid full opens is to employ the so-called "prepare once,
execute many" programming paradigm. Ideally, an SQL statement that is executed
more than once should be prepared just once--for example, in the class
constructor--and then reused for the consecutive executions. At the prepare
time, the DB2 engine stores the prepared statement along with the associated
statement name in the QZDASOINIT job's statement cache. On first execution, the
ODP created for a given statement gets associated with the appropriate entry in
the statement cache. On consecutive executions, the prepared statement and the
corresponding ODP can be quickly located in the statement cache and reused. The
code snippet below illustrates the "prepare once, execute many" programming
technique:
...
for (int i = 0; i < outerNumOfLoops; i++) {
// insert
for (int j = 0; j < numOfLoops; j++) {
pstmt.setString(1, "Lavaza_" + Integer.toString(j));
...
pstmt.addBatch();
}
int [] updateCounts = pstmt.executeBatch();[2]
con.commit();
}
At [1], a PreparedSatement pstmt object is instantiated for a
parameterized INSERT statement. The statement is prepared just once. The
PreparedSatement object is then repeatedly used at [2] to perform blocked
insert.
Block Inserts
Occasionally, you may need to initially populate a
table or insert a modified result set into a temporary table. The efficiency of
the insert operation for a large set of records can be dramatically improved by
using the executeBatch method rather than the executeUpdate method. The JTOpen
driver converts parameterized insert statements in an executeBatch method to a
block insert statement. This significantly reduces the data flow and system
resources required to perform the insert. The following code snippet shows how
to take advantage of the executeBatch method:
con.prepareStatement("INSERT INTO COFFEES VALUES( ?, ?, ?, ?, ?)"); [1]
for (int j = 0; j < numOfLoops; j++) {
pstmt.setString(1, "Lavaza_" + Integer.toString(j));
pstmt.setInt(2, i);
pstmt.setFloat(3, 4.99f);
pstmt.setInt(4, 0);
pstmt.setInt(5, 0);
pstmt.addBatch(); [2]
}
int [] updateCounts = pstmt.executeBatch(); [3]
At [1], a parameterized insert statement is prepared. Note that all
columns must be parameterized. Otherwise, the executeBatch method may throw the
SQL0221 "Number of rows 1 not valid" exception. In other words, you should not
mix parameter markers with literals or special registers in the VALUE clause.
At [2], the addBatch method is used to add a new record to the client
record buffer.
At [3], all locally buffered data is sent to the server,
which, in turn, performs a block insert.
Figure 6 shows the performance
data for the executeBatch and executeUpdate methods.
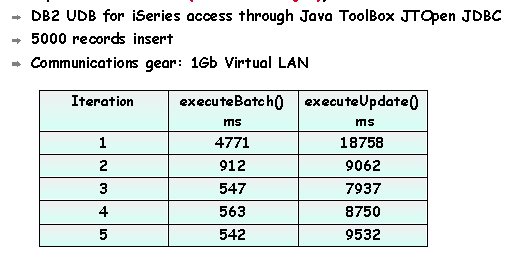
Figure 6: executeBatch() vs. executeUpdate() performance comparison
Massive Delete
Sometimes an application needs to delete all records
from a given table to clean up a log or reload sales data for a new month. In
these cases, we strongly recommend that you use the native CLRPFM command rather
than the SQL DELETE statement. The DELETE statement would need to mark every
record as deleted and thus would require a substantial amount of I/O operations.
Additionally, the consecutive INSERT operations would potentially be slower
because the DB2 engine would try to reuse the deleted records first. This code
sample illustrates how to call a native CLRPFM command from a Java
client:
cstm.executeUpdate();
cstm.close();
At [1], the system stored procedure QCMDEXC is called with two
parameters. The first parameter contains the native command to be executed on
the iSeries. The second parameter contains the length of the command text in the
DECIMAL(15,5) format.
Figure 7 compares the performance of CLRPFM to SQL
DELETE. In both cases, the Delete All Records operation is followed by block
insert of 5,000 records.

Figure 7: CLRPFM vs. DELETE performance comparison
Troubleshooting
Troubleshooting a multi-tier application may be a bit tricky because the developer needs to deal with software components that reside in separate partitions. Two tools are particularly useful for pinning down the potential problem areas:
- The joblog messages for a database server job usually provide enough details to isolate DB2 UDB for iSeries runtime issues.
- The JDBC trace utility provides granular information about the data flow between the Linux application and the iSeries server job.
Job Log Messages
As mentioned, a DB2
client communicates with a corresponding iSeries server job. This server job
runs the SQL requests on behalf of the client. The iSeries database server jobs
are called QZDASOINIT, and they run in the QUSRWRK subsystem. At any given time,
a large number of database server jobs may be active on the system, so the first
step is to identify the job that serves the particular client connection. The
easiest method to accomplish this task is to run the following CL command from
the OS/400 prompt:
Here, DB2USER is the user profile that is used to connect to the iSeries
server. Note that a QZDASONIT job is assigned to a client after the connection
has been established, so the developer needs to set a breakpoint in the client
application after the database connection has been established.
Once the
Work with Object Locks appears, key in 5 (Work with Job) next to the only
QZDASOINIT job that should be listed. This shows the Work with Job dialog.
Select option 10 to display the job log for the database server job. Now, you
can search the job log for any error messages generated by the DB2 runtime.
Sometimes, it is also useful to include debug messages in the job log.
The debug messages are informational messages written to the job log about the
implementation of a query. They describe query implementation methods such as
use of indexes, join order, ODP implementation (reusable versus non-reusable),
and so on. The easiest way to instruct the iSeries server to include the debug
messages is to set the ServerTraceCategories property on the data source
object:
AS400JDBCDataSource.SERVER_TRACE_DEBUG_SERVER_JOB);
A sample of the job log messages with debug messages enabled is shown
below:
STATEMENT NAME FOUND : QZ868F0A458E13AF8C.
**** Starting optimizer debug message for query .
Arrival sequence access was used for file COFFEES.
ODP created.
ODP not deleted.
5000 rows inserted in COFFEES in DB2USER.
STATEMENT NAME FOUND : QZ868F0A4C144BF12E.
Blocking used for query.
Cursor CRSR0001 opened.
606 rows fetched from cursor CRSR0001.
ODP not deleted.
Cursor CRSR0001 closed.
So the job log offers fairly detailed information on how the Linux client
requests were implemented by the DB2 runtime.
JDBC Trace Utility
The JTOpen driver
provides a tracing utility, which can be used to collect detailed client-side
traces. The JDBC tracing is turned off by default. It can be enabled by setting
the Trace property to true. Here's an example of how to switch on tracing using
the setTrace method on the data source object:
The trace can also be enabled when using the
DriverManager.getConnection() method for obtaining a connection to DB2 on
iSeries. In this case, you could add the trace property to the connection
string. This approach is illustrated in the following code snippet:
...
con = DriverManager.getConnection("jdbc:as400://teraplex;trace=true;",
"db2user","db2pwd"); [2]
At [1], an instance of the JTOpen JDBC Driver is initiated. Then at [2],
the driver is used to obtain a connection to the iSeries. Note how the trace
property has been added to the database URL. Refer to the iSeries
Information Center documentation for a complete list of properties supported
by the JTOpen driver.
DB2 Universal Driver for SQLJ and JDBC
DB2 Universal Driver for SQLJ and JDBC is one of the
new features delivered with DB2 Version 8. DB2 Universal Driver has been
designed to eliminate the dependency on DB2 CLI runtime modules as well as to
enable direct Type 4 connectivity to DB2 for iSeries and DB2 for
z/OS.
The pure-Java (Type 4) remote connectivity is based on the DRDA
open distributed protocol for cross-platform access to DB2. DRDA defines the
rules, the protocols, and the semantics for accessing distributed data.
Applications can access data in a distributed relational environment by using
SQL statements. The iSeries DRDA application server implementation is based on
multiple connection-oriented server jobs running in the QSYSWRK subsystem. A
DRDA listener job (QRWTLSTN) listens for TCP connect requests on port 446. Once
an application requester connects to the listener job, the listener wakes up one
of the QRWTSRVR prestart jobs and assigns it to a given client connection. Any
further communication occurs directly between the client application and the
QRWTSRVR job. These concepts are illustrated in Figure 8.
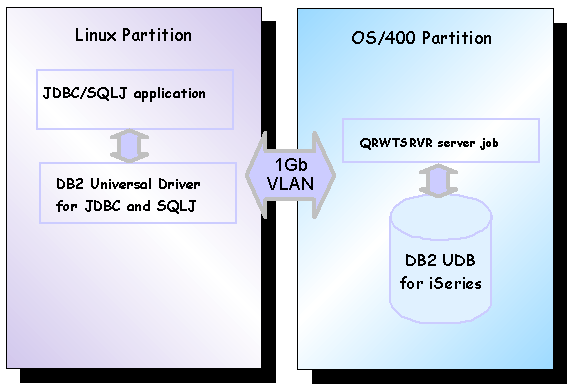
Figure 8: Accessing DB2 UDB for iSeries with DB2 Universal
Driver
The DB2 Universal Driver can be loaded in a Linux partition by
installing one of the DB2 Connect for Linux products (see the Additional
Information section for details). It is also a part of a DB2 Enterprise Server
Edition for PowerPC Linux install. Specifically, you need three JAR files in a
Linux partition to successfully connect to the iSeries: db2jcc.jar,
db2jcc_license_cisuz.jar, and db2jcc_license_cu.jar. The iSeries license is
contained in db2jcc_license_cisuz.jar. Note that this file is not a part
of DB2 Client. In other words, a DB2 Connect license is required to use the
driver in production environments. The location of the JAR files needs to be
added to the CLASSPATH environment variable. For instance, the following entry
could be added to the Linux .profile script:
CLASSPATH=$CLASSPATH:/home/db2inst2/sqllib/java/db2jcc_license_cu.jar
CLASSPATH=$CLASSPATH:/home/db2inst2/sqllib/java/db2jcc_license_cisuz.jar
export CLASSPATH
Java Runtime 1.3.1 is a prerequisite.
Additionally, you
should install the latest database group PTF (SF99501 for V5R1 or SF99502 for
V5R2) on the iSeries server. The Informational APAR ii13348 is keeping track of
any fixes relevant to DRDA above and beyond the current database group PTF.
Obtaining a Connection to DB2 UDB for iSeries
When Type 4 connectivity is used, the DB2 Universal
Driver connects directly to the DB2 on iSeries through TCP/IP. Note that this is
different from the legacy DB2 Type 2 JDBC driver that requires a DB2 node and
remote database configurations on the client accessing iSeries. The following
code snippet illustrates how to use the DB2 Universal Driver to obtain a
connection to DB2 UDB for iSeries:
Class.forName("com.ibm.db2.jcc.DB2Driver"); [1]
} catch(java.lang.ClassNotFoundException e) {
System.err.print("ClassNotFoundException: ");
System.err.println(e.getMessage());
}
try {
DriverManager.getConnection("jdbc:db2://teraplex:446/TERAPLEX", [2]
"db2user","db2pwd");
...
} catch(SQLException ex) {
System.err.println(
"SQLException: " + ex.getMessage());
}
At [1], an instance of the DB2 Universal Driver is initiated. Then at
[2], the driver is used to obtain a connection to the iSeries. Note the proper
form of the database URL required by the driver.
Considerations
There are several advantages of DB2 Universal Driver:
- Ease of cross-platform development--Consistent coding techniques and consistent error codes and messages
- Ease of deployment--Pure Java (no runtime client required) and a single driver for accessing DB2 on different platforms
The ease of use
comes at a price, though. The iSeries JTOpen driver is optimized for accessing
DB2 for iSeries data, and it uses native iSeries protocol to communicate with
the back-end database server job. This usually results in better performance and
more-efficient system resources utilization. For instance, when using the DB2
Universal JDBC Driver to access iSeries, the executeBatch method results in a
single record insert. There are also some restrictions when using DB2 Universal
JDBC Driver with Type 4 connectivity:
- Support for distributed transactions (JTA) is not enabled.
- Connection Pooling is not supported.
Refer to Java
application support in DB2 for more details on DB2 Universal JDBC
Driver.
Additional Information
The Using
DB2 Connect in an iSeries Linux Partition white paper published by
PartnerWorld for Developers contains a detailed discussion on accessing the
iSeries database through the DB2 Connect gateway.
ITSO offers two Redbooks that can be helpful to those
who want to learn more about OS/400 Linux integration:
- Linux Integration with OS/400 on the IBM eServer iSeries Server (SG24-6551)
- Linux on the IBM eServer iSeries Server: An Implementation Guide (SG24-6232)
Jarek
Miszczyk is the Senior Software Engineer, PartnerWorld for Developers, IBM
Rochester. He can be reached by email at

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online