















According to Gartner Group, system downtime can result from a variety of events, including planned maintenance, software system failure, hardware system failure, human error, network transmission failure, and natural disasters.
Today, customer care is king, and no excuse for complacency seems valid. As stewards of commerce, we are judged by our ability to provide exceptional levels of service to everyone we encounter. A big part of the care package is delivering uninterrupted access to core applications and data.
Even if our culture demands quick fixes for almost everything, there are no standard fallback strategies in the world of IT when it comes to ensuring availability. Small companies that use standalone PCs generally address availability issues when their system becomes unavailable, whereas larger shops usually have elaborate and steadfast procedures to ensure system accessibility. As far as the widely scalable IBM System i range of computers is concerned, recovery processes vary as greatly as the nature and size of the companies that use these machines.
System redundancy is the best way to insulate your system users from the painful effects of planned and unplanned downtime. High availability (HA) in the most elemental form requires a parallel image of a production server. Different degrees of HA address varying recovery requirements. The level of readiness you choose is often dictated by the magnitude of your worst-case financial loss. On the other hand, having excess capacity for recovery, given your circumstances, means you're paying for something you cannot use.
The perception of HA is changing. This shift in opinion is the result of mounting requirements for system resiliency caused by e-commerce and tighter integration between machines in the modern supply chain. Less than a decade ago, HA seemed like it was available only to those with hefty budgets, but since companies now measure downtime in minutes instead of hours, they are exploring ways to save money on the implementation and ongoing maintenance of HA rather than simply dismissing it as a luxury set aside for enterprise-class operations like Yahoo and eBay.
Some analysts delineate levels of HA with the language "improved availability" and "high availability." This distinction is determined by how much a solution leans toward "reactive" disaster recovery, which attempts only to ensure that the organization can, eventually, return to business after a disaster, or toward "proactive" continuous availability, which puts policies, procedures, and technologies in place to achieve near-zero downtime and near-zero data loss, regardless of the threat.
Floyd Piedad and Michael Hawkins, two experts in the field, parse varied states of availability with the following descriptors:
- Reliability—The ability to perform under stated conditions for a stated period of time
- Recoverability—The ability to easily bypass and recover from a component failure
- Serviceability—The ability to perform effective problem determination, diagnosis, and repair
- Manageability—The ability to create and maintain an environment that limits the negative impact people may have on the system
The Cost/Benefit of Availability
Imagine that varying degrees of capacity for business continuation reside on a continuum. As you move from left to right, you gradually become more proactive, delivering more sophistication into the solution. The approach that offers the highest level of availability at the far right side of the spectrum is continuous availability.
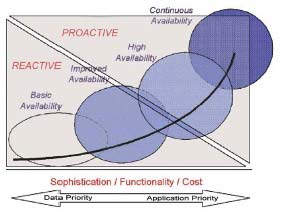
Figure 1: Progress from a reactive to a proactive approach to availability. (Click images to enlarge.)
The chart below provides the cost/benefit view, showing costs on the vertical axis and the percentage-degree of system availability on the horizontal axis. The red upward-curving line represents the total costs to a business when a system is unavailable. The blue upward-curving line represents the expense associated with deploying a system that achieves a certain degree of availability.

Figure 2 : The cost/benefit continuum compares costs to system availability.
This cost/benefit continuum chart starts with an assumed 95 percent availability and approaches 100 percent at the upper right. The cost associated with 95 percent availability is generally only slightly different from the total system baseline cost (hardware, software, services, etc.) because it is fairly inexpensive and simple to achieve 95 percent availability, which translates into roughly 36 hours of downtime per month.
Diminishing Returns
As we move toward the right side of this chart, system availability improves, but we also see an increase in the costs associated with obtaining an improved level of availability. As we approach 100 percent availability, the costs go almost vertical. This represents a continuous availability solution that tends to give equal priority to both data and applications. And it considers the availability of both to be absolutely vital.
The expense-cost differential (ECd), shown as the distance between the red and blue lines in the above chart, is the difference between the investment required to achieve a certain degree of availability and the cost to the business of system downtime. This ECd value, when coupled with potential lost-opportunity costs the organization may incur, can effectively show the organizational payback for investing in downtime protection. Essentially, almost any additional expenditure on availability that closes the gap between the blue line and the red line is justified by the recaptured costs of system unavailability. Finally, the "cost threshold," toward the upper-right corner of the chart, represents the point on the cost curve where it is better to let the company experience a certain degree of downtime than expend additional funds in an attempt to get closer to 100% availability.
Most organizations would, in the absence of other considerations, want their systems to be continuously available without exception, but as already noted, high availability comes at a cost. While newer products have made HA more accessible to SMBs with small to average IT budgets, the law of diminishing returns remains constant: As requirements and complexities escalate, so does the investment. Again the question is not whether it is better to mirror or not to mirror, but rather, how much availability your organization can cost justify.
To shed light on your recovery requirements, answer the following questions:
- How does planned or unplanned system downtime affect your operations, EDI trading partners, or operations in distant time zones?
- How will your business be hurt if your primary production system fails? Do other systems depend on or interact with this machine?
- What does an hour of downtime cost you, and how much downtime can you afford?
- What is your ability to recover or restore lost data?
- At what point do you decide not to pursue recovery? Does it make any sense to restore data-center operations if a key customer service center or warehouse is destroyed?
Your Availability Target
Once you understand the level of discomfort that your organization can tolerate, you should identify an "availability target." The availability target is the proposed amount of time the system would be available for productive user. The lost time per month and lost time per year columns in the table below show the amount of downtime that will occur if the Availability Target is exactly met. There are 8,760 hours in a 365-day year. For simplicity, all months have been assumed to have 30 days (720 hours).
| Availability Target | Lost Time/Month | Lost Time/Year |
| 95% | 36.0 hours | 438.0 hours (18 days) |
| 97% | 21.6 hours | 262.8 hours (10.8 days) |
| 98% | 14.4 hours | 175.2 hours (7.2 days) |
| 99% | 7.2 hours | 87.6 hours (3.6 days) |
| 99.5% | 3.6 hours | 43.8 hours (1.8 days) |
| 99.9% | 43 minutes | 8.8 hours |
| 99.99% | 4.3 minutes | 52.6 minutes |
| 99.999% | 26 seconds | 5.3 minutes |
| 99.9999% | 2.6 seconds | 31.5 seconds |
Data Versus Applications
Which of these two things does your worry about more, protecting data or ensuring accessibility to core business applications? By and large, IT managers and business executives tend to worry more about data protection. They know applications are important for operational continuity, but data integrity is their priority, since data is regarded as a key business asset that has tangible value.
Conversely, some people acknowledge the importance of data, but they focus on application availability, because operational continuity is vital to the health of their enterprise.
Those of us who place greater value on data are most sensitive to Recovery Point Objectives (RPO), which define a point in a data-transaction stream to which you need to recover information. Your RPO turns on the question of how much data you can afford to lose. The choice of high availability solution can have a major impact on how much data can be recovered—and recovered quickly—following a downtime event.
Now, let's weigh the argument for making application access a higher priority than data. Say, for instance, a manufacturer with global sales operates a 24x7 enterprise and ties customers, sales reps, and its supply chain into an e-business network. Data integrity is, of course, important to the enterprise, but round-the-clock manufacturing and shipping means company officials focus most on maintaining operational continuity and having no-exceptions access to related applications because a shutdown would seriously impact manufacturing, sales, distribution, and cash-flow. People who regard application access as the higher priority tend to be more sensitive to Recovery Time Objectives (RTO), which define how quickly an enterprise must recover failed applications.
The question behind RTO is how long your business can afford to be offline. Large, multi-divisional enterprises using powerful ERP solutions likely have an RTO of near zero. But even a smaller company may target a low RTO because of the impact any downtime may have on profitability. And, while different organizations have different focuses, RTO and RPO are not entirely mutually exclusive.
Basic data and object replication—In this scenario, a high availability solution replicates selected, business critical data updates as they are applied to the primary system, to an LPAR, or to a locally hosted backup server. It offers minimal duplicate coverage of secondary systems and peripherals. This strategy does not require offsite hosting or high bandwidth connectivity over an extended distance. In this instance, applications and data are safe and accessible unless a catastrophic event destroys the facility.
Full replication of data and objects to a remote processor and other redundant systems—The most robust high availability solution replicates all data updates to a backup server as they are applied to the primary system. This backup system is at a remote facility on a different power grid and has a backup power source. Failed landline communications can be immediately replaced with a satellite-based backup system. This strategy best supports business continuation
High availability can be achieved with third-party replication software that not only maintains a mirrored image of production data and applications on the backup server, but also facilitates seamless switching between the two environments. This facility should have two operating modes: manual and automatic. Manual switching is used when maintenance is required on the production server. Users can then be switched to the backup environment so they can continue their jobs unabated. Automatic switchovers, usually referred to as failovers, keep the business running during unexpected system stoppages such as those resulting from disasters, hardware failures, or power failures. To minimize downtime in these instances, availability software should be able to not only automatically switch users, but also detect when it is necessary to do so.
The Best Plan for Your Company?
The objective of any business continuity initiative is to harden the most business-critical processes and minimize planned and unplanned downtime. An effective business continuance plan must account for the requirements of the business and its systems. While the investment in HA is much like an investment in insurance, balancing the cost of HA with the benefits your business requires is the best approach to an effective strategy.
Alan Arnold is the EVP and CTO for Vision Solutions and is responsible for the global technology and services strategy for the business. Alan joined Vision in 2000, and since joining the company, he has served in a variety of positions, including EVP of Technologies, President, and Chief Operating Officer of worldwide operations.



 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online